






感知器
感知器以一个实数值向量作为输入,计算这些输入的线性组合,然后如果结果大于某个阈值就输出1 ,否则输出-1 。
更精确地,如果输入为x,那么感知器计算的输出为:
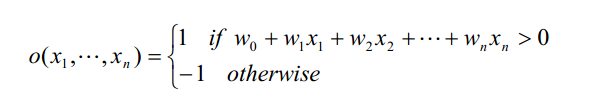
其中每一个w i 是一个实数常量,或叫做权值(weight ),用来决定输入xi 对感知器输出的贡献率。
请注意,常量(w0) 是一个阈值,它是为了使感知器输出 1 ,输入的加权和w1x1+w2x2+...+wnxn必须超过的阈值。
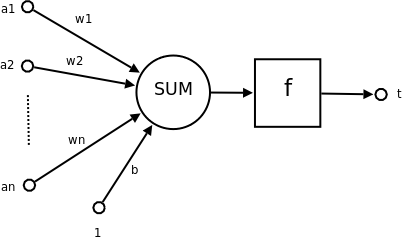
(此图是从网上扒来的,上图下方的的b对应于w0,1对应于x1,f的图像类似如下)
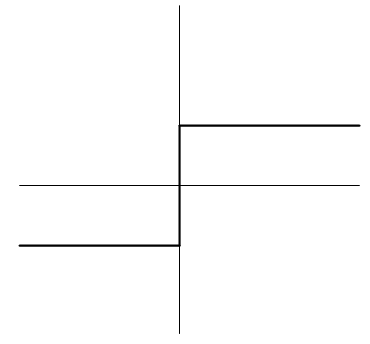
为了简化表示,我们假想有一个附加的常量输入x0=1,那么我们就可以把上边的不等式写成:
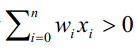
或以向量形式写为 。为了简短起见,有时会把感知器函数写成:
。为了简短起见,有时会把感知器函数写成:
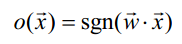 ,
,
其中:
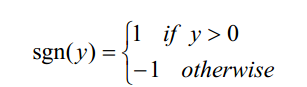
学习一个感知器意味着选择权w0,......wn的值。
1感知器的表达能力
我们可以把感知器看作n维实例空间(即点空间)中的超平面决策面。对于超平面一侧的实例,感知器输出1,对于另一侧的实例输出-1,如图1所示。这个决策超平面方程是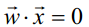 。当然,某些正反样例集合不可能被任一超平面分割。那些可以被分割的成为线性可分(linearly separable)的样例集合。
。当然,某些正反样例集合不可能被任一超平面分割。那些可以被分割的成为线性可分(linearly separable)的样例集合。
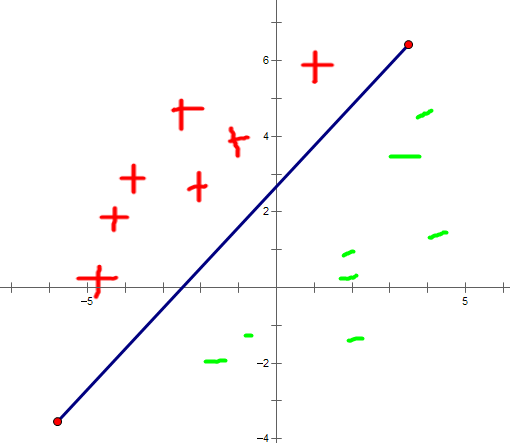
图 1
单独的感知器可以用来表示很多布尔函数。
例如,假如用1(真)和-1(假)表示布尔值,那么使用一个有两输入的感知器来实现与函数(AND)的一种方法就是设置w0=-0.8,w1=w2=0.5。
| x1 | x2 | x3 | 输出 |
| 1 | 1 | 1 | 1 |
| 1 | 1 | -1 | -1 |
| 1 | -1 | 1 | -1 |
| 1 | -1 | -1 | -1 |
同样的,这个感知器也可以来表示或函数(OR),那么只要改变它的权值w0=-0.3.
感知器可以表示所有的原子布尔函数(primitive boolean function):与,或,与非和或非。然而遗憾的是,一些布尔函数无法用单一的感知器表示,例如异或函数(XOR),它当且仅当x1≠ x2,时输出为1.
