






目前为止,我们已经讨论了神经网络在有监督学习中的应用。在有监督学习中,训练样本是有类别标签的。现在假设我们只有一个没有带类别标签的训练样本集合  ,其中
,其中  。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如
。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目标值等于输入值,比如  。下图是一个自编码神经网络的示例。
。下图是一个自编码神经网络的示例。

自编码神经网络尝试学习一个  的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出
的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出  接近于输入
接近于输入  。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张
。恒等函数虽然看上去不太有学习的意义,但是当我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 是一张  图像(共100个像素)的像素灰度值,于是
图像(共100个像素)的像素灰度值,于是  ,其隐藏层
,其隐藏层  中有50个隐藏神经元。注意,输出也是100维的
中有50个隐藏神经元。注意,输出也是100维的  。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量
。由于只有50个隐藏神经元,我们迫使自编码神经网络去学习输入数据的压缩表示,也就是说,它必须从50维的隐藏神经元激活度向量  中重构出100维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入
中重构出100维的像素灰度值输入 。如果网络的输入数据是完全随机的,比如每一个输入  都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
都是一个跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络通常可以学习出一个跟主元分析(PCA)结果非常相似的输入数据的低维表示。
我们刚才的论述是基于隐藏神经元数量较小的假设。但是即使隐藏神经元的数量较大(可能比输入像素的个数还要多),我们仍然通过给自编码神经网络施加一些其他的限制条件来发现输入数据中的结构。具体来说,如果我们给隐藏神经元加入稀疏性限制,那么自编码神经网络即使在隐藏神经元数量较多的情况下仍然可以发现输入数据中一些有趣的结构。
稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。这里我们假设的神经元的激活函数是sigmoid函数。如果你使用tanh作为激活函数的话,当神经元输出为-1的时候,我们认为神经元是被抑制的。
注意到  表示隐藏神经元
表示隐藏神经元  的激活度,但是这一表示方法中并未明确指出哪一个输入 带来了这一激活度。所以我们将使用
的激活度,但是这一表示方法中并未明确指出哪一个输入 带来了这一激活度。所以我们将使用  来表示在给定输入为 情况下,自编码神经网络隐藏神经元 的激活度。 进一步,让
来表示在给定输入为 情况下,自编码神经网络隐藏神经元 的激活度。 进一步,让
![\begin{align} \hat\rho_j = \frac{1}{m} \sum_{i=1}^m \left[ a^{(2)}_j(x^{(i)}) \right] \end{align}](https://i-blog.csdnimg.cn/blog_migrate/b16d345d9f10c34ad0494bf3e4600ba4.png)
表示隐藏神经元 的平均活跃度(在训练集上取平均)。我们可以近似的加入一条限制

其中,  是稀疏性参数,通常是一个接近于0的较小的值(比如
是稀疏性参数,通常是一个接近于0的较小的值(比如  )。换句话说,我们想要让隐藏神经元 的平均活跃度接近0.05。为了满足这一条件,隐藏神经元的活跃度必须接近于0。
)。换句话说,我们想要让隐藏神经元 的平均活跃度接近0.05。为了满足这一条件,隐藏神经元的活跃度必须接近于0。
为了实现这一限制,我们将会在我们的优化目标函数中加入一个额外的惩罚因子,而这一惩罚因子将惩罚那些  和 有显著不同的情况从而使得隐藏神经元的平均活跃度保持在较小范围内。惩罚因子的具体形式有很多种合理的选择,我们将会选择以下这一种:
和 有显著不同的情况从而使得隐藏神经元的平均活跃度保持在较小范围内。惩罚因子的具体形式有很多种合理的选择,我们将会选择以下这一种:

这里,  是隐藏层中隐藏神经元的数量,而索引 依次代表隐藏层中的每一个神经元。如果你对相对熵(KL divergence)比较熟悉,这一惩罚因子实际上是基于它的。于是惩罚因子也可以被表示为
是隐藏层中隐藏神经元的数量,而索引 依次代表隐藏层中的每一个神经元。如果你对相对熵(KL divergence)比较熟悉,这一惩罚因子实际上是基于它的。于是惩罚因子也可以被表示为

