






1:在Python自动化测试过程中,进行登陆的时候,一般都是要进行验证的校验的,自己也在百度一下,现在有2种方法:
1)找开发去掉验证码或者使用万能验证码
2)使用OCR自动识别(识别率不是很高,但简单的验证还是可以的)
2:使用OCR自动识别的思路是:(参考博客 http://www.cnblogs.com/landhu/p/4968577.html )
先将截取含有验证码的图片>>>>定位到验证码的坐标>>>>然后从坐标从截图中通过pytesseract进行截取验证码
#导入os库
import os
#用于改变当前工作目录到指定的路径
os.chdir('D:\Software\Python27\lib\site-packages\pytesseract')
#导入PIL 库做图像处理
from PIL import Image
#导入pytesseract库,pytesseract是用于验证码、字符识别(依赖环境是PIL和tesseract-ocr)
import pytesseract
#re 模块使 Python 语言拥有全部的正则表达式功能
import re
#导入webdriver模块
from selenium import webdriver
#导入等待时间模块
from time import sleep
#打开浏览器
driver = webdriver.Firefox()
#获取要登录的网址
driver.get("http://172.16.199.236:6600/bms/login.html")
#将页面窗口最大化
driver.maximize_window()
#等待5秒
sleep(5)
#截取当前网页,该网页有我们需要的验证码
driver.save_screenshot('d://aa.png')
# 定位验证码
imgelement = driver.find_element_by_xpath('//*[@id=\'codeValidateImg\']')
# 获取验证码x,y轴坐标
location = imgelement.location
# 获取验证码的长宽
size = imgelement.size
# 需要截取的位置坐标
rangle = (int(location['x']),int(location['y']),int(location['x']+size['width']),int(location['y']+size['height']))
# 打开截图
i = Image.open("d://aa.png")
# 使用Image的crop函数,从截图中再次截取我们需要的区域
bb = i.crop(rangle)
