






数理统计
1. 数理统计:就是未知总体分布,利用样本信息推断出总体分布或总体参数,是概率论研究的源头。(而概率论是已知总体分布,通过计算来的出x函数的期望和方差)
2. 参数估计:样本信息已知,对总体分布和参数做出估计。方法有:矩估计,最大似然估计,最小二乘估计。
3. 极大似然估计:参数的极大似然估计就是在参数空间中找到一个最恰当的值,就目前的样本空间来说,这个值做为该参数的估计是最为恰当的。求解:建立似然函数(似然函数L(Θ) = 所有样本的联合密度函数∏fx(xi:Θ),乘积展开,做对数变换,求导数得到极大值。
似然函数为样本发生的概率为 L(θ) = P {X1 = x1, · · · , Xn = xn} = ∏(i=1 - n) P {Xi = xi},即密度函数之和,即分布函数。
4. 线性回归(最小二乘估计):
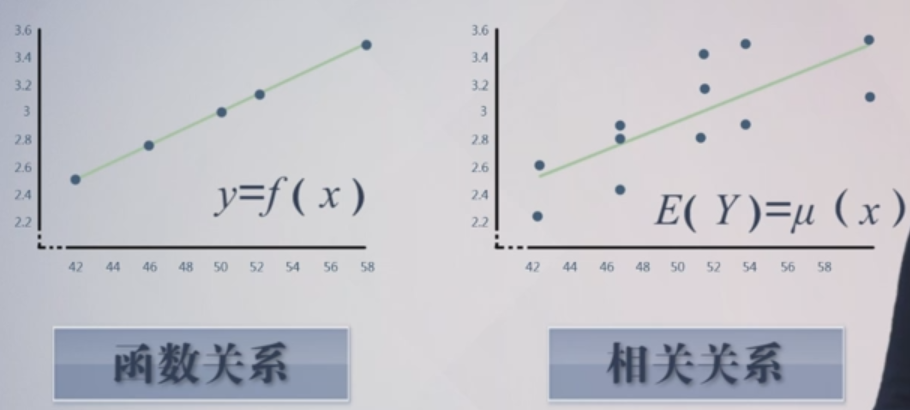
右图中,对于给定的变量x,变量Y可以取不同的值,取值有随机性,而且Y随x的增大有增大的线性趋势,这就是线性相关关系。
对随机变量Y取平均,即期望,能使随机性因素加权平均消掉。如果此时E(Y)等于μ(x),一旦知道函数μ(x),就可以从数量上掌握x与Y之间的大趋势。这就是一元线性回归处理相关关系的基本思想。
用直线来表示数据,表示为μ(x)=β0+β1x。设Y轴方向的误差为ξ,样本数据可以表示为y=β0+β1x+ξ。
函数Q(βi,βj)为观测点到直线的偏差的平方和,即误差ξi的平方和。ξ2 = Q(βi,βj)=( yi - (β0 + β1xi))2 。对其β0与β1分别求导,所求的β0尖与β1尖,就是使得误差平方和最小的参数估计。并得到回归方程:y尖=β0 尖+ β1尖x
1. 数理统计
概率论的研究,常常假设概率论已知,去计算概率。讨论分布或数字特征的一些性质。但在实际问题中,情况往往相反,一个随机变量服从什么样的分布可能完全不知道。
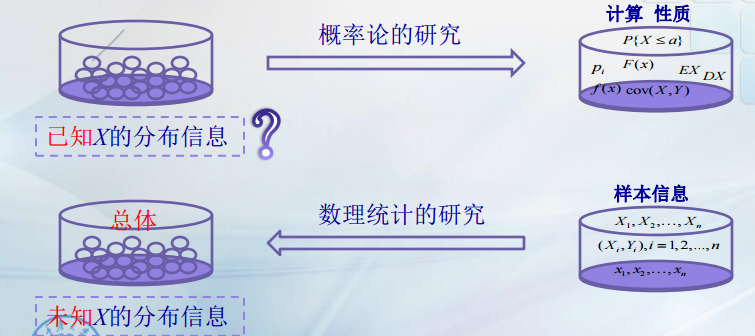
数理统计就是利用样本信息去推断总体分布或总体参数,是概率论研究的源头,也是一个思维归纳的过程。
例子
- 车辆的行驶速度服从正态分布, Γ分布还是指数分布?
- 城市里65岁以上老年人的 比例 p是多少呢?(这个问题服从两点分布,但不知道比例P)
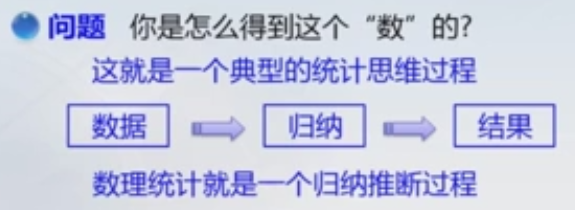
怎样才能知道一个随机变量的分布或其参数呢?这是数理统计要解决的首要问题。
就上面的例子而言,我们必要对其进行观测,取得信息,对其分布做出推断。由于每次观测是随机现象,那么对有限的观测对整体做出推断是不可能做到绝对准确的,所以我们用概率来度量其可靠性。数理统计就是研究统计推断方法,每个推断便随一定的概率以表明推断的可靠性。数理统计就是研究统计推断方法。

