







MySQL使用时,有一件很痛苦的事情肯定是结果乱码。将编码格式都设置为UTF8可以解决这个问题,我们今天来说下为什么要这么设置,以及怎么设置。
MySQL字符格式
字符集
在编程语言中,我们为了防止中文乱码,会使用unicode对中文字符做处理,而为了降低网络带宽和节省存储空间,我们使用UTF8进行编码。对这两者有什么不同不够了解的同学,可以参考Unicode字符集和UTF8编码编码的前世今生这篇文章。
同样在MySQL中,我们也会有这样的处理,我们可以查看当前数据库设置的编码方式(字符集):
mysql> show variables like '%char%';
+--------------------------+----------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/charsets/ |
+--------------------------+----------------------------------+
8 rows in set (0.00 sec)
表中就是当前设置的字符集,先看不用关注的几个值:
- character_set_filesystem | binary:文件系统上的存储格式,默认为binary(二进制)
- character_set_system | utf8:系统的存储格式,默认为utf8
- character_sets_dir | /usr/local/mysql/share/charsets/:可以使用的字符集的文件路径
剩下的几个就是日常影响读写乱码的参数了:
- character_set_client:客户端请求数据的字符集
- character_set_connection:从客户端接收到数据,然后传输的字符集
- character_set_database:默认数据库的字符集;如果没有默认数据库,使用character_set_server字段
- character_set_results:结果集的字符集
- character_set_server:数据库服务器的默认字符集
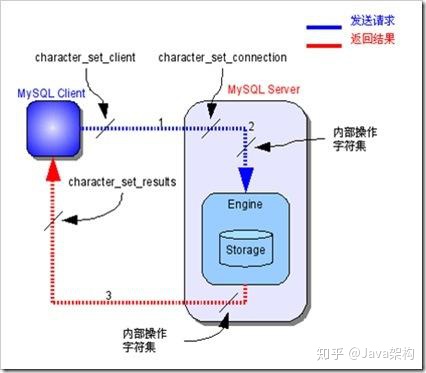
字符集的转换流程分为3步:
- 客户端请求数据库数据,发送的数据使用character_set_client字符集
- MySQL实例收到客户端发送的数据后,将其转换为character_set_connection字符集
- 进行内部操作时,将数据字符集转换为内部操作字符集:
- 使用每个数据字段的character set设定值
- 若不存在,使用对应数据表的default character set设定值
- 若不存在,使用对应数据库的default character set设定值
- 若不存在,使用character_set_server设定值
- 将操作结果值从内部操作字符集转换为character_set_results
字符序
说字符序之前,我们需要了解一点基础知识:
- 字符(Character)是指人类语言中最小的表义符号。例如’A’、’B’等;
- 给定一系列字符,对每个字符赋予一个数值,用数值来代表对应的字符,这一数值就是字符的编码(Encoding)。例如,我们给字符’A’赋予数值0,给字符’B’赋予数值1,则0就是字符’A’的编码;
- 给定一系列字符并赋予对应的编码后,所有这些字符和编码对组成的集合就是字符集(Character Set)。例如,给定字符列表为{‘A’,’B’}时,{‘A’=>0, ‘B’=>1}就是一个字符集;
- 字符序(Collation)是指在同一字符集内字符之间的比较规则;
- 确定字符序后,才能在一个字符集上定义什么是等价的字符,以及字符之间的大小关系;
- 每个字符序唯一对应一种字符集,但一个字符集可以对应多种字符序,其中有一个是默认字符序(Default Collation);
- MySQL中的字符序名称遵从命名惯例:以字符序对应的字符集名称开头;以_ci(表示大小写不敏感,case insensitive)、_cs(表示大小写敏感,case sensitive)或_bin(表示按编码值比较,binary)结尾。例如:在字符序“utf8_general_ci”下,字符“a”和“A”是等价的;
因此字符序不同于字符集,用于数据库字段的相等或大小比较。我们查看MySQL实例设置的字符序:
mysql> show variables like 'collation%';
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
| collation_connection | latin1_swedish_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
3 rows in set (0.00 sec)
跟utf8对应的常用字符序是:utf8_unicode_ci/utf8_general_ci和utf8_bin等,那么他们的区别是什么呢?
- _bin是用二进制存储并比较,区别大小写,存储二进制内容时使用
- utf8_general_ci:校对速度快,但准确度稍差,使用中英文时使用
- utf8_unicode_ci:准确度高,但校对速度稍慢,使用德法俄等外语时使用
详细的区别可以参考 Mysql中的排序规则utf8_unicode_ci、utf8_general_ci的区别总结。
修改字符集和字符序
如果在MySQL连接时,出现了乱码的问题,那么基本可以确定是各个字符集/序设置不统一的原因。MySQL默认的latin1格式不支持中文,由于我们在中国,所以选择对中文和各语言支持都非常完善的utf8格式。所以,我们需要将需要关注的字符集和字符序都修改为utf8格式。
你也可以选择utf8mb4格式,这个格式支持保存emoji表情。
我们需要修改Mysql的配置文件,查看配置文件的位置有两种方式:
1. $ mysql --help | grep 'my.cnf'
/etc/mysql/my.cnf /etc/my.cnf ~/.my.cnf
2. ps aux | grep mysql
在(1)中,/etc/my.cnf, /etc/mysql/my.cnf, ~/.my.cnf 这些就是mysql默认会搜寻my.cnf的目录,优先级依次升高。可以在各个配置文件里都使用long_query_time 来测试一下。
然后,我们修改或新增下面的配置项:
# 下面注释的几行可以不设置,但如果你的没有生效,也可以试试看
[mysqld]
character_set_server=utf8
collation-server=utf8_general_ci
skip-character-set-client-handshake
#init_connect='SET NAMES utf8'
#[client]
#default-character-set=utf8
这三行配置就可以解决问题,最关键的是最后一行,参考mysql文档,使用该参数会忽略客户端传递的字符集信息,而直接使用服务端的设定;再加上我们设定服务端的字符集和字符序均为utf8,这样就保证了字符格式的统一,解决乱码的问题。
重启mysql服务,如果提示找不到服务,请参考用service命令管理mysql启停:
$ service mysqld restart
Shutting down MySQL.. [ OK ]
Starting MySQL. [ OK ]
连接到mysql,查看当前编码:
mysql> show variables like '%char%';
+--------------------------+----------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/charsets/ |
+--------------------------+----------------------------------+
8 rows in set (0.01 sec)
mysql> show variables like 'collation%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8_general_ci |
+----------------------+-----------------+
3 rows in set (0.01 sec)
可以看到一切都符合预期,请求和存储的数据也不再是乱码了。
遇到的问题
unknown variable 'default-character-set=utf8'
参考官方文档,该参数自5.5.3版本废弃,改为了character-set-server,改为这个参数即可。
但这个是在[mysqld]下的配置,在[client]下的配置依然使用default-character-set参数。














 3158
3158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









