






[Oracle 11g r2(11.2.0.4.0)]集群守护进程CSS资源管理
2018-07-25 11:43:31Oracle
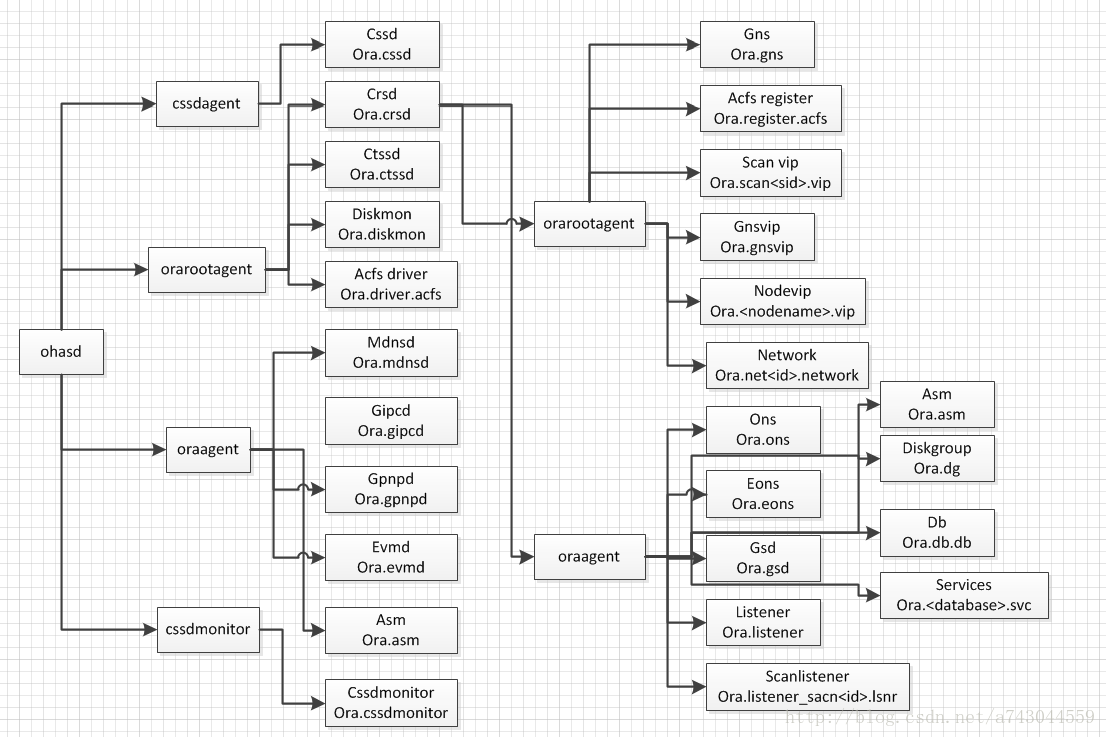
首先看一下11gr2 各个进程关系:
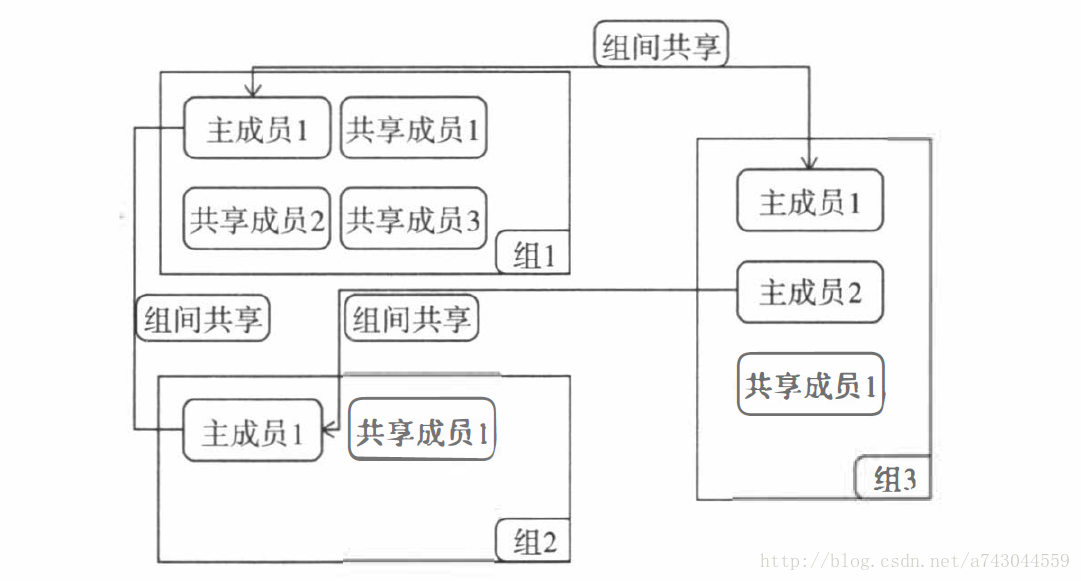
之前谈到的css功能可以统称为节点管理( Node Management)功能。接下来继续讨论css 的另一个重要的组成部分一一组管理(Grocl < IGroup Management)功能。
组管理主要完成两部分功能:
第一种是共享( Share);
第二种是隔离(Fencing)。
在一个集群中, 除了节点之外, 还有很多资源是需要管理的(当然, 主要的资源管理工作是由crsd.bin来完成的, 作者会在后面的章节介绍), 而这些资源会作为一个一个的组(在css 的世界里, 把组称为Grock) 注册到css 上, 每个组会由若干个成员构成, 而且每个组或者组中的一些成员都要向外共享一些信息。
例如, 集群中的每一个数据库都会作为一个组注册到css 上, 而这个组的主要成员就是LMON进程(这就是为什么读者会发现LMON进
程有的时候会报ora-29701错误的原因), 当LMON进程被启动的时候, 需要把自己注册到css 对应的组当中, 它才能够知道这个数据库同时有多少个实例在运行, 每个实例运行在哪一个节点上, 对于这种行为, 一般称为组内共享。
再举一个例子, 当ASM实例启动之后, 一些ASM实例的进程也会构成一个组并且把自己注册到css 上, 同时把自己的信息共享出去,以便数据库实例能够发现运行的ASM实例, 并进行通信, 对于这种行为, 称为组间共享。
下面对GM中涉及的一些概念进行介绍。
1 . 组(Group/Grock):一组成员(例如: OS进程, 也可能是同一个OS进程, 其中有多个能够独立进行物理ν0的线程)和它们的资源组成的整体。比较典型的例子是一个数据库中的一些服务器进程, 这些进程访问相同的数据库。组分为全局组(组成员来自于不同节点, 通过RPC通信)和本地组(组成员来自于同一个节点)。
2 . 成员( Memeber):能够被独立运行的一个实体, 例如: OS进程。也可能是同一个OS进程中能够独立进行物理VO的线程。成员分为主成员( Primary Member)和共享成员( Shared Member)。其中主成员负责监控集群并在其发生变化时进行相应的操作。共享成员是主成员的扩展。
3 . GM master:与NM类似, 当组中的某一个成员离开或者加入组的时候, 也会有一个master节点(一般称这个节点为GM master) 来完成组成员的重新配置。
组管理中另一个重要的功能就是隔离, 也就是说, 当组中的某一个成员离开的时候(例如:这个进程被中止掉), GM必须确保这个进程在OS级别已经离开, 而且进程正在执行的所有1/0操作都被清理掉, 并且不能有新的νo 产生, 因为对于集群来说, 需要在节点间保证VO的一致性, 这也是经常在很多文档当中讲到的只有能够独立运行物理ν0的进程才会注册到css 的原因之一。
接下来,介绍和ASM 、数据库相关的组,帮助理解ASM 是如何通过Grock 来和数据库进行互动的。
1 . 磁盘组全局组(Disk Group Group Global,DGGG):每个磁盘组都会有对应的DGGG,ASM 的GMON 进程会作为主成员注册进来。如果ASM 实例管理多个磁盘组,GMON会作为主成员注册到每个DGGG 中。
2 . 磁盘组本地组( Disk Group Group Local,DGGL ):每个磁盘组都会有对应的DGGL,数据库实例的RBAL 进程会作为主成员注册进来。同时这个组会和DGGG 的GMON成员进行信息共享,也就是组间共享。
3 . 数据库全局组( Database Group Global,DGG ):每个数据库都会有一个全局组,LMON 进程会做为主成员注册进来。
4 . 核心前端进程组( Umbilicus Forground Group,UFG ):这是个本地组,数据库实例的RBAL 和ASMB 进程会注册进来。
下面通过两个具体的例子( ASM 实例关闭和ASM 磁盘组被卸载),结合ocssd.log 、数据库alert.log 和ASM alert.log 来说明GM 部分是如何工作的。作者使用的集群版本是11.2.0.4,两个节点。