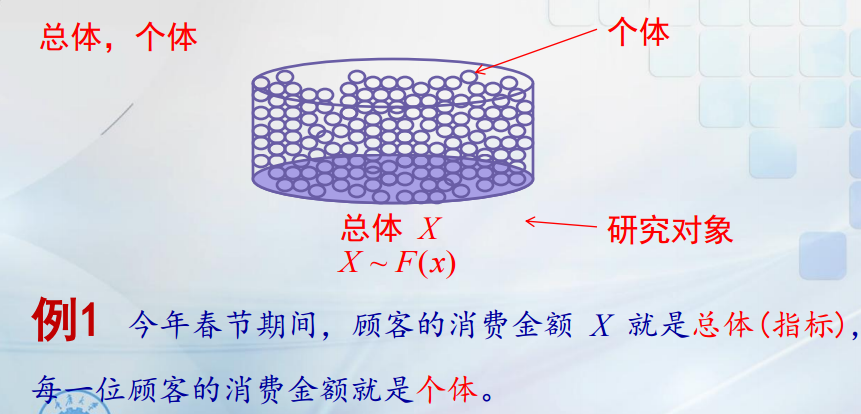
总体和个体都是数据,在数理统计中,我们将研究的的对象所构成的集合称为总体。而个体则是每个随机变量的值。
我们可以通过观测,从总体中抽取的部分个体称为样本。即n个个体指标 记为X1,X2,Xn ,其中n是样本容量。




离散型:

总体的分布未知,从总体里抽样,抽样之后我们得到样本,有了样本我们就进行观测,从而得到样本值,在通过样本值对总体的分布进行推断。
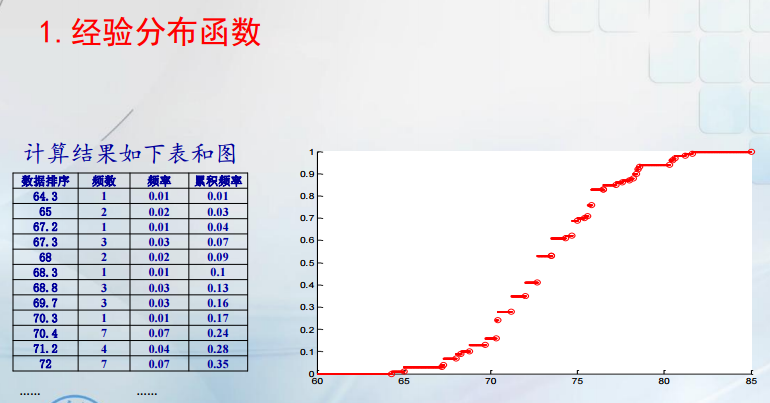
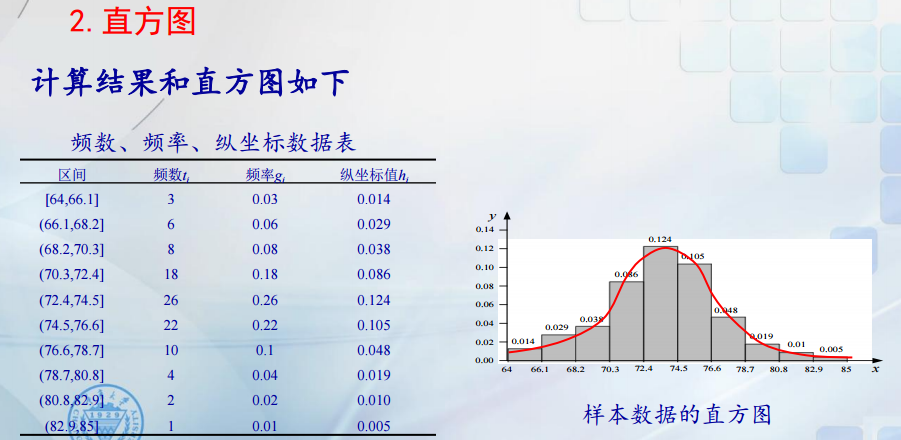
我们可以根据样本信息,利用图形来直观的描述样本观测值的分布特征。一般用经验分布函数刻画分布函数,而用直方图描述其密度函数。