图2中线性不可分的训练样例集对应于异或函数。
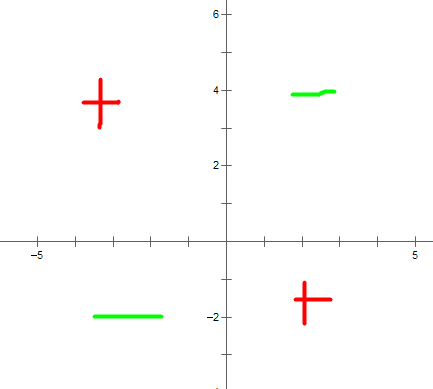
图2
感知器表示与、或、与非、或非的能力是很重要的,因为所有的布尔函数都可表示为基于这些原子函数的互连单元的某个网络。
事实上,仅用两层深度的感知器网络就可以表示所有的布尔函数,在这些网络中输入被送到多个单元,这些单元的输出被输入到第二级,也是最后一级。
因为阈值单元的网络可以表示大量的函数,而单独的单元不能做到这一点,所以通常我们感兴趣的是学习阈值单元组成的多层网络。
2感知器训练法则
现在我们来解决如何学习单个感知器的权值,也就是决定一个权向量,使得感知器对于给定的训练样例输出正确的1或-1.
为得到可接受的权向量,一种办法是从随机的权值开始,然后反复地应用这个感知器到每个训练样例,只要它误分类样例就修改感知器的权值。重复这个过程,知道感知器能正确分类所有的训练样例。
每一步根据感知器训练法则(perceptron training rule)来修改权值,也就是修改与输入 xi 对应的权 wi 法则如下:
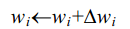
其中:
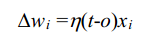
这里t是当前训练样例的目标输出,O是感知器的输出(1或-1),η是一个正的常数称为学习速率(learning rate)学习速率的作用是缓和每一步调整权的程度。它通常被设为一个小的数值(例如0.1),而且有时会使其随着权调整次数的增加而衰减。
对于权值的调整是一例一调,也就是输入一个样例,就计算每个Δwi, 来调整wi的值,一直训练到会收敛到一个能一个能正确分类所有训练样例的权向量,前提是训练样例线性可分,并且使用了充分小的η 。如果数据不是线性可分的,那么不能保证收敛。
实验:
利用感知器法则来训练训练感知器能够正确的表示与函数(AND)
训练样本:
1 1 1 1 -1 -1 -1 1 -1 -1 -1 -1
头文件
#ifndef HEAD_H_INCLUDED #define HEAD_H_INCLUDED #include <iostream> #include <fstream> #include <vector> #include <cstdio> #include <cstdlib> #include <cmath>
#include <ctime> using namespace std; const int DataRow=4; const int DataColumn=3; const double learning_rate=.1; //学习速率 extern double DataTable[DataRow][DataColumn+1]; //训练样例 extern double Theta[DataColumn]; // 权值 const double loss_theta=0.001; // 误差阈值 const int iterator_n =1000; //迭代次数 #endif // HEAD_H_INCLUDED
源代码:
#include "head.h" double DataTable[DataRow][DataColumn+1]; double Theta[DataColumn]; void Init() { srand((unsigned)time(NULL)); ifstream fin("data.txt"); for(int i=0;i<DataRow;i++) { DataTable[i][0]=1; // x1 默认为 1 for(int j=1;j<DataColumn+1;j++) { fin>>DataTable[i][j]; } } if(!fin) { cout<<"fin error"; exit(1); } fin.close(); for(int i=0;i<DataColumn;i++) { Theta[i]=rand()%1000/(double)10000;; //随机初始化theta } } int perceptron(double a) { if(a>0) return 1; else if(a<0) return -1; else { cout<<"perceptron error"; exit(0); } } void perceptron_rule() { double loss=100; for(int i=0;i<iterator_n&&loss>=loss_theta;i++) { loss=0;//训练误差 for(int j=0;j<DataRow;j++) { double error=0; for(int k=0;k<DataColumn;k++) { error+=DataTable[j][k]*Theta[k]; } error=DataTable[j][DataColumn]-perceptron(error); //计算t-o for(int k=0;k<DataColumn;k++) { Theta[k]+=learning_rate*error*DataTable[j][k]; //更新Theta } loss+=abs(error); } } } void printTheta() { for(int i=0;i<DataColumn;i++) cout<<Theta[i]<<" "; cout<<endl; } int main() { Init(); perceptron_rule(); printTheta(); return 0; }
结果
theta:
-0.1712 0.2836 0.2456














 2636
2636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









