






习题1:读入文件pmi_days.csv,完成以下操作:
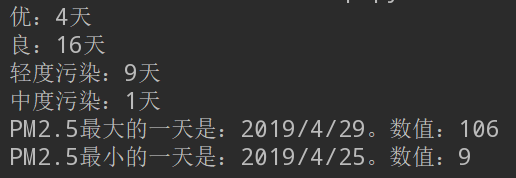
1.统计质量等级对应的天数,例如:
优:5天
良:3天
中度污染:2天
2.找出PMI2.5的最大值和最小值,分别指出是哪一天。
1 import pandas as pd 2 import numpy as np 3 4 days_path = open(r"C:\Users\Shinelon\Desktop\pmi_days.csv") 5 days_df = pd.read_csv(days_path) 6 7 # 统计质量等级对应的天数 8 data = days_df.groupby('质量等级') 9 10 11 day_you = dict([x for x in data])['优'] 12 day_liang = dict([x for x in data])['良'] 13 day_qing = dict([x for x in data])['轻度污染'] 14 day_zhong = dict([x for x in data])['中度污染'] 15 print("优:%d天" % len(day_you.index), "\n良:%d天" % len(day_liang.index), 16 "\n轻度污染:%d天" % len(day_qing.index), "\n中度污染:%d天" % len(day_zhong.index)) 17 18 19 # 找出PM2.5的最大值和最小值,分别指出是哪一天 20 sort_pm25 = days_df.sort_values(by='PM2.5') 21 sort_pm25_2 = sort_pm25.reset_index(drop=True) 22 print("PM2.5最大的一天是:%s。数值:%d" % (sort_pm25_2['日期'][29], sort_pm25_2['PM2.5'][29]), 23 "\nPM2.5最小的一天是:%s。数值:%d" % (sort_pm25_2['日期'][0], sort_pm25_2['PM2.5'][0]))
码云地址:https://gitee.com/BURY--18/Ch_18forever.git
