






Problem Description
n个元素{1,2,...,n}有n!个不同的排列。将这n!个排列按字典序排列并编号为0,1,...,n!-1。每个排列的编号为其字典序值。例如,当n=3时,6个不同排列的字典序值如下:
| 字典序值 | 0 | 1 | 2 | 3 | 4 | 5 |
| 排列 | 123 | 132 | 213 | 231 | 312 | 321 |
给定n,以及n个元素{1,2,...,n}的一个排列,计算出这个排列的字典序值,以及按字典序排列的下一个排列。
Input
输入包括多组数据。
每组数据的第一行是元素个数n(1<=n<=13),接下来1行是n个元素{1,2,...,n}的一个排列。
 Output
Output
Sample Input
Sample Output
-----------------------------------------------------------------此处为比较,可以掠过不看,直接下拉----------------------------------------------------------------------------------------------------------------------------
排列的字典序,此题似乎与之前说过的全排列问题类似,但是输入顺序有区别的。
输入 1 2 3 全排列输出: 1 2 3 1 3 2 2 1 3 2 3 1 3 2 1 3 1 2 字典序输出: 1 2 3 1 3 2 2 1 3 2 3 1 3 1 2 3 2 1
区别在于最后的两行,为什么会出现这样的情况呢?
是因为在全排列问题时,利用的是对原数组进行替换。
初始:1 2 3
交换[1] [3] ,则变成 3 2 1,
再接下来的替换中,就按照 2 1进行的。
若想按照字典序输入,需要利用头尾数组算法。
建立两个数组 head,tail
初始化head为空,tail 为n个顺序元素。
{} {1,2,3}
伪代码:
permDict(head,tail,n) IF size(head)==n print head ELSE FOR i IN tail headtemp = head tailtemp = tail //初始化两个临时变量 headtemp.insert(i) //向headtemp中添加 i tailtemp.erase(i) //删除teailtemp中的i permDict(headtemp,tailtemp,n)
c++代码:
void PermDict(list<int> head,list<int> tail,int n) { if(head.size()==n) { for(list<int>::iterator iter=head.begin();iter!=head.end();++iter) cout<<*iter<<" "; cout<<endl; } else{ for(list<int>::iterator iter=tail.begin();iter!=tail.end();++iter) { list<int> headtemp=head,tailtemp=tail; headtemp.push_back(*iter); tailtemp.erase(find(tailtemp.begin(),tailtemp.end(),*iter)); PermDict(headtemp,tailtemp,n); } } }
------------------------------------------------------------------------华丽的分割线 ------------------------------------------------------------------------------------------------------------------------------------------
言归正传;
(由排列计算字典序)
设给定的{1,2,.....n}的排列为∏,其字典序值为 rank(∏,n).按字典序的定义显然有
(∏[1]-1*(n-1)! ≤ rank(∏,n) ≤ ∏[1]*(n-1)!-1
此公示理解:分析(∏[1]-1)(n-1)! (n-1)!为n-1位元素的全排列的个数。∏[1]为排列的第一个位元素,(∏[1]-1)(n-1)!为{∏[1],∏[2],...,∏[8]}的字典序值,其中∏[i]<∏[i+1], 1<i<n.即以∏[1]开头的第一个字典序列。
同理 ∏[1](n-1)!-1 为以∏[1]开头的最后一个字典序列。