其中  是一个以 为均值和一个以 为均值的两个伯努利随机变量之间的相对熵。相对熵是一种标准的用来测量两个分布之间差异的方法。(如果你没有见过相对熵,不用担心,所有你需要知道的内容都会被包含在这份笔记之中。)
是一个以 为均值和一个以 为均值的两个伯努利随机变量之间的相对熵。相对熵是一种标准的用来测量两个分布之间差异的方法。(如果你没有见过相对熵,不用担心,所有你需要知道的内容都会被包含在这份笔记之中。)
这一惩罚因子有如下性质,当  时
时  ,并且随着 与 之间的差异增大而单调递增。举例来说,在下图中,我们设定
,并且随着 与 之间的差异增大而单调递增。举例来说,在下图中,我们设定  并且画出了相对熵值
并且画出了相对熵值  随着 变化的变化。
随着 变化的变化。

我们可以看出,相对熵在 时达到它的最小值0,而当 靠近0或者1的时候,相对熵则变得非常大(其实是趋向于 )。所以,最小化这一惩罚因子具有使得 靠近 的效果。 现在,我们的总体代价函数可以表示为
)。所以,最小化这一惩罚因子具有使得 靠近 的效果。 现在,我们的总体代价函数可以表示为

其中  如之前所定义,而
如之前所定义,而  控制稀疏性惩罚因子的权重。 项则也(间接地)取决于
控制稀疏性惩罚因子的权重。 项则也(间接地)取决于  ,因为它是隐藏神经元 的平均激活度,而隐藏层神经元的激活度取决于 。
,因为它是隐藏神经元 的平均激活度,而隐藏层神经元的激活度取决于 。
为了对相对熵进行导数计算,我们可以使用一个易于实现的技巧,这只需要在你的程序中稍作改动即可。具体来说,前面在后向传播算法中计算第二层(  )更新的时候我们已经计算了
)更新的时候我们已经计算了

现在我们将其换成

就可以了。
有一个需要注意的地方就是我们需要知道  来计算这一项更新。所以在计算任何神经元的后向传播之前,你需要对所有的训练样本计算一遍前向传播,从而获取平均激活度。如果你的训练样本可以小到被整个存到内存之中(对于编程作业来说,通常如此),你可以方便地在你所有的样本上计算前向传播并将得到的激活度存入内存并且计算平均激活度 。然后你就可以使用事先计算好的激活度来对所有的训练样本进行后向传播的计算。如果你的数据量太大,无法全部存入内存,你就可以扫过你的训练样本并计算一次前向传播,然后将获得的结果累积起来并计算平均激活度 (当某一个前向传播的结果中的激活度
来计算这一项更新。所以在计算任何神经元的后向传播之前,你需要对所有的训练样本计算一遍前向传播,从而获取平均激活度。如果你的训练样本可以小到被整个存到内存之中(对于编程作业来说,通常如此),你可以方便地在你所有的样本上计算前向传播并将得到的激活度存入内存并且计算平均激活度 。然后你就可以使用事先计算好的激活度来对所有的训练样本进行后向传播的计算。如果你的数据量太大,无法全部存入内存,你就可以扫过你的训练样本并计算一次前向传播,然后将获得的结果累积起来并计算平均激活度 (当某一个前向传播的结果中的激活度  被用于计算平均激活度 之后就可以将此结果删除)。然后当你完成平均激活度 的计算之后,你需要重新对每一个训练样本做一次前向传播从而可以对其进行后向传播的计算。对于后一种情况,你对每一个训练样本需要计算两次前向传播,所以在计算上的效率会稍低一些。
被用于计算平均激活度 之后就可以将此结果删除)。然后当你完成平均激活度 的计算之后,你需要重新对每一个训练样本做一次前向传播从而可以对其进行后向传播的计算。对于后一种情况,你对每一个训练样本需要计算两次前向传播,所以在计算上的效率会稍低一些。
证明上面算法能达到梯度下降效果的完整推导过程不再本教程的范围之内。不过如果你想要使用经过以上修改的后向传播来实现自编码神经网络,那么你就会对目标函数  做梯度下降。使用梯度验证方法,你可以自己来验证梯度下降算法是否正确。。
做梯度下降。使用梯度验证方法,你可以自己来验证梯度下降算法是否正确。。
上述公式推导过程:




参考链接:http://blog.csdn.net/itplus/article/details/11449055
对Sparse coding的补充介绍:
1.Sparse Coding:通俗的说,就是将一个信号表示为一组基的线性组合,而且要求只需要较少的几个基就可以将信号表示出来。而自然图像是个稀疏结构,即任何给定图像都可以用大数据里面的少数几个描述符(基)来表示。DL中的稀疏自编码器稀疏自编码器(Sparse Autoencoder)可以自动从无标注数据中学习特征,可以给出比原始数据更好的特征描述。在实际运用时可以用稀疏编码器发现的特征取代原始数据,这样往往能带来更好的结果。
2.稀疏性可以被简单地解释如下。如果当神经元的输出接近于1的时候我们认为它被激活,而输出接近于0的时候认为它被抑制,那么使得神经元大部分的时间都是被抑制的限制则被称作稀疏性限制。这里我们假设的神经元的激活函数是sigmoid函数(如果你使用tanh作为激活函数的话,当神经元输出为-1的时候,我们认为神经元是被抑制的)。可以通过L1来增加稀疏性。
3.自编码神经网路:它的本质是尝试学习一个  的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出
的函数。换句话说,它尝试逼近一个恒等函数,从而使得输出  接近于输入
接近于输入  。这样往往可以发现输入数据的一些有趣特征,最终我们会用隐藏层的神经元代替原始数据。
。这样往往可以发现输入数据的一些有趣特征,最终我们会用隐藏层的神经元代替原始数据。
它的优点如下:
(1)当隐藏神经元数目少于输入的数目时,自编码神经网络可以达到数据压缩的效果(因为最终我们可以用隐藏神经元替代原始输入,输入层的n个输入转换为隐藏层的m个神经元,其中n>m,之后隐藏层的m个神经元又转换为输出层的n个输出,其输出等于输入);当隐藏神经元数目较多时,我们仍然可以对隐藏层的神经元加入稀疏性限制来发现输入数据的有趣结构。
(2)用特征表示来代替原始数据(这些特征就是一组独立的基)
参考链接: http://www.cnblogs.com/guangmingyixuan/archive/2013/11/11/3418404.html(一篇介绍稀疏编码的前世今生的文章)
http://blog.csdn.net/u010278305/article/details/46881443
(突然发现sparse coding很有趣啊,大家有时间可以深入看一下)
编程过程如下:
1.实验基础:
其实实现该功能的主要步骤还是需要计算出网络的损失函数以及其偏导数,具体的公式可以参考前面的博文Deep learning:八(Sparse Autoencoder)。下面用简单的语言大概介绍下这个步骤,方便大家理清算法的流程。
1. 计算出网络每个节点的输入值(即程序中的z值)和输出值(即程序中的a值,a是z的sigmoid函数值)。
2. 利用z值和a值计算出网络每个节点的误差值(即程序中的delta值)。
3. 这样可以利用上面计算出的每个节点的a,z,delta来表达出系统的损失函数以及损失函数的偏导数了,当然这些都是一些数学推导,其公式就是前面的博文Deep learning:八(Sparse Autoencoder)了。