习题2:读入文件1980-2018GDP.csv,完成以下操作:
1.按行输出每年GDP数据,表头列名如文件第1行所示。
2.将各年GDP数据转换成字典格式,以年份为keys,其它值为values(数据类型为列表方式),例如:
{
2017:[827121.7,6.8%,60989]
........
}
3.遍历字典数据,求出GDP的最小值与最大值,并输出数据与对应的年份。
1 import pandas as pd 2 3 days_path = open(r"C:\Users\Shinelon\Desktop\1980-2018GDP.csv") 4 days_list = pd.read_csv(days_path) 5 6 # 1.按行输出每年GDP数据 7 print(days_list, "\t\t\n") 8 9 10 # 2.将各年GDP数据转换成字典格式,以年份为keys,其它值为values(数据类型为列表方式) 11 dict_GDP = days_list.set_index('年份').T.to_dict('list') 12 print("字典:", dict_GDP, "\n") 13 14 15 # 3.遍历字典数据,求出GDP的最小值与最大值,并输出数据与对应的年份。 16 data_max = max(dict_GDP, key=dict_GDP.get) 17 data_min = min(dict_GDP, key=dict_GDP.get) 18 print("GDP最大值:", data_max, dict_GDP[data_max], "\n") 19 print("GDP最小值:", data_min, dict_GDP[data_min])
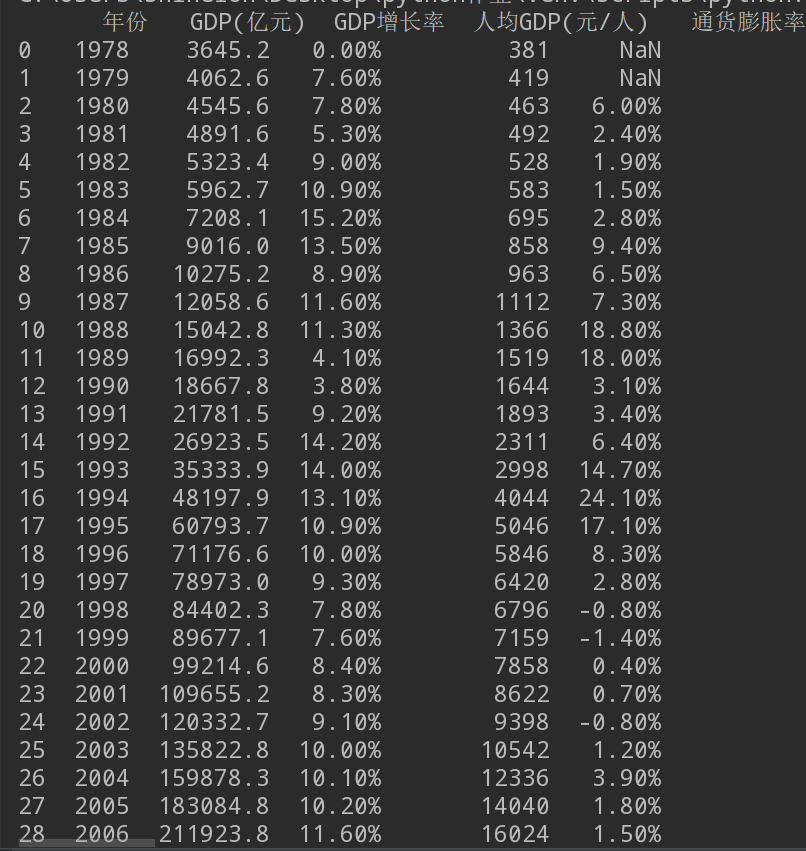
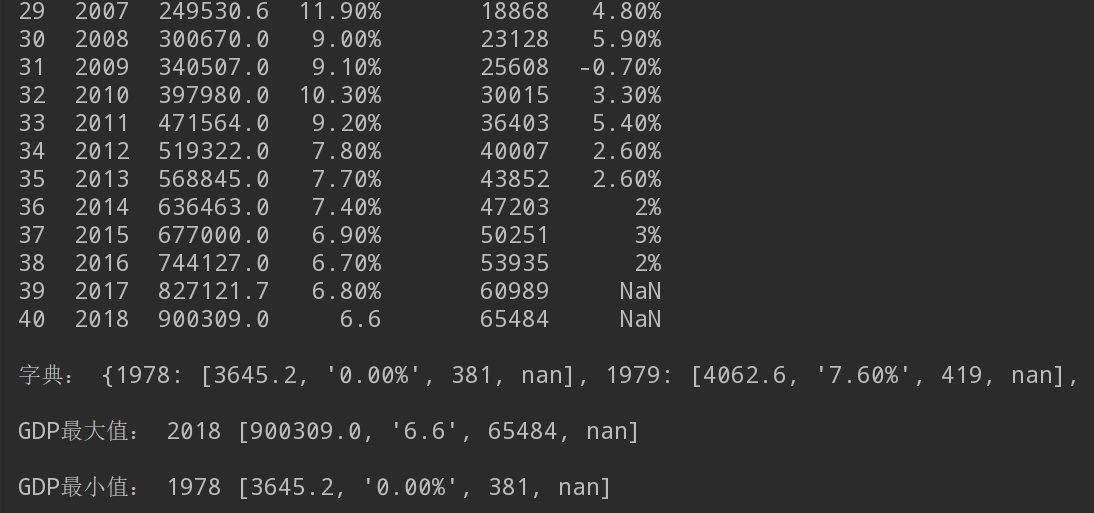
*由于字典太长,所以只截取了其中两个键值对。
码云地址:https://gitee.com/BURY--18/Ch_18forever.git
习题3:扩展(选作,二选一)
1.绘制每年的GDP数据的直方图,横坐标为年份,纵坐标为GDP值。
2.绘制每年的GDP数据的折线图,横坐标为年份,纵坐标为GDP值。