除了对样本数据进行描述以外,我们还可以构造样本函数,它能刻画总体的数字特征,如均值,方差等。

样本均值和样本方差主要刻画主体分布的中心位置和偏离中心的程度。
中位数和极差也同样可以刻画主体分布的中心位置。 只是用在不同的情况下。

2. 参数估计
总体的参数:是指确定总体分布的特定的数 θ
参数空间:总体分布中参数的取值范围 Θ,则 θ ∈ Θ。

泊松分布的参数是λ ;正态分布的参数是μ和σ;一般分布的Θ等,注意参数的取值范围。
参数估计就是讨论如何由样本 {X1, X2, · · · , Xn} 提供的信 息,对总体分布中的未知参数作出估计。
如图所示,不同的μ值将对应不同的分布,μ取1时对应这个分布是比较合适的。
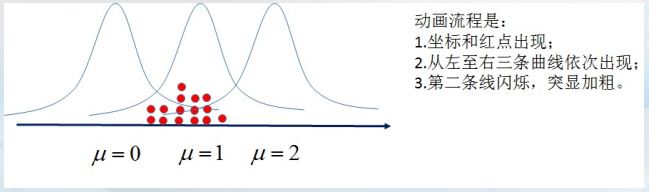
但μ取1是不是最合适的呢?就要同过样本数据进行改进,就需要参数估计的方法包括矩估计法、极大似然法以及最小二乘法 等等
估计量与估计值
从样本 {X1, X2, · · · , Xn} 出发,
估计量:θˆ = θ(X1, X2, · · · , Xn)
估计值:θˆ = θ(x1, x2, · · · , xn)
区别:估计量是Xi的函数,是随机变量,有分布;而估计值xi仅仅只是一个数值。
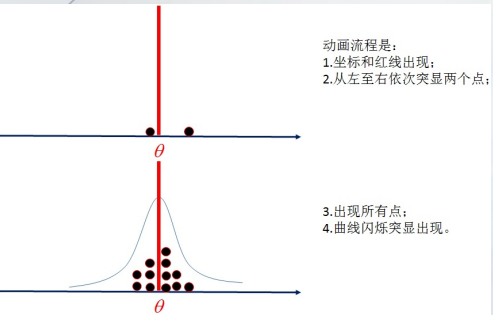
如果一个抽样后,估计值与真实值相当接近,请问这个估计是不是一个好估计,能不能保证下一个抽样的估计值也与真实值相当估计。那要用什么来衡量这个估计好呢?
得用偏离程度来比较估计值的好坏,即比较方差。
估计值在实际计算中,应用较多;而在统计研究中,我们更关注与估计量及其分布。
参数估计的呈现方式
点估计:一个估计点值来估计参数的估计。
点估计:θˆ = θ(X1, X2, · · · , Xn)
区间估计:用上下两个估计值形成一个区间来估计参数的估计。
区间估计:[θˆ1, θˆ2],其中
θˆ1 = θˆ1(X1, X2, · · · , Xn) ,
θˆ2 = θˆ2(X2, X2, · · · , Xn)
使得 P {θˆ1 < θ < θˆ2} = 1 − α
例如,考试完后,人家问你能考多少分,你说能考八九十分。这就是区间估计。
参数估计以分布类型确定为前提:参数估计仅仅只解决在同一分布类型中,选出最恰当的分布 来描述总体。当获得样本后,用什么样的分布类型来描述,这 实际上是作参数估计之前需要解决的问题。
我们常用样本的实际背景来确定总体的分布。比如,车流数据用泊松分布类,身高数据用正态分布类。
3. 矩估计
矩估计的优缺点:
优点: ① 方便,直观,简洁,明快
② 对E(X), D(X)作估计时,无需知道总体的分布类型
缺点 ① 当总体的矩不存在时,矩法失效
② 矩估计是建立在大数定律上的,n 要求充分大
③ 仅用矩来进行统计推断,没有充分利用总体分布的信息
④ 矩估计结论不唯一
⑤ 矩估计结果可能不合理
4. 极大似然估计
极大:最大,最可能
似然:最恰当,最合理
参数有其自身的取值范围,称为参数空间。所谓参数的极大似然估计就是在参数空间中找到一个最恰当的值,就目前的样本空间来说,这个值做为该参数的估计是最为恰当的。