其实步骤1是前向进行的,也就是说按照输入层——》隐含层——》输出层的方向进行计算。而步骤2是方向进行的(这也是该算法叫做BP算法的来源),即每个节点的误差值是按照输出层——》隐含层——》输入层方向进行的。
一些malab函数:
bsxfun:
C=bsxfun(fun,A,B)表达的是两个数组A和B间元素的二值操作,fun是函数句柄或者m文件,或者是内嵌的函数。在实际使用过程中fun有很多选择比如说加,减等,前面需要使用符号’@’.一般情况下A和B需要尺寸大小相同,如果不相同的话,则只能有一个维度不同,同时A和B中在该维度处必须有一个的维度为1。比如说bsxfun(@minus, A, mean(A)),其中A和mean(A)的大小是不同的,这里的意思需要先将mean(A)扩充到和A大小相同,然后用A的每个元素减去扩充后的mean(A)对应元素的值。
rand:
生成均匀分布的伪随机数。分布在(0~1)之间
主要语法:rand(m,n)生成m行n列的均匀分布的伪随机数
rand(m,n,'double')生成指定精度的均匀分布的伪随机数,参数还可以是'single'
rand(RandStream,m,n)利用指定的RandStream(我理解为随机种子)生成伪随机数
randn:
生成标准正态分布的伪随机数(均值为0,方差为1)。主要语法:和上面一样
randi:
生成均匀分布的伪随机整数
主要语法:randi(iMax)在闭区间(0,iMax)生成均匀分布的伪随机整数
randi(iMax,m,n)在闭区间(0,iMax)生成mXn型随机矩阵
r = randi([iMin,iMax],m,n)在闭区间(iMin,iMax)生成mXn型随机矩阵
exist:
测试参数是否存在,比如说exist('opt_normalize', 'var')表示检测变量opt_normalize是否存在,其中的’var’表示变量的意思。
colormap:
设置当前常见的颜色值表。
floor:
floor(A):取不大于A的最大整数。
ceil:
ceil(A):取不小于A的最小整数。
imagesc:
imagesc和image类似,可以用于显示图像。比如imagesc(array,'EraseMode','none',[-1 1]),这里的意思是将array中的数据线性映射到[-1,1]之间,然后使用当前设置的颜色表进行显示。此时的[-1,1]充满了整个颜色表。背景擦除模式设置为node,表示不擦除背景。
repmat:
该函数是扩展一个矩阵并把原来矩阵中的数据复制进去。比如说B = repmat(A,m,n),就是创建一个矩阵B,B中复制了共m*n个A矩阵,因此B矩阵的大小为[size(A,1)*m size(A,2)*m]。
使用函数句柄的作用:
不使用函数句柄的情况下,对函数多次调用,每次都要为该函数进行全面的路径搜索,直接影响计算速度,借助句柄可以完全避免这种时间损耗。也就是直接指定了函数的指针。函数句柄就像一个函数的名字,有点类似于C++程序中的引用。
以上部分摘自博客:
http://www.cnblogs.com/tornadomeet/archive/2013/03/20/2970724.html
Andrew ng原文:http://deeplearning.stanford.edu/wiki/index.php/Exercise:Sparse_Autoencoder