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 days_path = open(r"C:\Users\Shinelon\Desktop\1980-2018GDP.csv") 6 days_list = pd.read_csv(days_path) 7 8 # print(days_list) 9 plt.rcParams['font.sans-serif'] = ['SimHei'] # 默认字体 10 plt.rcParams['axes.unicode_minus'] = False # ”-“负号为方块问题 11 12 plt.figure(figsize=(30, 8)) 13 plt.xlim(1978, 2019) 14 plt.ylim(0, 1000000) 15 x_num = np.arange(1978, 2019, 1) 16 y_num = np.arange(0, 1000000, 50000) 17 plt.xticks(x_num) 18 plt.yticks(y_num) 19 20 # 1.绘制每年的GDP数据的直方图 21 plt.bar(days_list['年份'], days_list['GDP(亿元)'], label="GDP值", color='c') 22 # 2.绘制每年的GDP数据的折线图 23 plt.plot(days_list['年份'], days_list['GDP(亿元)'], label="GDP值", color='r') 24 25 plt.title('1980-2018年GDP数据统计图') 26 plt.xlabel('年份(年)') 27 plt.ylabel('GDP值(亿元)') 28 plt.legend(loc='upper right') 29 # plt.grid(True, alpha=0.5) 30 plt.show()
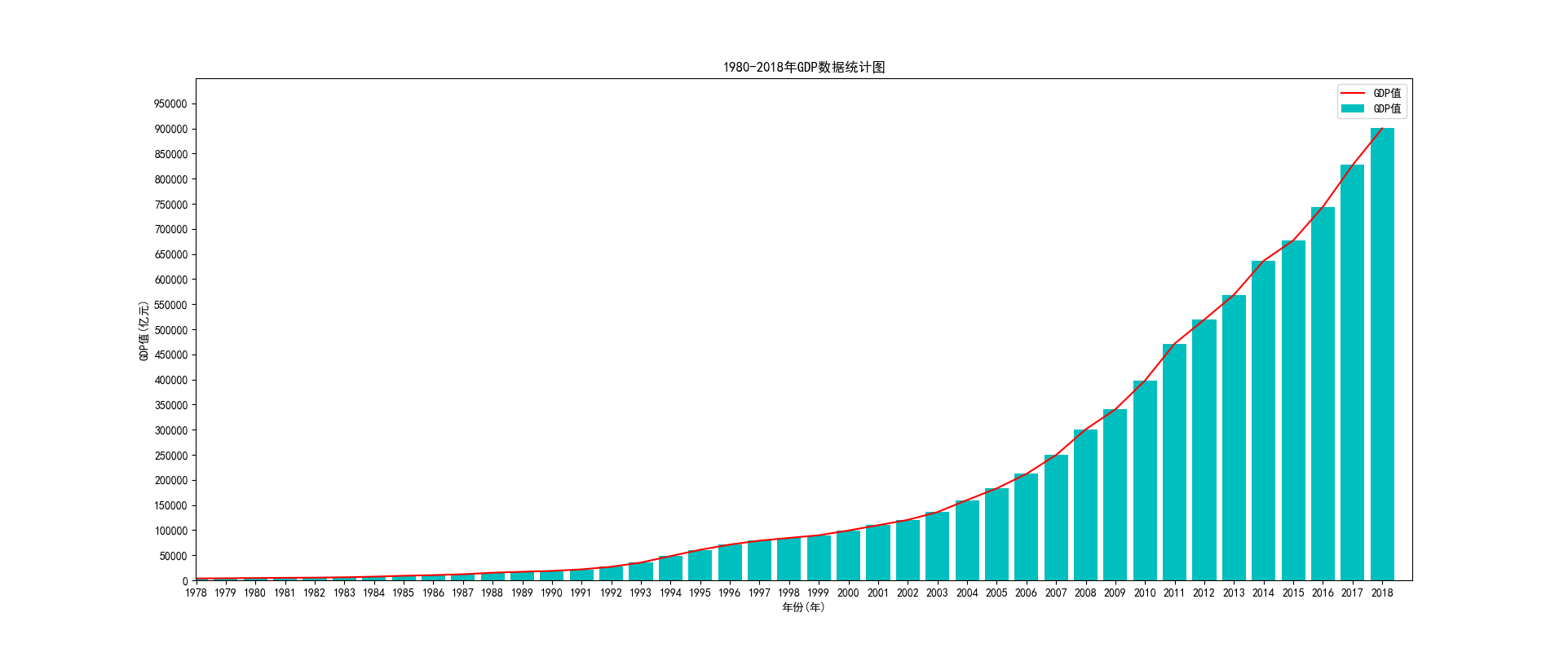
码云地址:https://gitee.com/BURY--18/Ch_18forever.git















 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