ASM实例关闭
首先,看一下ASM 资源的状态。(不要模仿)
ora.DATA.dg
ONLINE ONLINE *****
ONLINE ONLINE *****
ora.DATAl.dg
ONLINE ONLINE *****
ONLINE ONLINE *****
ora.asm
ONLINE ONLINE
ONLINE ONLINE
ASM实例+ASMI终止
$ sqlplus I as sysasm
SQL> shutdown abort
ASM instance shutdown
1.UFG 组
看一下ASM alert.log
*****
*****
Fri Oct 03 01:52:13 2014
Starting background process ASMB
Fri Oct 03 01:52:13 2014
ASMB started with pid=27,OS id=l3338
Fri Oct 03 01:52:13 2014
ASMB started with pid=27,OS id=l3338
Fri Oct 03 01:52:13 2014
NOTE: client +ASMl:+ASM registered,osid 13340,mbr OxO
Fri Oct 03 01:52:28 2014
NOTE: client orallgl:orallg registered,os工d 13434,mbr Oxl
Sat Oct 04 02:51:51 2014
Shutting down instance (abort)
License high water mark = 10
USER (ospid: 12637): terminating the instance
Instance terminated by USER,pid = 12637
Sat Oct 04 02:51:53 2014
Instance shutdown complete
可以看到实例被终止。接下来看一下对应节点的ocssd.log。
2014-10-04 02:51:51.823: [CSSD] [3027381136]c lss g m F e n c e C l i e n t: f e n c i n g
client(Ox98f7160),member(O) in group(U FG_+ASMl),d eath fence(l),SA GE
fence (0)
2014-10-04 02:51:51.823: [CSSD] [3027381136]cls s g mFen c ePro c e s sDeath: client
(Ox98f7160) pid 13340 undead
可以看到UFG组的一个成员被隔离。
2014-10-04 02:51:51.823: [CSSD] [3027381136]cls s gmDe s t royPro c: cleaning u p
proc (Ox970a9d0) con (Ox28425c3) skgp工d 13340 ospid 13340 with O clients,
refcount 0
2014-10-04 02:51:51.837: [C S S D) [3027381136)c l s s g mF en c e Cl i e n t: f e n cin g
client(Ox99lf5d 0),member (l) in group(UFG_+ASMl),death fence(l),S A GE
fence(O)
2014-10-04 02:51:51.837: [CSSD) [3027381136Jc ls sgmFenc ePr o c essDea th: c lient
(Ox99lf5d0) pid 13434 undead
2014-10-04 02:51:51.837: [C SSD) [3027381136Jc ls s g m Dest r o y Pr o c : cle a n i n g up
proc (Ox9924878) con(Ox2842el8) skgp i d 13434 osp i d 13434 with O clients,
ref count 0