源码以及数据:http://ufldl.stanford.edu/wiki/resources/sparseae_exercise.zip
2.程序过程解析
step0:参数初始化
visibleSize = 8*8; % 输入特征数,也是每个小图片的维数
hiddenSize = 25; % 隐层节点数
sparsityParam = 0.01; % 期望稀疏值
lambda = 0.0001; % 权值惩罚参数
beta = 3;
step1:调用sampleIMAGES函数,加载并处理数据
1)sampleIMAGE函数关键部分解析
for imageNum = 1:10%在每张图片中随机选取1000个patch,共10000个patch
[rowNum colNum] = size(IMAGES(:,:,imageNum));
for patchNum = 1:1000%实现每张图片选取1000个patch
xPos = randi([1,rowNum-patchsize+1]);%randi用于生产随机整数矩阵randi([min max],m,n)
yPos = randi([1, colNum-patchsize+1]);
patches(:,(imageNum-1)*1000+patchNum) = reshape(IMAGES(xPos:xPos+7,yPos:yPos+7,...
imageNum),64,1);%reshap函数,将8*8的方阵,变形为64*1的列向量
end
end
处理数据
patches = normalizeData(patches);normalizeData()函数先使用标准差使数据范围变为-1到1,之后再变换到[0.1,0.9],以便和sigmoid函数输出值匹配
2)initializeParameters函数
通过输入层和隐层节点数,初始化权值矩阵和偏置项矩阵。
初始化权值矩阵是,是通过在[-r, r]区间内随机初始化矩阵r = sqrt(6) / sqrt(hiddenSize+visibleSize+1)=0.2582;(这个我不不清楚为啥,只知道Andrew教程中权值初始值要随机,且随机数值不应过大)
theta = [W1(:) ; W2(:) ; b1(:) ; b2(:)];把矩阵向量化,通过向量来传递参数;个人猜测应该是通过向量传参效率高
STEP 2: 实现 sparseAutoencoderCost,稀疏损失函数
1)通过反转向量,把向量还原为权值矩阵
2)计算损失函数和梯度
由于画图和矩阵的原因,原稿使用ppt来制作的,现在就只能通过贴图的方式展现了,有需要ppt的可以私信我
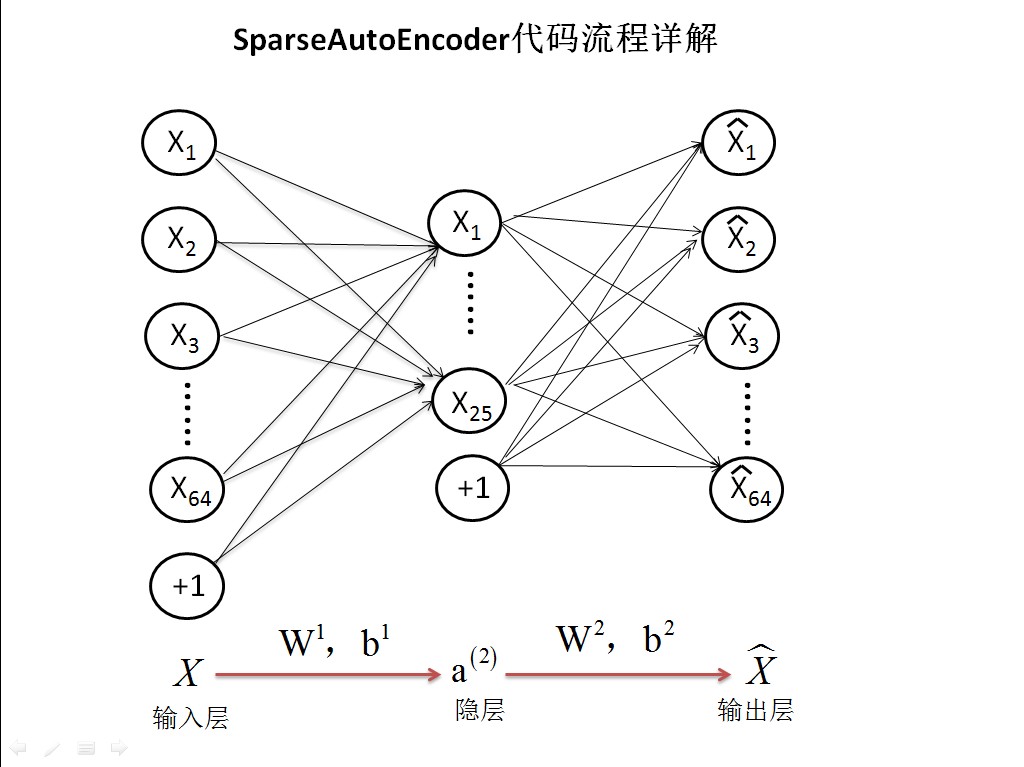
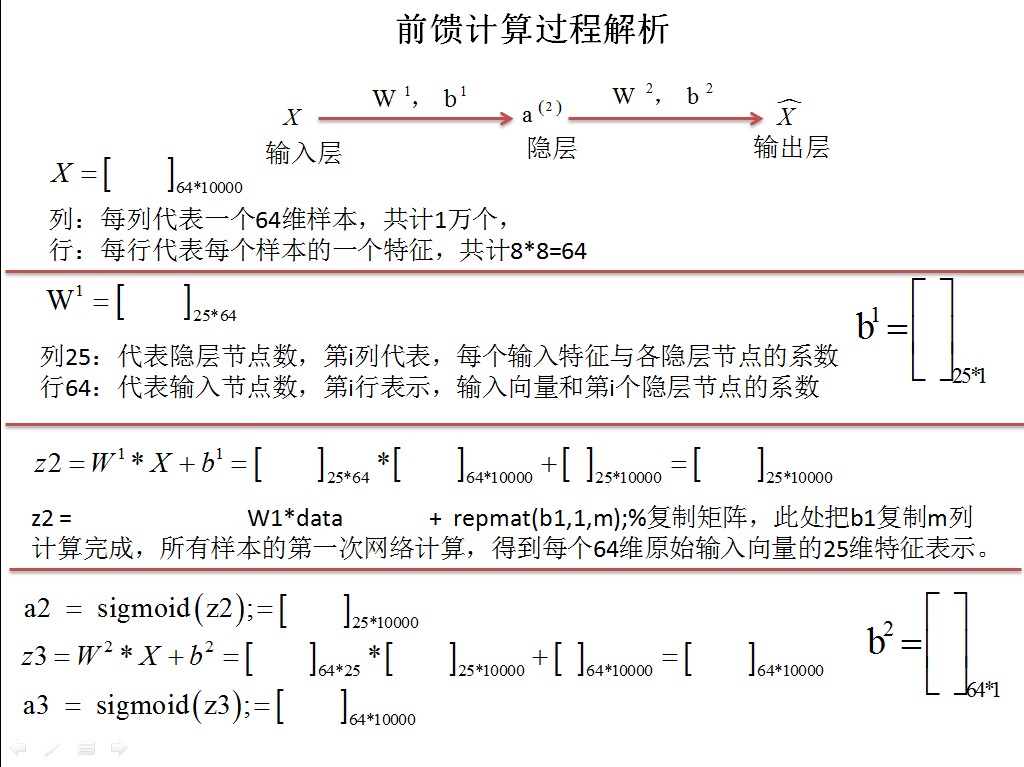




最后把矩阵权值向量化,当做参数传递出来
grad = [W1grad(:) ; W2grad(:) ; b1grad(:) ; b2grad(:)];
STEP 3: 通过l-bfgs算法优化
STEP4:可视化学习到的权值矩阵W1.















 2277
2277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