设 r 是∏[1]开头的所有排列中的相对序号,则 r 也是{∏[2],...,∏[8]}作为集合{1,2,...,n}/{∏[1]}(去掉∏[1])中排列的字典序值。如果将{∏[2],...,∏[8]}中每个大于∏[1] 的元素都减 1 ,则得到集合{1,2,...,n-1}的一个排列∏`,其字典序值也是r,由此得到计算rank(∏,n)的递归式如下:
rank(∏,n) = (∏[1]-1)*(n-1)! + rank(∏`,n-1)
初始条件为:
rank([1],1) = 0
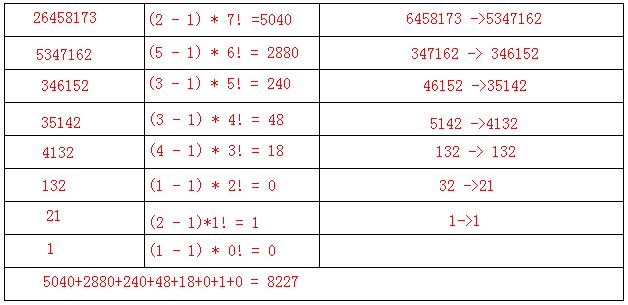
(注意:后面的元素大于∏[1]时,要把此元素减 1 )
int f(int n) // n的阶乘 { int r=1; if(n>0) { for(int i=1;i<=n;i++) r*=i; } return r; } int permRank(int n,int p[]) { int r=0; int rho[n]; for(int j=0;j<n;j++) rho[j]=p[j]; for(int j=0;j<n;j++) { r+=(rho[j]-1)*f(n-j-1); for(int i=j;i<n;i++) //对后面的元素遍历,若 < 则减 1 if(rho[i]>rho[j]) rho[i]--; } return r; }
由字典序值计算排列
对于每个整数 r ,0≤r≤n!-1,都有唯一的阶乘分解:r=Σ di * i ! , (0≤ di ≤ i , 1≤ i ≤n-1)
分析:此式相当于 rank(∏,n) = (∏[1]-1)*(n-1)! + rank(∏`,n-1) 的展开。
设r = rank(∏,n) , 则显然有∏[1] = dn-1 +1.
进一步,rank(∏',n-1) = r' = r - dn-1*(n-1)! 可递归地找到排列∏‘ 。
r = dn-1 * (n-1)!+dn-1 *(n-2)! +....+d0*(0)!
先得到尾项再得到前项. m=r%(1)! 此时会将{(n-1)!,n(n-2)!,(n-3)!,...,(1)!}带有这些的前项全部除掉,只剩下d0*(0)!,且 d0=r%(1)!/(0)! 递归向前得到d1,d2,...,dn-1.
void permUnrank(int n,int r,int *p) { p[n-1]=1; for(int j=0;j<n;j++) { int d =(r%f(j+1))/f(j); //将 (n+1)!>(n)! 的项全部去掉,只留下留下 dn*(n)! p[n-j-1]=d+1; r-=d*f(j); if(j==0) continue; for(int i=n-j;i<n;i++) //在之前减过的元素,重新+1 if(p[i]>=p[n-j-1])p[i]++; } }
由排列计算下一个排列
按字典序的定义可设计从一个排列计算下一个排列的算法。对于给定的排列∏,
(1)首先找到下标 i ,使得∏[ i ] < ∏[ i+1 ],且∏[ i +1] > ∏[ i+2 ] > ...> ∏[n];
(2)其次找到下标 j,使得∏[ i ]<∏[ j ]且对所有j<k≤n 有∏[k]<∏[ i ];
(3)然后交换∏[ i ] 和 ∏[ j ];
(4)最后将排列[∏[i+1],∏[i+2],...,∏[n] ]反转。
举例 :8 4 6 5 3 2 1
(1)首先从后向前遍历,若后段都是逆序,则此后段已经是最后的一个排列,必须从前面更换。
即:8 4 6 5 3 2 1,此排列是以84开始的排列的最后一个排列,下一个排列的不能再是84开始的.
此时的4 就是上边所记 i.
(2)此时不能从84开始,则必须从84的下一个开始,因为是字典序,所以要从后边找到比4大的数,则是5(不能是6,86就超越了85),而此时的5 就是上边所记j。
(3)交换 4 5
(4)此时为 8 5 6 4 3 2 1 ,按(1)理解,此排列应该是以85开始的最后一个排列,要想得到第一个排列的话,就应该反转后段6 4 3 2 1。
最后得到排列 8 5 1 2 3 4 6。
void permSucc(int n,int *p,int &flag) { p[0]=0; int i=n-1; while(p[i+1]<p[i])i--; // 得到 i if(i==0) flag=0; else{ flag=1; int j=n; while(p[j]<p[i])j--; // 得到 j swap(p[j],p[i]); // 交换 int rho[n-i]; for(int k=i+1;k<=n;k++) rho[k]=p[k]; //反转 for(int k=i+1;k<=n;k++) p[k]=rho[n-(k-i-1)]; } }














 1217
1217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