bb.save("d://bb.jpg","JPEG")
#打开截图
cc = Image.open('d://bb.jpg')
#使用image_to_string识别验证码
text = pytesseract.image_to_string(cc).strip()
#输出从截图获取到的字符串
print text
#用户Python的正则表达式将文本的验证中进行纯数字的提取
text1 = re.sub("\D","",text)
print text1遇到问题:
1:保存有验证码区域的图片时报错:
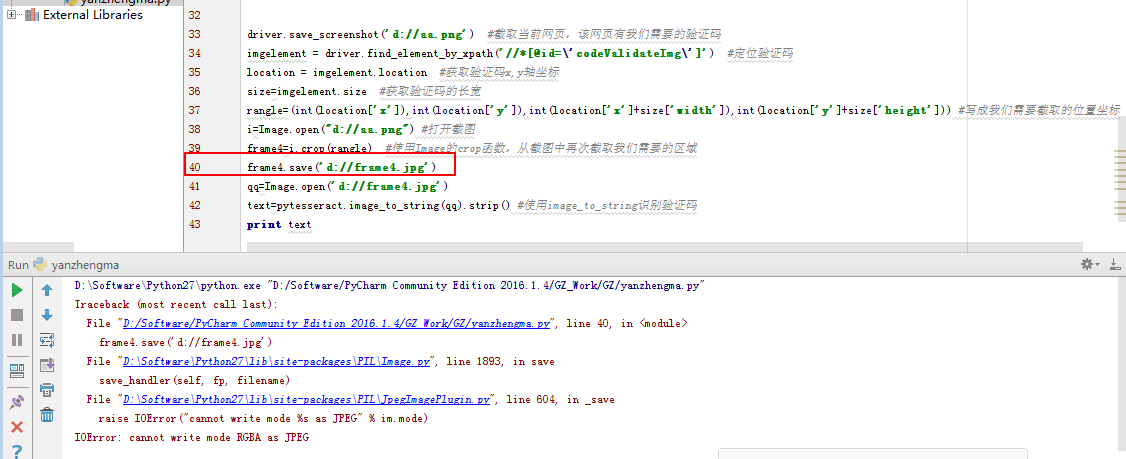
解决方案:我这里出现这个问题的原因是:我用pillow来代替PIL,产生的错误,重新从网上下载win7的64位的PIL进行安装,再次运行,解决(网上说这2兄弟没啥区别,但是为啥会出现这情况,我也还没搞明白)。
PIL下载地址参考博客:https://www.waitalone.cn/python-php-ocr.html
2:解决了上个问题1,之后又提示下图的错误:
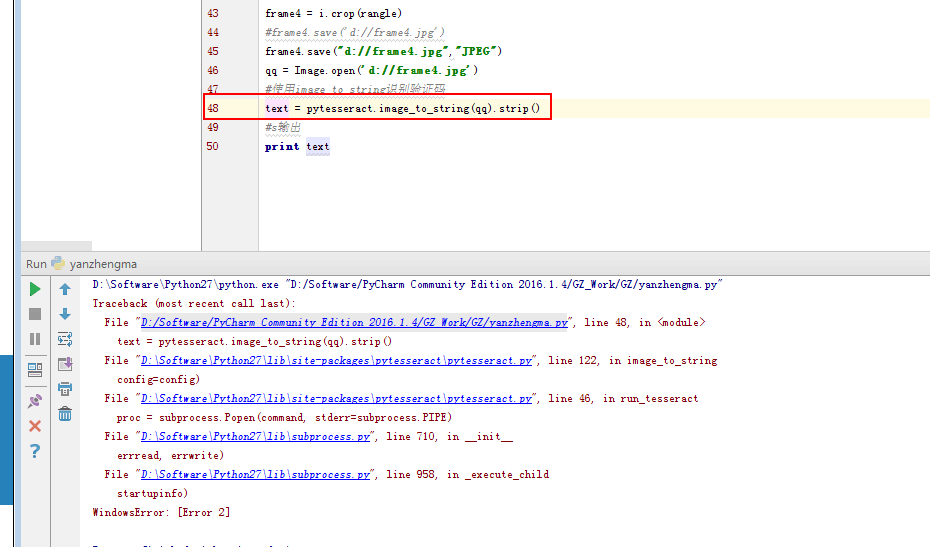
解决方案:改变当前工作目录到指定的路径,参考博客:http://www.jianshu.com/p/122f42624776
import os
os.chdir('D:\Software\Python27\lib\site-packages\pytesseract') #路径:pytesseract的路径
3:image_to_string识别验证码有误,错误提示如下图,
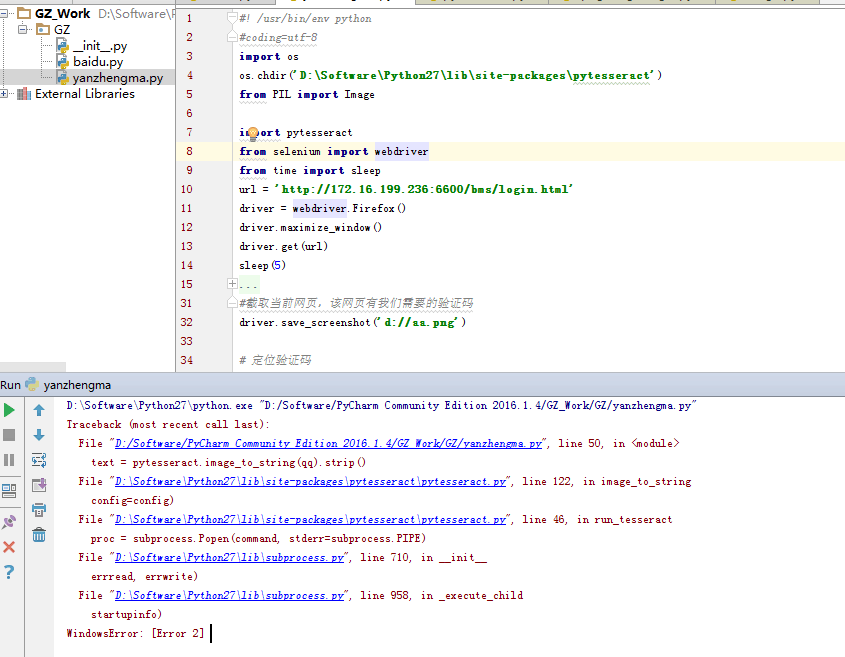
解决方案:下载图像识别类库tesseract-ocr工具进行安装,傻瓜式安装即可,安装好之后,还要将pytesseract.py代码中修改tesseract_cmd的路径,然后重新运行即可成功
#tesseract_cmd = 'tesseract'
tesseract_cmd = 'D:\Software\Tesseract-OCR/tesseract.exe'
4:运行以上的代码,可以将简单的验证提取出来,但是有时候会有小数点,通过re.sub()函数正则表达式进行过滤,参考博客:http://www.cnblogs.com/yyyg/p/5498803.html
import re
text1 = re.sub("\D","",text)
print text1














 130
130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









