






前言:
在上一篇《网络爬虫初步:从访问网页到数据解析》中,我们讨论了如何爬取网页,对爬取的网页进行解析,以及访问被拒绝的网站。在这一篇博客中,我们可以来了解一下拿到解析的数据可以做的事件。在这篇博客中,我主要是说明要做的两件事,一是入库,二是遍历拿到的链接继续访问。如此往复,这样就构成了一个网络爬虫的雏形。
笔者环境:
系统: Windows 7
CentOS 6.5
运行环境: JDK 1.7
Python 2.6.6
IDE: Eclipse Release 4.2.0
PyCharm 4.5.1
数据库: MySQL Ver 14.14 Distrib 5.1.73
效果图:
这里只截取开始的一部分数据。这些数据我是保存在MySQL中的。

思路梳理:
前面说到,我们拿到数据要做两件:数据保存与数据分析。
我们整个逻辑过程是这样的:
1.Java传递链接参数给Python;
2.Python解析HTML返回必要信息给Java;
3.Java拿到数据进行入库;
4.对解析出的有效链接进行继续遍历(这里是采用图的广度优先遍历)
5.反复以上的4个步骤,直到没有可继续访问的有效链接为止,这里是使用递归迭代。
关于数据保存,倒是没有什么好说的。因为我是在Linux(CentOS)下运行程序的。所以,你的Linux中必须要有MySQL,另外,我是通过Java来进行数据库操作的,所以这里你的系统中也有要Mysql的Java驱动包。
开发过程:
1.Python解析数据
get_html_response.py
# encoding=utf-8
import HTMLParser
import utils as utils
class ListWebParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.tagAFlag = False
self._name = None
self._address = None
self._info = []
def handle_starttag(self, tag, attrs):
if tag == 'a':
for name, value in attrs:
if name == 'href' and utils.isMatch(value, '^http'):
self._info.append((self._name, self._address))
self.tagAFlag = True
self._address = value
self._name = None
# print 'Address: ', value
def handle_endtag(self, tag):
if tag == 'a':
self.tagAFlag = False
def handle_data(self, data):
if self.tagAFlag:
name = data.decode('utf-8')
if self._name:
self._name = str(self._name) + ' ' + name
else:
self._name = name
def getLinkList(self):
return self._infohtml_parser.py
# encoding=utf-8
'''
对Html文件进行解析
'''
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from list_web_parser import ListWebParser
import get_html_response as geth
def main(html):
myp = ListWebParser()
get_html = geth.get_html_response(html)
myp.feed(get_html)
link_list = myp.getLinkList()
myp.close()
for item in link_list:
if item[0] and item[1]:
print item[0], '$#$', item[1]
if __name__ == "__main__":
if not sys.argv or len(sys.argv) < 2:
print 'You leak some arg.' # http://www.cnblogs.com/Stone-sqrt3/
main(sys.argv[1])2.Java入库
对于Java中对数据库的操作,也没什么好说说明的。如果你写地JDBC,那么这对于你而言将是小菜一碟。关键代码如下:
public class DBServer {
private String mUrl = DBModel.getMysqlUrl();
private String mUser = DBModel.getMysqlUesr();
private String mPassword = DBModel.getMysqlPassword();
private String mDriver = DBModel.getMysqlDerver();
private Connection mConn = null;
private Statement mStatement = null;
public DBServer() {
initEvent();
}
private void initEvent() {
mUrl = DBModel.getMysqlUrl();
mUser = DBModel.getMysqlUesr();
mPassword = DBModel.getMysqlPassword();
mDriver = DBModel.getMysqlDerver();
try {
Class.forName(mDriver).newInstance();
mConn = DriverManager.getConnection(mUrl, mUser, mPassword);
mStatement = mConn.createStatement();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 数据库查询
* TODO
* DBServer
* @param sql
* 查询的sql语句
*/
public void select(String sql) {
try {
ResultSet rs = mStatement.executeQuery(sql);
while (rs.next()) {
String name = rs.getString("name");
System.out.println(name);
}
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 插入新数据
* DBServer
* @param sql
* 插入的sql语句
*/
public int insert(String sql) {
try {
int raw = mStatement.executeUpdate(sql);
return raw;
} catch (SQLException e) {
e.printStackTrace();
return 0;
}
}
/**
* 某一个网址是否已经存在
* DBServer
* @param sql
* 查询的sql语句
*/
public boolean isAddressExist(String sql) {
try {
ResultSet rs = mStatement.executeQuery(sql);
if (rs.next()) {
return true;
}
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
return false;
}
public void close() {
try {
if (mConn != null) {
mConn.close();
}
if (mStatement != null) {
mStatement.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}3.Java进行递归访问链接
/**
* 遍历从某一节点开始的所有网络链接
* LinkSpider
* @param startAddress
* 开始的链接节点
*/
private static void ErgodicNetworkLink(String startAddress) {
SpiderQueue queue = getAddressQueue(startAddress);
// System.out.println(queue.toString());
SpiderQueue auxiliaryQueue = null; // 记录访问某一个网页中解析出的网址
while (!queue.isQueueEmpty()) {
WebInfoModel model = queue.poll();
// TODO 判断数据库中是否已经存在
if (model == null || DBBLL.isWebInfoModelExist(model)) {
continue;
}
// TODO 如果不存在就继续访问
auxiliaryQueue = getAddressQueue(model.getAddres());
System.out.println(auxiliaryQueue);
// TODO 对已访问的address进行入库
DBBLL.insert(model);
if (auxiliaryQueue == null) {
continue;
}
while (!auxiliaryQueue.isQueueEmpty()) {
queue.offer(auxiliaryQueue.poll());
}
}
}
/**
* 获得某一链接下的所有合法链接
* LinkSpider
* @param htmlText
* 网络链接
* @return
*/
private static SpiderQueue getAddressQueue(String htmlText) {
if (htmlText == null) {
return null;
}
SpiderQueue queue = PythonUtils.getAddressQueueByPython(htmlText);
return queue;
}本程序的内存及线程情况:
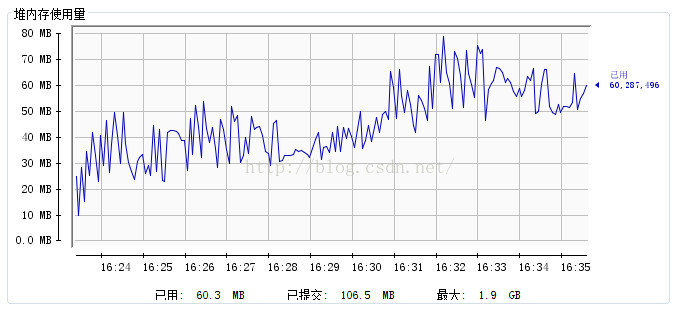
内存:
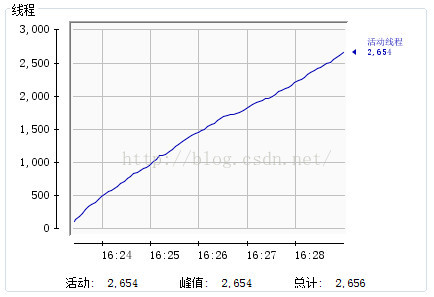
线程:
爬取速度:

要点说明:
1.系统中的MySQL及MySQL包
你的Linux中必须要有MySQL,另外,我是通过Java来进行数据库操作的,所以这里你的系统中也有要Mysql的Java驱动包。这一点在上面也有说明,不过这里还是要强调一下。如果你写过JDBC的程序,那么这个驱动包,我想你应该是有的,如果你没写过,那就去下一个吧。
2.需要一个辅助Queue
在上面的代码中,我们可以看到我们有两个SpiderQueue。一个是我们待访问的队列queue,保存我们将要访问的链接列表;另一个是辅助队列auxiliaryQueue,用于获得从Python解析出来的数据。
3.使用图的广度优先搜索算法进行链接爬取
这是从链接的相关性上考虑的。如果选择深度优先,那么随着遍历的深入,可能链接的相关性就会越来越小了。而广度优先搜索则不会这样,因为我们都知道在同一个页面中的链接总是会因为一些因素要展示在同一个页面中,那么它们的相关性就会比较靠谱。
4.单线程与多线程
完成以上操作,如果你的程序正常运行。在前期是比较快的,可是到了稳定期的时候就一般是1s钟出一条数据。这个有点慢,我会在下一篇博客利用多线程来解决这个问题。
5.MySQL中添加一个叫cipher_address的字段
此字段用于address的加密生成(MD5 or SHA1)。下面举个例子:

可能你有一个疑问,为什么要这个字段?如果你这样思考了,那么对于你,是有益的。我们知道其实MySQL对一个很长的字符串进行select的时候,是相对来说比较慢的。这时,我们可以把这个address进行哈希一下,形成一个长度适中,又比较相近的字符串,这样MySQL在比较时会容易一些(当然,你可以不使用这个字段)。
6.OOM异常
完全按照本文中的代码和讲解来进行编码的话,会获得一个OOM的异常(我的程序是跑了1天半的时时间)。如下:
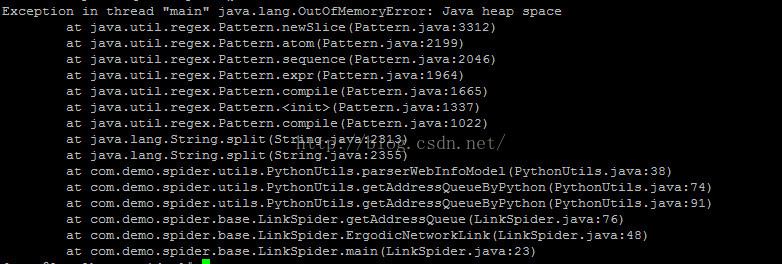
数量大概在23145条左右

对于这一点在上面关于内存和线程的展示图中可以看到原因。















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