2014-10-04 02 :51: 51. 838: [CSSD) [3012709264] clssgmFenceCom pletion: (Oxb 2d 70eb 0)
process death fence completed for process 13340,objec t type 3
2014-10-04 02:51:51.838: [CSSD] [3012709264]clssgmTer m Member: Ter m inating member
。(Ox9853698) in grock UFG +ASM l
UFG组成员被终止。
2014-10-04 02: 51: 51. 838: [CSSD] [ 30127092 64] clssgm U nreferenceMember: loc al grock
UFG +ASM l member O ref count is 0
2014-10-04 02:51:51.838: [CSSD] [3012709264Jclssgm RemoveMember : grock UFG一+ASMl,
member number O (Ox9853698) node number 1 state OxO grock type
UFG组成员在组中被删除。
2.磁盘组(DG)
2014-10-04 02:51:51.864: [CSSD] [3027381136JclssgmFenceProcessDe ath: client
(Ox97d4930) pid 13195 undead
该进程为ASM实例的GMON进程
2014-10-04 02: 51: 51. 864: [CSSD) [3027381136] clssgmQueueFenceFor Check: (Oxb 2d 41ab 8)
Death c heck for objec t type 3,pid 13195
2014-10-04 02:51:51.864: [CSSD] [3027381136]clssgmFence Client: fencing
client(Ox993le78),member (l) ingroup(DG_DATAl),deathfence(l),SAGE fence(O)
2014-10-04 02:51:51.864: [CSSD] [3027381136]clssgm U nreferenceMember : glob al grock DG DATAl member 1 ref count is 4
2014-10-04 02:51:51.893: [CSSD] [3027381136]clssgmFence Client: fencing
client (Ox979d aa0),member (1) in group (DG一DATAl),same group sha re,SAGE fence(O)
2014-10-04 02: 51: 51. 894: [CSSD] (3012709264] clssgmFenceCompletion: (Oxb 2d 70a40)
process death fence completed for process 13195,objec t type 3
2014-10-04 02:51:51.894: [CSSDJ [3012709264)clssgmTer m Member: Ter m inating member1 (Ox993lf 28)ingrock DG_DATAl
2014-10-04 02:51:55.167: [CSSDJ [3011132304]clssgmHandleGrockR c f gU pd ate: grock(DG_DATAl),upd ateseq(52),status(O),send resp(1)
由于这是个全局组, 这意味着这个组的成员会来自于多个节点, 所以当其中一个节点的主成员离开时, GM 层面也要进行重新配置, 因此需要看一下另外一个节点发生了什么。以下是另一个节点对应的ocssd.log 中的内容。
2014 10-04 02:51:02.652: [CSSD] [ 3010345872]clss gmBroa d cas tGrockR cf gCmpl:
RPC(Ox38d002a) of g rock(D G D A T Al ) r e c eiv e d all a c k s,g rock u p da t e