A与B事件相互独立,所以P(B)=P{取黑球}2=1/16或9/16。
由于B事件的发生,使得P=3/4更似然一些,而且这次得到的结论比第一次要肯定的多。这是样本容量的增加,是可信度增强了。
所以从引例中我们可以得知:参数取哪个使得样本发生的概率最大,那个值就称为参数的极大似然估计。
极大似然估计的一般步骤为:
- (1) 写出似然函数;
- (2) 对似然函数取对数;
- (3) 求导数;
- (4) 解似然方程;
- (5)判断最值点。


![]() 表达式的意思是样本发生的概率。在表达式中,xi和e是已知的,而参数λ是未知的。那么λ的不同会导致这个表达式的不同呢?
表达式的意思是样本发生的概率。在表达式中,xi和e是已知的,而参数λ是未知的。那么λ的不同会导致这个表达式的不同呢?
会的,于是我们可以把样本x1,x2,....,xn发生的概率用λ函数表达L(λ),![]() ,记为似然函数,λ应该大于0。λ应该如何取值呢?
,记为似然函数,λ应该大于0。λ应该如何取值呢?
λ的值应该取为使得L(λ)最大的那个点。即求L(λ)的导数为0时,λ为最大值。
对数变换是单调增,不会改变原函数的极值点。 对数变换把乘积化为求和,和的导数运算就容易的多了。所以做对数运算是计算似然函数的主要方法。
注意:L(λ)函数的导数值只是极值,极大值仍需要用二阶导数来判断。二阶导数恒小于0,则λ的值为极大值。
在离散型分布中,似然函数为样本发生的概率为 L(θ) = P {X1 = x1, · · · , Xn = xn} = ∏(i=1 - n) P {Xi = xi},即密度函数之和,即分布函数。在由样本的独立性做乘法展开,从而求解似然函数的最大值点,来作为似然估计。
连续型随机分布,是不是同样可行呢? P {X1 = x1, · · · , Xn = xn} = 0。可是连续型的随机变量在单点中发生的概率是0。理论上x与x'发生的概率都为0,但由于f(x)密度函数,f(x) > f(x'),我们知道点x比点x'附近的可能性要大,如图所示。
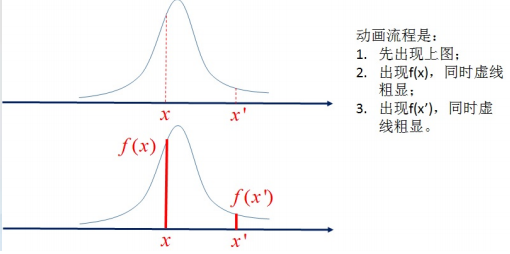
同理,在 (X1, X2, · · · , Xn) 的联合分布中,样本点x1,x2...xn发生了,我们将采用样本点的联合密度函数( f(x1, x2, · · · , xn) )来描述样本点附近发生的概率, 即密度函数之和,即分布函数。
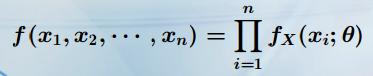
由似然法思想,在联合密度函数点 (x1, x2, · · · , xn) ∈ Rn 上的取值应最大。记联合密度函数为L(Θ):![]() 为似然函数。则参数的极大似然估计 θˆ 应满足最大值:
为似然函数。则参数的极大似然估计 θˆ 应满足最大值: ![]()


