






总概:
1.Analysis初始
分析器是对测试结果进行分析的组件
Analysis Session分析会话的目的
发现系统性能上的缺陷并找到其根源
Analysis中的数据是怎么得到的
①场景运行时,默认情况下,所有的VUser信息都保存在该VUser的负载机上
②场景运行结束后,这些数据会自动的进行整理和合并,这时负载机上所有的VUser的信息和数据都被
保存到结果目录中,其扩展名为.lrr
关于数据分析
数据分析不仅局限于Analysis分析器,还可以采用多种方式
数据分析的多种形式(VUser日志,Controller输出,Analysis图,报告形式)
2.Analysis常用设置
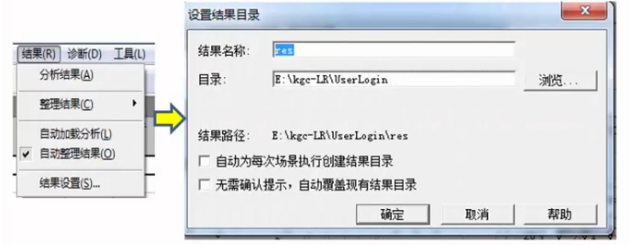
结果目录设置
在Controller运行场景过程中运行的数据要保存
结果集合设置
场景运行结束后,Analysis中收集的数据就是原始数据,可以通过设置进行筛选
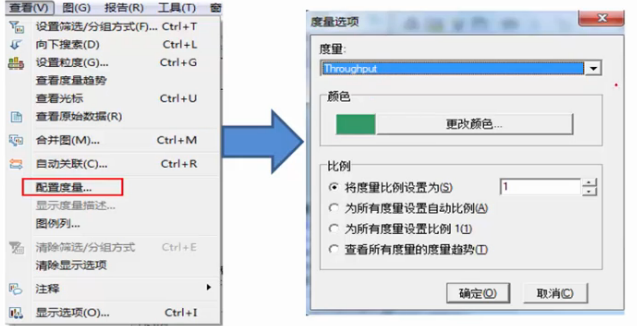
配置度量
想要对Y轴范围,图中折现颜色等进行设置
设置筛选条件:
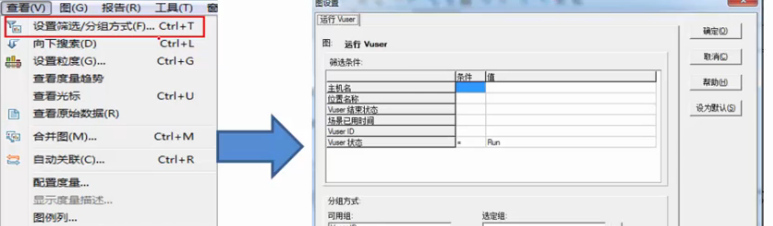
3.Analysis摘要报告
摘要报告提供了场景执行的一般信息,包括概要,统计,事务统计,SLA分析,HTTP响应统计(摘要报告包括的5大部分)
概要部分:

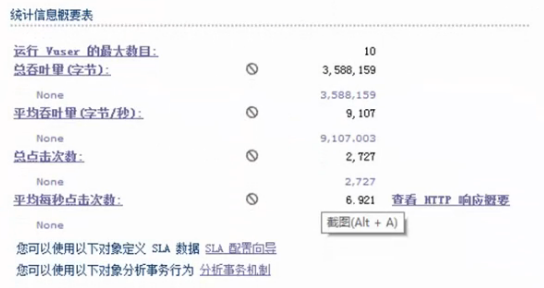
统计部分:
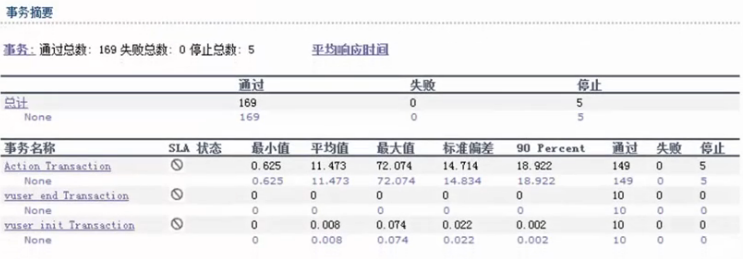
事务统计部分:
事务的通过率一定要大于95%,如果事务失败率过高,就说明客户在使用系统时容易出现错误,这样无论事务响应时间多短都不符合要求。
标准偏差:方差约大,说明这组数据越离散,波动性也越强,反之
90 Perecnet: 90%用户的响应时间是小于这个时间
HTTP响应概要:
只有Web Vuser才有,反应了Web Server的处理情况。
HTTP响应:HTTP响应的状态码
合计:HTTP响应的状态码的点击数
每秒:HTTP响应状态码每秒的点击数

