






假定用户有某个周末网民网购停留时间的日志文本,基于某些业务要求,要求开发
Spark应用程序实现如下功能:
1、实时统计连续网购时间超过半个小时的女性网民信息。
2、周末两天的日志文件第一列为姓名,第二列为性别,第三列为本次停留时间,单
位为分钟,分隔符为“,”。
数据:
log1.txt:周六网民停留日志
LiuYang,female,20
YuanJing,male,10
GuoYijun,male,5
CaiXuyu,female,50
Liyuan,male,20
FangBo,female,50
LiuYang,female,20
YuanJing,male,10
GuoYijun,male,50
CaiXuyu,female,50
FangBo,female,60
log2.txt:周日网民停留日志
LiuYang,female,20
YuanJing,male,10
CaiXuyu,female,50
FangBo,female,50
GuoYijun,male,5
CaiXuyu,female,50
Liyuan,male,20
CaiXuyu,female,50
FangBo,female,50
LiuYang,female,20
YuanJing,male,10
FangBo,female,50
GuoYijun,male,50
CaiXuyu,female,50
FangBo,female,60
统计日志文件中本周末网购停留总时间超过2个小时的女性网民信息。
1、接收Kafka中数据,生成相应DStream。
2、筛选女性网民上网时间数据信息。
3、汇总在一个时间窗口内每个女性上网时间。
4、筛选连续上网时间超过阈值的用户,并获取结果。
1.启动zk
./zkServer.sh start
2.启动Kafka
./kafka-server-start.sh /root/apps/kafka/config/server.properties
3.创建topic
[root@mini3 kafka]# bin/kafka-console-producer.sh --broker-list mini1:9092 --topic sparkhomework-test
4.生产数据
代码
package org.apache.spark import org.apache.spark.streaming.Seconds import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.dstream.DStream import org.apache.spark.streaming.kafka.KafkaUtils /** * Created by Administrator on 2019/6/13. */ object SparkHomeWork { val updateFunction = (iter: Iterator[(String, Seq[Int], Option[Int])]) => { iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(v => (x, v)) } } def main(args: Array[String]) { val conf = new SparkConf().setMaster("local[2]").setAppName("SparkHomeWork") val ssc = new StreamingContext(conf, Seconds(5)) //将回滚点写到hdfs ssc.checkpoint("hdfs://mini1:9000/kafkatest") val Array(zkQuorum, groupId, topics, numThreads) = Array[String]("mini1:2181,mini2:2181,mini3:2181", "g1", "sparkhomework-test", "2") val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap).map(_._2) //筛选女性网民上网时间数据信息 val data = lines.flatMap(_.split(" ")).filter(_.contains("female")) //汇总每个女性上网时间 val femaleData: DStream[(String, Int)] = data.map { line => val t = line.split(',') (t(0), t(2).toInt) }.reduceByKey(_ + _) //筛选出时间大于两个小时的女性网民信息,并输出 val results = femaleData.filter(line => line._2 > 120).updateStateByKey(updateFunction, new HashPartitioner(ssc.sparkContext.defaultParallelism), true) results.print() ssc.start() ssc.awaitTermination() } }
打印结果:
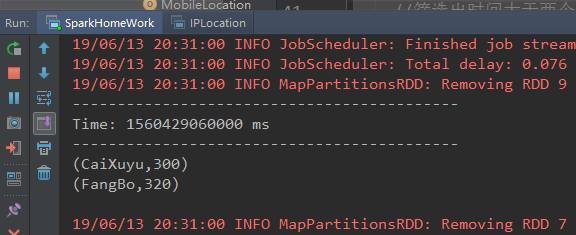















 1855
1855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