建立似然函数,乘积展开,在θ大于-1的参数空间中,我们需要找到似然函数的最大值点。做对数变换,在求导数找到极大值。
求解过程中,是基于样本点值xi来进行的。 即这里的似然解是一个估计值,但考虑到整个求解过程不受样本x1,x2,...,xn取值的不同而改变,所以将似然解一般化,记为Xi,成为估计量。
似然估计与矩估计表达式不同,代入样本后的数值也不同。
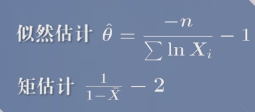


没有极值点,就考虑最值点。在端点处可取到最值点(单调增大或减少)。
极大似然估计的优缺点:
优点: ① 利用了总体的分布信息
② 不要求总体矩一定存在
③ 对样本容量没有要求
缺点: ① 似然方程可能无解,需要讨论
② 似然方程可能非常复杂,只能求数值解获得估计值
5. 线性回归
5.1 变量与变量之间的关系:确定性关系和相关性关系
- 确定性关系:当一个变量给定时,就确定另一个变量的值与之对应。如函数关系:圆的面积(S)与半径(R)之间的函数关系:S=∏R2
- 相关性关系:当一个变量给定时,受影响的另一个变量的值不能完全 确定,而是在一定范围内变化。BMI:身高与体重的关系。
右图中,对于给定的变量x,变量Y可以取不同的值,取值有随机性,而且Y随x的增大有增大的线性趋势,这就是线性相关关系。
对随机变量Y取平均,将随机性因素加权平均消掉。如果此时E(Y)等于μ(x),一旦知道函数μ(x),就可以从数量上掌握x与Y之间的大趋势。这就是一元线性回归处理相关关系的基本思想。
5.2 建立一元线性回归模型:
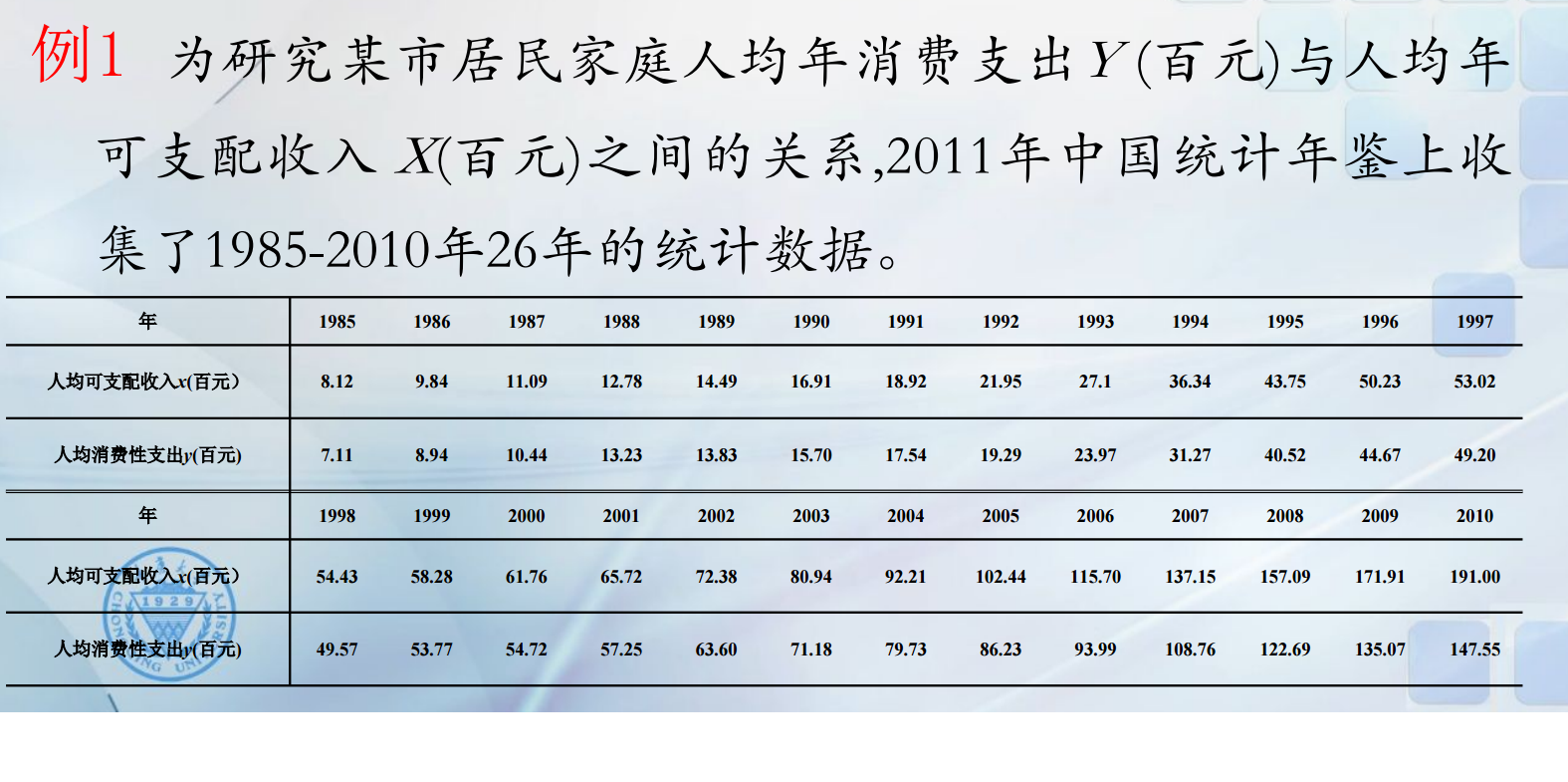
将数据做散点图,在散点图中,我们发现26个数据点基本在一条直线上的,说明x与Y成线性相关关系。
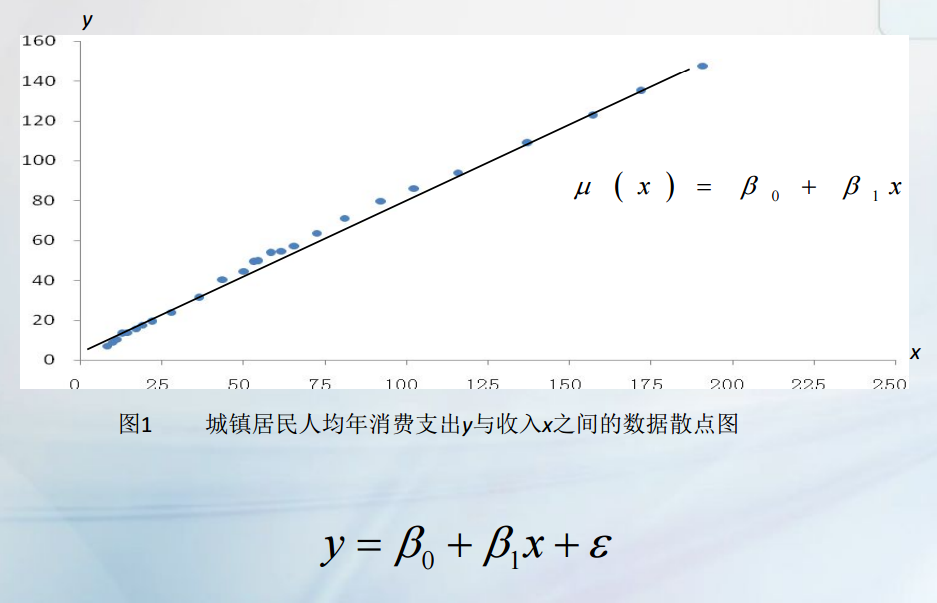
用直线来表示数据,表示为μ(x)=β0+β1x。设Y轴方向的误差为ξ,样本数据可以表示为y=β0+β1x+ξ。
将此类问题抽象出来,给定n个样本点(xi,Yi),定义一元线性回归模型,其中为β0与β1未知的回归系数,ξ服从正态分布,ξi与ξj相互独立:

图中所示x与Y是线性相关,线性相关的直线应该是最接近所有观察点的直线,即Yi到这条直线的竖直距离最短。通常采用距离的平方和最小原则。由于平方运算也称为二乘运算,因此上述求最佳直线的方法也称为二乘最小法。

用最小二乘法所得到β0与β1估计记为β0尖与β1尖。我们称![]() ,y关于x的经验回归函数,简称为回归方程,其图形称为回归直线。
,y关于x的经验回归函数,简称为回归方程,其图形称为回归直线。
样本点yi与回归直线上yi尖的竖直距离定义为残差,记为ei。

根据最小二乘法思想,记函数Q(β0,β1)为观测点到直线的偏差的平方和,即误差ξi的平方和。
则所求的β0尖与β1尖,就是使得误差平方和最小的参数估计。


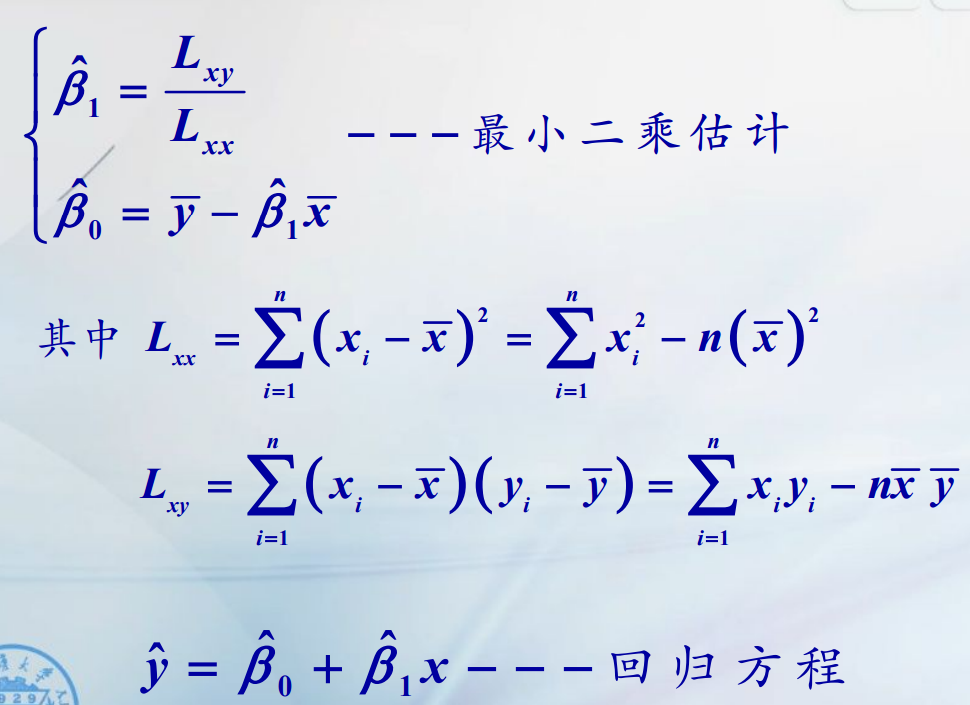
利用excel中的数据分析功能:
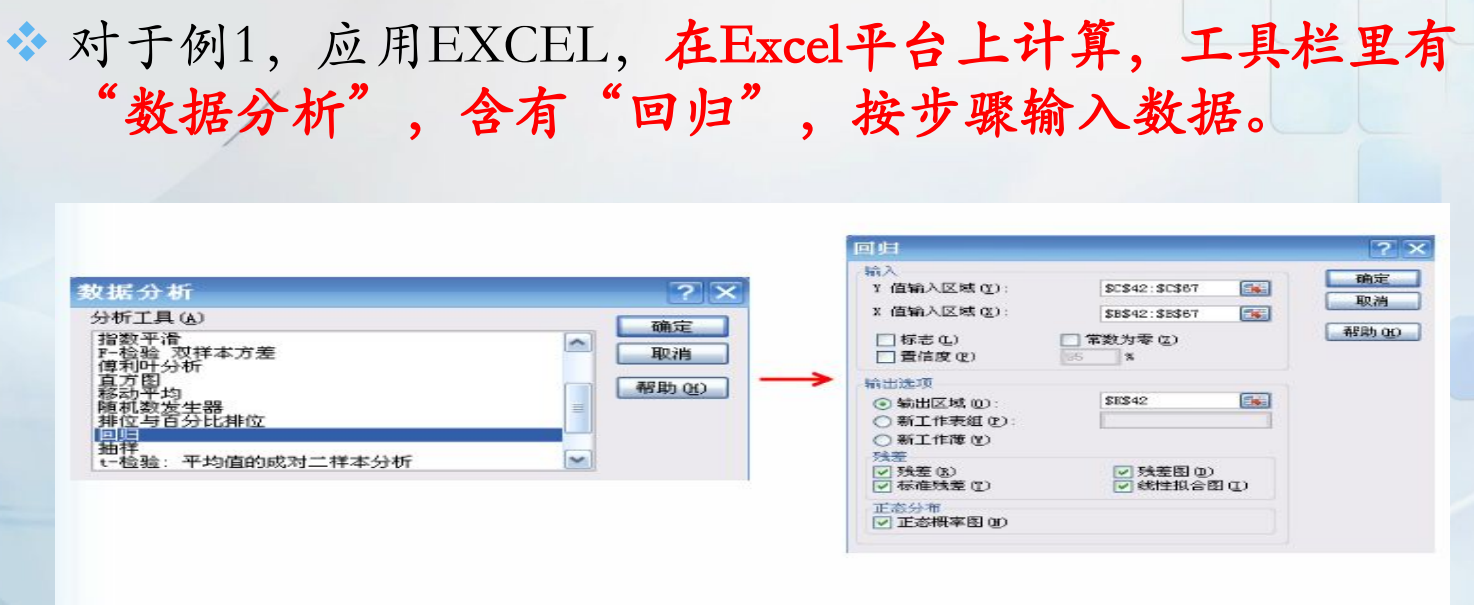
计算结果得到:y=4.5516+0.7718x,说明可支配收入与支出的关系为两者成正相关性。当可支配收入增加1个单位,则平均消费支出增加0.7718个单位。

