






上一篇我们了解了Sizzle的整体流程,下面我开始一点点分析各个流程,我们进行查询的第一步就是词法分析tokenize,同样先了解下思路,如果是#div_test > span input[checked=true]会发生什么:
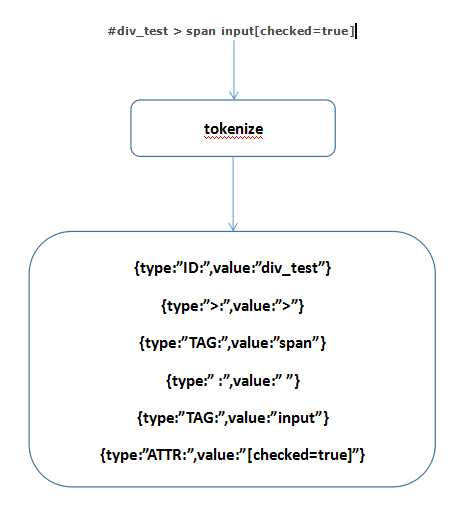
一个字符串的每个节点都被分析为以下数据结构:{type:'对应的Token类型',value:'匹配到的字符串', matches:'正则匹配到的一个结构'}
type包括有TAG, ID, CLASS, ATTR, CHILD, PSEUDO, NAME,表示每个字符串的类型
value是指字符串本身的值
match正则匹配到的一个结构
我们通过console打印出来的数据结构是下面:

首先说明一下下面代码中tokens数组和groups数组的关系,
比如#div_test span 那么我们分析后的结果是一个tokens数组,包含两个元素div_test和span [{type:"ID",value:"div_test"},{type:"TAG",value:"span"}]
如果是 #div_test span,#sp_test span,那么是两组tokens数组 一个包含div_test和span 一个包含sp_test和span 那这两组tokens就形成一个二维数组groups
[
[{type:"ID",value:"div_test"},{type:"TAG",value:"span"}]
[{type:"ID",value:"sp_test "},{type:"TAG",value:"span"}]
]
代码总体思路是
1. 如果有逗号,会过滤掉这个逗号,比如"div1,div2"第二次循环是selector的值是",div2"需要删掉前面的逗号,然后为groups新增元素
2. 如果是关系运算符 > + 空格 ~开头,直接压入数组
3. 然后开始分析 ID,TAG,CLASS,ATTR,CHILD,PSEUDO选择符,如果匹配到了相关选择符,再看看是否需要预处理,如果需要再进行预处理返回(只有部分选择符需要,后面详解),然后压入数组,删除相关选择符字符串
4. 继续下一个循环直到结束
//把字符串转换为token数组,格式为{type:'对应的Token类型',value:'匹配到的字符串', matches:'正则匹配到的一个结构'}
function tokenize(selector, parseOnly) { var matched, match, tokens, type, soFar, groups, preFilters, cached = tokenCache[selector + " "]; if (cached) {//如果有缓存直接读取缓存 return parseOnly ? 0 : cached.slice(0); } soFar = selector; groups = []; //这是最后要返回的二维数组
//预处理器,对token进行预处理
//预处理,有的选择器,比如属性选择器与伪类从选择器组分割出来,还要再细分
//属性选择器要切成属性名,属性值,操作符;伪类要切为类型与传参;
//子元素过滤伪类还要根据an+b的形式再划分
preFilters = Expr.preFilter;
while (soFar) {//对选择符逐个字符分析
//如果第一个字符是逗号,跳过逗号,并且压入第一个空token分组,groups是个二维数组,每个元素代表一个token数组, if (!matched || (match = rcomma.exec(soFar))) { if (match) { soFar = soFar.slice(match[0].length) || soFar; } groups.push(tokens = []); } matched = false; //如果开头的字符是关系选择符 > + 空格 ~ 将他直接压入tokens数组,并且删除selector相关部分 if ((match = rcombinators.exec(soFar))) { matched = match.shift(); tokens.push({ value: matched, // Cast descendant combinators to space type: match[0].replace(rtrim, " ") }); soFar = soFar.slice(matched.length); } /*然后开始分析ID,TAG,CLASS,ATTR,CHILD,PSEUDO
matchExpr 过滤正则
ATTR: /^\[[\x20\t\r\n\f]*((?:\\.|[\w-]|[^\x00-\xa0])+)[\x20\t\r\n\f]*(?:([*^$|!~]?=)[\x20\t\r\n\f]*(?:(['"])((?:\\.|[^\\])*?)\3|((?:\\.|[\w#-]|[^\x00-\xa0])+)|)|)[\x20\t\r\n\f]*\]/
CHILD: /^:(only|first|last|nth|nth-last)-(child|of-type)(?:\([\x20\t\r\n\f]*(even|odd|(([+-]|)(\d*)n|)[\x20\t\r\n\f]*(?:([+-]|)[\x20\t\r\n\f]*(\d+)|))[\x20\t\r\n\f]*\)|)/i
CLASS: /^\.((?:\\.|[\w-]|[^\x00-\xa0])+)/
ID: /^#((?:\\.|[\w-]|[^\x00-\xa0])+)/
PSEUDO: /^:((?:\\.|[\w-]|[^\x00-\xa0])+)(?:\(((['"])((?:\\.|[^\\])*?)\3|((?:\\.|[^\\()[\]]|\[[\x20\t\r\n\f]*((?:\\.|[\w-]|[^\x00-\xa0])+)[\x20\t\r\n\f]*(?:([*^$|!~]?=)[\x20\t\r\n\f]*(?:(['"])((?:\\.|[^\\])*?)\8|((?:\\.|[\w#-]|[^\x00-\xa0])+)|)|)[\x20\t\r\n\f]*\])*)|.*)\)|)/
TAG: /^((?:\\.|[\w*-]|[^\x00-\xa0])+)/
bool: /^(?:checked|selected|async|autofocus|autoplay|controls|defer|disabled|hidden|ismap|loop|multiple|open|readonly|required|scoped)$/i
needsContext: /^[\x20\t\r\n\f]*[>+~]|:(even|odd|eq|gt|lt|nth|first|last)(?:\([\x20\t\r\n\f]*((?:-\d)?\d*)[\x20\t\r\n\f]*\)|)(?=[^-]|$)/i
*/
for (type in Expr.filter) {
if ((match = matchExpr[type].exec(soFar)) && (!preFilters[type] ||(match = preFilters[type](match)))) {
matched = match.shift();
tokens.push({
value : matched, type : type, matches: match }); soFar = soFar.slice(matched.length); } } if (!matched) { break; } } // Return the length of the invalid excess // if we're just parsing // Otherwise, throw an error or return tokens return parseOnly ? soFar.length : soFar ? Sizzle.error(selector) : // Cache the tokens tokenCache(selector, groups).slice(0); }
这里判断选择符的过程就是通过遍历Expr.filter来判断,我们来看看这个东西:
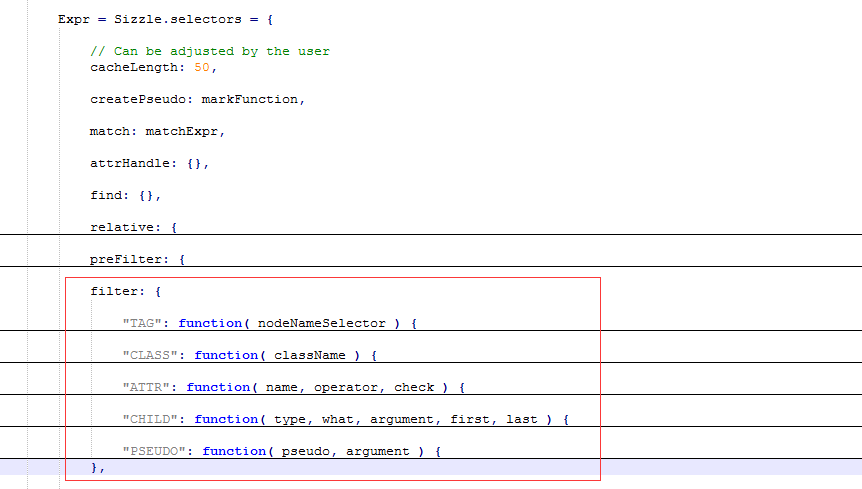
除了这5个,后面还根据浏览器兼容性新增了ID类型,为何要遍历这个对象呢,因为Sizzle里面把选择器字符串的类型就分了这么几种
ID:ID选择符
Class:类选择符
Tag:标签选择符
ATTR:属性标签
CHILD:包括(only|first|last|nth|nth-last)-(child|of-type)等等对子类的标签
PSEUDO:其他伪类选择符
对这些类型进行正则匹配之后,token数组就基本建立起来了,整个词法分析过程也就完成了。
顺便介绍下toSelector函数,他的过程刚好相反,就是把tokens字符串里面的值还原为字符串形式。
function toSelector( tokens ) { var i = 0, len = tokens.length, selector = ""; for ( ; i < len; i++ ) { selector += tokens[i].value; } return selector; }














 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