sequ ence( 51)
2014-10-04 02: 51: 05. 920: [CSSD] (3010345872) clssgmR emoveMember: grock DG_DATAl,
member number 1 (Oxb2cb5a28) node n umber 1 state Oxl grock type 2
2014-10-04 02:51:05.920: [CSSD] (3010345日72JclssgmQu e u eGrock Event: groupName(DG一
DATAl) count( 1) master( 0) e vent( 1),incarn 52,mbrc 1,to member 0,e vents
Ox4,state OxO
2014-10-04 02:51:05.923: [CSSDJ [3010345872)clssgmBroa dcastGrockR cfgCmpl:
RPC(Ox3a6002a) of g rock(D G_D A T Al) r e c e i v e d all a ck s,g rock u p da t e
sequ ence(S2)
3 磁盘组(DG)本地grock
2014-10-04 02:51:55.159: [CSSD] [3027381136]clss gmFence Client:fencing
client( Ox9972cd0),member( 0) in group( DG一LOCAL_DATAl),SAGE fence(O)
2014-10-04 02 51:55.159: [CSSD ) [3027381136]clssgmUnreferenceMember: local grock
DG LOCAL DATAl member O refcount is 1
2014-10-04 02:51:55.159: [CSSD] [ 3027381136JclssgmFe nceP roc e ssD e ath: client (Ox9972cd0) pid 13428 undead
该进程为数据库实例的RBAL进程。
4.数据库全局组
2014-10-04 02:51 55.116: [CSSD] [3027381136Jclss gmFence
Client: fencing client(Ox998bc40),m ember(O) in group(DB O RAllG),de ath fen ce(l),SAGE fence(O)
2014-10 04 02: 51: 55 .116: [CSSD ) [ 3027381136] clssgmUnreferenceMember: global grock
DBORAllG member O refcount is 2
2014-10 04 02:51:55.116: [CSSD] [ 3027381136]clss gmFenceProce ssD eath: client (Ox998bc40) pid 13400 undead
该进程为数据库实例LMON进程。
2014-10-04 02:51:55.119: [CSSD) [3011132304]clssgmHandle GrockRcfg Update :
grock(DBORAllG),updateseq( 9),sendresp( 1 )
由于数据库全局组的成员来自于多个节点, 所以当一个节点的主成员离开时, 另外的节点也会进行相应的操作。
以下是另一个节点的ocssd.log
2014-10-04 02:51:05.875: [CSSD] [ 3010345872]clssgmBroa d cas tGrockRcf gCmpl:
RPC(Ox3a2002a) of grock(DBORAllG) re ceive d all acks,grock update sequence( 9)
2014-10-04 02:51:05.919: [CSSDJ [3010345872JclssgmRemoveMember: grock DB0RA11G,
member n umber O (Oxb4acbbb8) node n umber 1 state Oxl grock type 2