5.3 相关系数检验
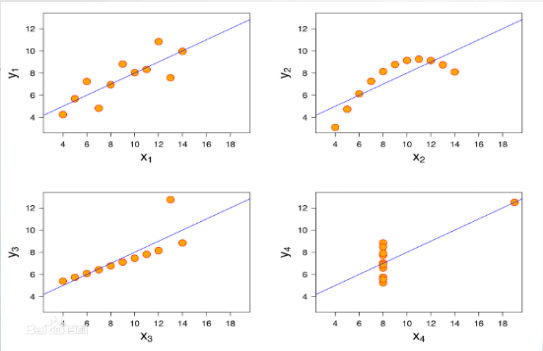
左上的图,拟合直线效果不错,左下图,有异常点的存在导致直线整体上拉,右上图,样本点显曲线状,右下图,数据点显两点。后三种都不应该用直线拟合。
两个随机变量间的线性相关性进行检验:引入一个数量性指标来描述两个变量之间线性关系的密切程度。这个指标就是相关系数。

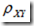 =
= 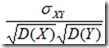

在图中,我们画出回归直线和直线y巴,选择第i个点,考虑纵坐标yi,yi尖和y巴的关系。yi与回归拟合点yi尖的距离称为残差,表示回归直线不能解释样本点的部分。回归拟合点yi尖到样本均值y巴的离差表示回归直线解释回归直线表示样本点的部分。两部分加在一起就是总的拟差。

总离差平方和(SST):表示因变量的n个观测值与其样本均值的总差
回归平方和(SSR):反映自变量的x的变化对因变量y取值变化的影响。
残差平方和(SSE):反映除x以外的其他因素对y取值的影响。
由于SSE总大于等于0,所以r2<=1. r的取值范围为[-1.1]。

r2 = SSR/SST,其中SST是不变的,r2表示变量x引起的变动占总变动的百分比,即x解释y所达到的百分比。
当|r|接近1,说明回归直线与样本观测值拟合程度越好,反之,当|r|接近0.,拟合程度越不理想。
















 8258
8258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