4.Analysis常见分析图
常见的有8类:Vusers图,错误图,事务图,Web资源图,网页细分图,
系统资源图,Web服务器资源图,数据库服务器资源图
Windows操作系统,使用LoadRunner进行监控比较简单,Linux和UNIX等操作系统不可使用LoadRunner进行监控
常见的分析视图:
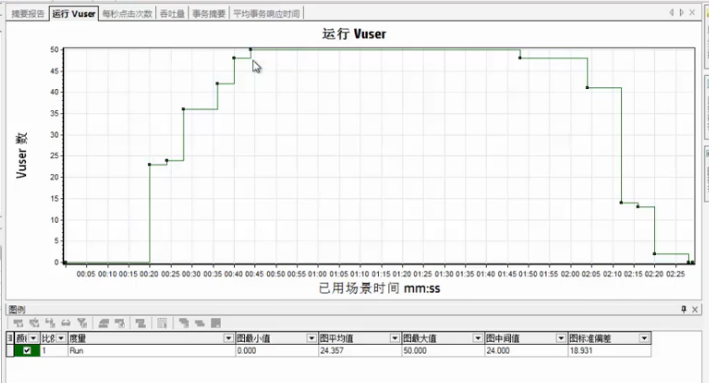
Vuser图
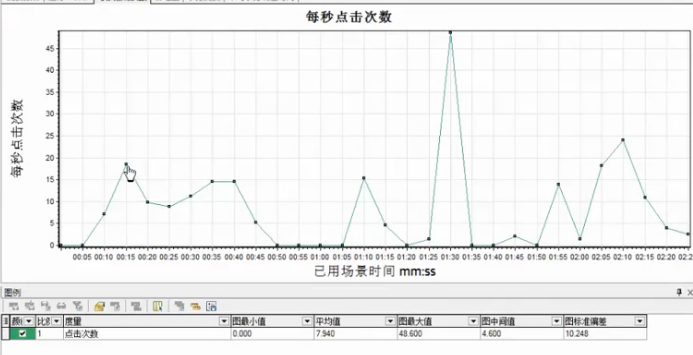
点击率视图
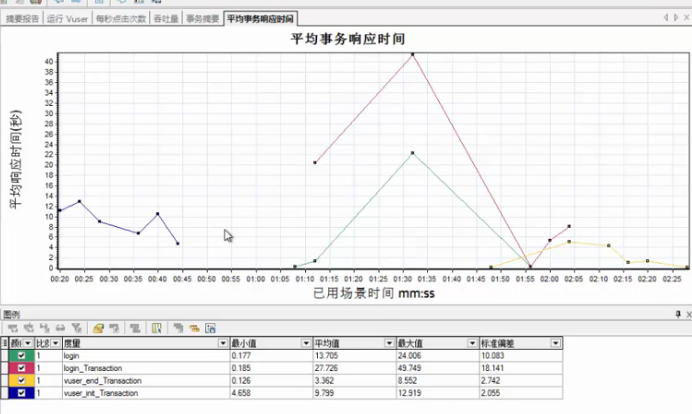
平均事务响应视图
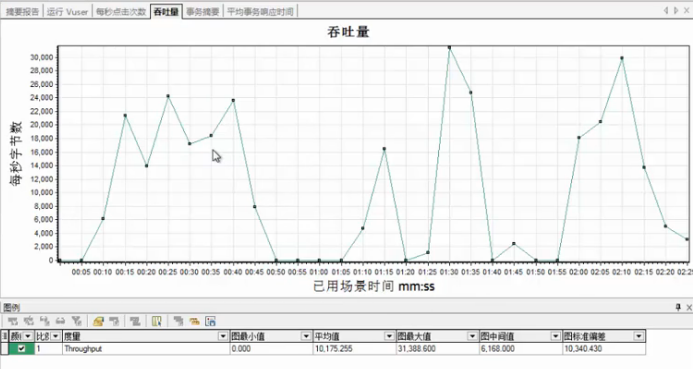
吞吐量视图
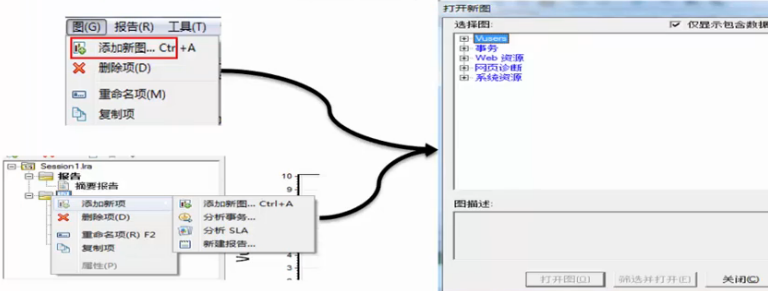
添加新图:
Vuser图:
点击率视图:
Vuser每秒钟向Web服务器提交的HTTP请求数,依据点击次数来评估Vuser产生的负载量
一般会将此图与平均事务响应时间图放在一起,观察点击数对事务性能产生的影响
平均事务响应时间
直观的反应事务的性能情况,一般与Vuser图进行参照,来观察Vuser性能对事务的性能的影响。
吞吐量图:
服务器上单位时间的吞吐量,此图可以评估Vuser产生的负载量
可以和平均事务响应时间图进行对照,查看吞吐量对事务性能产生的影响















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