2014-10-04 02:51:05.920: [CSSD) [3010345872Jc l s s g m Q u e u e Grock Event:
groupName(DBORAllG) count(l) master(l) event(l),i ncarn 10,to member 1,events Ox68,state OxO
2014-10-04 02:51:05.923: [CSSD) [3010345872)clssgm Broad cast GrockRcfgCrnpl:
RP C(Ox3a4002a) of grock(D B O R AllG) receivedallacks,grock u p date sequence(lO)
能看到数据库组和ASMDG 组发生的事情基本都是类似的。
ASM磁盘组被卸载
将磁盘组DATA 在节点1 卸载。
[grid@***** t race]$ s r vctl stop diskgroup -g DATA -n ***** -f
看一下ASM 的alert.log 中的信息。
Mon Oct 06 09:01:35 2014
GMON started with pid=19,OS i d=4174
这是启动ASM 实例时GMON 的信息, Orac le进程id 是19,ospid=4174 , 列出它是为了在下面的日志中便于解释。
Thu Oct 09 15:17:52 2014
SQL> ALTER DISK GROUP DATA DISMOU NT FORCE /* asrn agent *//* {1:33337:14668) */
由于使用了srvctl 命令来卸载磁盘组, 所以我们能看到alter diskgroup 命令是由agent 发出的。
NOTE: cache dismounting ( not clea n) group 2/0xF449BBDE (DATA)
NOTE: messaging CKPT to quiesce pins Unix p rocess pid: 4245,image: oracle@*****.cn.oracle.com (TNS Vl-V3)
Thu Oct 09 15:17:52 2014
NOTE: halting all I/Os to diskgroup 2 (DATA)
Thu Oct 09 15:17:55 2014
GMON dismounting group 2 at 7 for pid 24,osid 4245
看起来GMON 卸载了磁盘组, 这个是正常的。
NOTE: Disk OCR in mode Ox7f ma rked for de-assignment
SUCCESS: diskgroup DATA was dismounted
磁盘组卸载成功。再来看一下本地节点ocssd.log信息:
2014-10-06 09: 01: 38. 4 80: [CSSD] [ 3027 381136 J clssgmClientConnectMsg: Connect from con (Ox33d347e) proc (Ox9849f00) pid (4174/4174) version 11:2: 1 :4,properties: 1,2,3,4,5
能看到GMON 在css 的GM 层面的信息, 而且能看到时间点和之前的ASM alert. log 也是一样的。
2014- 1 0 - 0 6 0 9 : 0 1 : 3 9 . 8 6 9 : [ C S S D] [ 3 0 2 7 3 8 1 1 3 6 ] c l s s g mRe g i s t e r C l i e n t:
proc(19/0x9849f00),client(2/0x96e0ef0)
GMON注册到一个grock中。
2014-10-06 09:01:39.870: [CSSDJ [3027381136JclssgmJoinGrock: global grock DG DATAl new client Ox96e0ef0 with con Ox33d3738,requested num -1,flags Ox40000000
2014-10-06 09: 01: 39. 870: [CSSDJ (3027381136] clssgmAddGroc灿1ember: adding member to grock DG_DATAl
这是对应的磁盘组的grock.
2014- 1 0 - 0 6 0 9 : 0 1 : 3 9 . 9 1 6 : [ C S S D] [ 3 0 2 7 3 8 1 1 3 6 ] c l s s g mRe g i s t e r C l i e n t :
proc(19/0x9849f00),client(3/0x99ld010)
GMON注册到另外一个grock中。
2014-10-06 09:01:39.916: [CSSD] [3027381136JclssgmJoinGrock: global grock DG DATA
new client Ox991d010 with con Ox33d37c8,flags Ox40000000
2014-10-06 09:01:39.916: [CSSD] [3027381136]clssgmAddGrockMember: adding member to
grock DG一DATA
2014-10-09 15:17:55.422: [CSSD] [3027381136]clssgmExitGrock: client 3 (Ox991d010),
grock DG DATA,member 1
在磁盘组DATA 被dismount 后, 对应组的主成员需要退出。
2014-10-09 15:17:55.422: [CSSD] [3027381136Jclssgm Unregister Primary: Unregistering
member 1 (Ox99ld0c0) in global grock DG DATA
2014-10-09 15:17:55.422: [CSSD] [3027381136]clssgmAllocateRPCindex: allocated rpc
620 (Oxb48a8f48)
2014-10-09 15:17:55.422: [CSSD] [3027381136]clssgmRPC: rpc Oxb48a8f48 (RPC#620)
tag(26c002a) sent to node 2
由于这是个全局组, 所以需要和远程节点通信。
2014-10-09 15:17:55.422: [CSSD] [3027381136JclssgmUnreferenceMember: global grock
DG DATA member 1 refcount is 1
2014-10-09 15:17:55.426: [C S S D] [3011132304]c l s s g m T e s t S e tLa s t G r o c k U p d a t e:
grock(DG DATA),updateseq(52) msgseq(53),lastupdt,ignoreseq(O)
2014-10-09 15:17:55.427: [C S S DJ [3011132304Jc l s s g mR P C D o n e: r p c Ox b48a8f48
(RPC#620) state 6,flags OxlOO
2014-10-09 15: 17: 55. 427: [CSSD) [3011132304) clssgmChangeMemCmpl: rpc Oxb48a8f48,
ret 0,client Ox99ld010 member Ox99ld0c0
2014-10-09 15:17:55.427: [CSSD) [3011132304)clssgmFreeRPCindex: freeing rpc 620
通信结束,rpc被释放。
2014-10-09 15:17:55.427: [CSSD) [3011132304)clssgmHandleGrockRcfgUpdate: grock(DG_DATA),updateseq(53),sendresp(l)
组的重新配置结束。
注意:
虽然ASM磁盘组被卸载,但是使用它的数据库如叫不一定会马上宏拌,这是因为ASM实例只负责管理ASM相关的元数据( Meta Data),而只有当数据库需要访问被卸载掉的磁盘组的元数据时才会出现问题。这也是很多读者发现的在ASM磁盘组卸载后数据库不会马上若掉的原因。
11g css 新特性
在了解了GM功能之 后,介绍llgG M层面推出的两个新特d性:成员终止升级( MemberKill Escalation)和Rebootless Restart。
成员终止升级
这个功能在ll gRl版本中被引人,在l lgR2版本中得到了进一步的完善和增强。首先需要介绍一下历史。在Oracle 9i/ I Og版本的集群中,如果一个数据库实例需要驱逐(当然很有可能会在alert log中看到ora-29740错误)另一个实例时,需要通过LMON进程在控制文件( Control File) 中写人相应信息,当目标实例的LMON进程读取到相应的信息后,该实例停止。但是,如果目标实例的LMON进程挂起而无法完成1/0的话,驱逐将无法成功,这种情况有可能导致整个数据库挂起,需要DBA手工干预。根据之前内容的介绍,LMON进程是数据库全局组的主成员,会注册到css 的GM上面,这也就意味着Oracle可以从GM的层面来清除LMON进程(例如直接使用kill命令终止有问题的LMON进程),进而达到实例驱逐的目的。但是,如果Oracle通过css 的GM层面终止LMON失败,或者无法在一定的时间之内成功的话,那么这很可能意味着对应节点已经出现了严重的问题,也就意味着数据库,甚至集群的一致性可能受到威胁。这个时候,读者自然而然会想到css 的NM功能应该出来工作了,NM会通过重启节点的方式来保证集群的一致性。这就是新特性一一成员终止升级(Member Kill Escalation )适用的情况,也是在实际的生产系统中经常出现的情况。
下面会较详细地介绍Oracle是如何实现成员终止升级功能的。当实例驱逐在指定的时间(默认20s)内不能成功完成时,Oracle会在css层面上产生一个新的进程一-Kill Daemon( 以下简称KD),以终止目标实例的LMO N进程,从而保证驱逐能够成功结束。如果情况更糟,KD 进程也无法在指定的时间(默认30s )内终止LMON 进程, css 会把成员终止( MemberKill )升级为节点终止(Node Kill ), 目标节点的css 会重新启动本节点, 以确保集群和数据库的一致性。
当然, 如果你使用的版本是l 1.2.0.2 或更高, 由于新特性Rebootless Rrestart 的引Node Kill 首先会尝试重新启动GI 软件, 如果不能够完成, 才会重新启动节点。
接下来通过下面的例子说明Member Kill Escalation是如何工作的。我使用了11.1.0.7 版本、RHEL5、双节点集群作为测试环境。














 2451
2451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









