






1、String类为什么是final的
final的目的是不能改变,出于安全和效率的考虑。final修饰类时,类不可被继承;修饰变量,变量的值不可以被修改;修饰方法,方法不可被子类重写。如果有一个String的引用,它引用的一定是一个String对象,而不可能是其他类的对象。String 一旦被创建是不能被修改的,因为设计者将 String 设计为可以共享的。设计成final,JVM才不用对相关方法在虚函数表中查询,而直接定位到String类的相关方法上,提高了执行效率。 Java设计者认为共享带来的效率更高。总而言之,就是要保证 java.lang.String 引用的对象一定是 java.lang.String的对象,而不是引用它的子孙类,这样才能保证它的效率和安全。
2、HashMap的源码,实现原理,底层结构。
HashMap的实现原理:首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,同一各链表上的Hash值是相同的,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率。当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩大2倍,把原链表数组的搬移到新的数组中。
在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
JDK1.8中的数据结构:
(1)位桶结构
transient Node<k,v>[] table;//存储(位桶)的数组</k,v>
(2)数组元素Node<k,v>实现了Entry接口
//Node是单向链表,它实现了Map.Entry接口
static
class
Node<k,v>
implements
Map.Entry<k,v> {
final
int
hash;
final
K key;
V value;
Node<k,v> next;
//构造函数Hash值 键 值 下一个节点
Node(
int
hash, K key, V value, Node<k,v> next) {
this
.hash = hash;
this
.key = key;
this
.value = value;
this
.next = next;
}
public
final
K getKey() {
return
key; }
public
final
V getValue() {
return
value; }
public
final
String toString() {
return
key + = + value; }
public
final
int
hashCode() {
return
Objects.hashCode(key) ^ Objects.hashCode(value);
}
public
final
V setValue(V newValue) {
V oldValue = value;
value = newValue;
return
oldValue;
}
//判断两个node是否相等,若key和value都相等,返回true。可以与自身比较为true
public
final
boolean
equals(Object o) {
if
(o ==
this
)
return
true
;
if
(o
instanceof
Map.Entry) {
Map.Entry<!--?,?--> e = (Map.Entry<!--?,?-->)o;
if
(Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return
true
;
}
return
false
;
}</k,v></k,v></k,v></k,v>
//红黑树
static
final
class
TreeNode<k,v>
extends
LinkedHashMap.Entry<k,v> {
TreeNode<k,v> parent;
// 父节点
TreeNode<k,v> left;
//左子树
TreeNode<k,v> right;
//右子树
TreeNode<k,v> prev;
// needed to unlink next upon deletion
boolean
red;
//颜色属性
TreeNode(
int
hash, K key, V val, Node<k,v> next) {
super
(hash, key, val, next);
}
//返回当前节点的根节点
final
TreeNode<k,v> root() {
for
(TreeNode<k,v> r =
this
, p;;) {
if
((p = r.parent) ==
null
)
return
r;
r = p;
}
}</k,v></k,v></k,v></k,v></k,v></k,v></k,v></k,v></k,v>
一组"对立"的元素,通常这些元素都服从某种规则
1.1) List必须保持元素特定的顺序
1.2) Set不能有重复元素
1.3) Queue保持一个队列(先进先出)的顺序
2) Map
一组成对的"键值对"对象
2) Map保存的是"键值对",就像一个小型数据库。我们可1. Interface Iterable
迭代器接口,这是Collection类的父接口。实现这个Iterable接口的对象允许使用foreach进行遍历,也就是说,所有的Collection集合对象都具有"foreach可遍历性"。这个Iterable接口只
有一个方法: iterator()。它返回一个代表当前集合对象的泛型<T>迭代器,用于之后的遍历操作
1.1 Collection
Collection是最基本的集合接口,一个Collection代表一组Object的集合,这些Object被称作Collection的元素。Collection是一个接口,用以提供规范定义,不能被实例化使用
1) Set
Set集合类似于一个罐子,"丢进"Set集合里的多个对象之间没有明显的顺序。Set继承自Collection接口,不能包含有重复元素(记住,这是整个Set类层次的共有属性)。
Set判断两个对象相同不是使用"=="运算符,而是根据equals方法。也就是说,我们在加入一个新元素的时候,如果这个新元素对象和Set中已有对象进行注意equals比较都返回false,
则Set就会接受这个新元素对象,否则拒绝。
因为Set的这个制约,在使用Set集合的时候,应该注意两点:1) 为Set集合里的元素的实现类实现一个有效的equals(Object)方法、2) 对Set的构造函数,传入的Collection参数不能包
含重复的元素
1.1) HashSet
HashSet是Set接口的典型实现,HashSet使用HASH算法来存储集合中的元素,因此具有良好的存取和查找性能。当向HashSet集合中存入一个元素时,HashSet会调用该对象的
hashCode()方法来得到该对象的hashCode值,然后根据该HashCode值决定该对象在HashSet中的存储位置。
值得主要的是,HashSet集合判断两个元素相等的标准是两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法的返回值相等
1.1.1) LinkedHashSet
LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但和HashSet不同的是,它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。
当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。
LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时(遍历)将有很好的性能(链表很适合进行遍历)
1.2) SortedSet
此接口主要用于排序操作,即实现此接口的子类都属于排序的子类
1.2.1) TreeSet
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态
1.3) EnumSet
EnumSet是一个专门为枚举类设计的集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式、或隐式地指定。EnumSet的集合元素也是有序的,
它们以枚举值在Enum类内的定义顺序来决定集合元素的顺序
2) List
List集合代表一个元素有序、可重复的集合,集合中每个元素都有其对应的顺序索引。List集合允许加入重复元素,因为它可以通过索引来访问指定位置的集合元素。List集合默认按元素
的添加顺序设置元素的索引
2.1) ArrayList
ArrayList是基于数组实现的List类,它封装了一个动态的增长的、允许再分配的Object[]数组。
2.2) Vector
Vector和ArrayList在用法上几乎完全相同,但由于Vector是一个古老的集合,所以Vector提供了一些方法名很长的方法,但随着JDK1.2以后,java提供了系统的集合框架,就将
Vector改为实现List接口,统一归入集合框架体系中
2.2.1) Stack
Stack是Vector提供的一个子类,用于模拟"栈"这种数据结构(LIFO后进先出)
2.3) LinkedList
implements List<E>, Deque<E>。实现List接口,能对它进行队列操作,即可以根据索引来随机访问集合中的元素。同时它还实现Deque接口,即能将LinkedList当作双端队列
使用。自然也可以被当作"栈来使用"
3) Queue
Queue用于模拟"队列"这种数据结构(先进先出 FIFO)。队列的头部保存着队列中存放时间最长的元素,队列的尾部保存着队列中存放时间最短的元素。新元素插入(offer)到队列的尾部,
访问元素(poll)操作会返回队列头部的元素,队列不允许随机访问队列中的元素。结合生活中常见的排队就会很好理解这个概念
3.1) PriorityQueue
PriorityQueue并不是一个比较标准的队列实现,PriorityQueue保存队列元素的顺序并不是按照加入队列的顺序,而是按照队列元素的大小进行重新排序,这点从它的类名也可以
看出来
3.2) Deque
Deque接口代表一个"双端队列",双端队列可以同时从两端来添加、删除元素,因此Deque的实现类既可以当成队列使用、也可以当成栈使用
3.2.1) ArrayDeque
是一个基于数组的双端队列,和ArrayList类似,它们的底层都采用一个动态的、可重分配的Object[]数组来存储集合元素,当集合元素超出该数组的容量时,系统会在底层重
新分配一个Object[]数组来存储集合元素
3.2.2) LinkedList
1.2 Map
Map用于保存具有"映射关系"的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value。key和value都可以是任何引用类型的数据。Map的key不允
许重复,即同一个Map对象的任何两个key通过equals方法比较结果总是返回false。
关于Map,我们要从代码复用的角度去理解,java是先实现了Map,然后通过包装了一个所有value都为null的Map就实现了Set集合
Map的这些实现类和子接口中key集的存储形式和Set集合完全相同(即key不能重复)
Map的这些实现类和子接口中value集的存储形式和List非常类似(即value可以重复、根据索引来查找)
1) HashMap
和HashSet集合不能保证元素的顺序一样,HashMap也不能保证key-value对的顺序。并且类似于HashSet判断两个key是否相等的标准也是: 两个key通过equals()方法比较返回true、
同时两个key的hashCode值也必须相等
1.1) LinkedHashMap
LinkedHashMap也使用双向链表来维护key-value对的次序,该链表负责维护Map的迭代顺序,与key-value对的插入顺序一致(注意和TreeMap对所有的key-value进行排序进行区
分)
2) Hashtable
是一个古老的Map实现类
2.1) Properties
Properties对象在处理属性文件时特别方便(windows平台上的.ini文件),Properties类可以把Map对象和属性文件关联起来,从而可以把Map对象中的key-value对写入到属性文
件中,也可以把属性文件中的"属性名-属性值"加载到Map对象中
3) SortedMap
正如Set接口派生出SortedSet子接口,SortedSet接口有一个TreeSet实现类一样,Map接口也派生出一个SortedMap子接口,SortedMap接口也有一个TreeMap实现类
3.1) TreeMap
TreeMap就是一个红黑树数据结构,每个key-value对即作为红黑树的一个节点。TreeMap存储key-value对(节点)时,需要根据key对节点进行排序。TreeMap可以保证所有的
key-value对处于有序状态。同样,TreeMap也有两种排序方式: 自然排序、定制排序
4) WeakHashMap
WeakHashMap与HashMap的用法基本相似。区别在于,HashMap的key保留了对实际对象的"强引用",这意味着只要该HashMap对象不被销毁,该HashMap所引用的对象就不会被垃圾回收。
但WeakHashMap的key只保留了对实际对象的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,当垃
圾回收了该key所对应的实际对象之后,WeakHashMap也可能自动删除这些key所对应的key-value对
5) IdentityHashMap
IdentityHashMap的实现机制与HashMap基本相似,在IdentityHashMap中,当且仅当两个key严格相等(key1 == key2)时,IdentityHashMap才认为两个key相等
6) EnumMap
EnumMap是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。创建EnumMap时必须显式或隐式指定它对应的枚举类。EnumMap根据key的自然顺序
(即枚举值在枚举类中的定义顺序)以通过"键"找到该键对应的"值"
对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。 这一点我做了实验。在分别有200000条“记录”的ArrayList和LinkedList的首位插入20000条数据,LinkedList耗时约是ArrayList的20分之1。
查找操作indexOf,lastIndexOf,contains等,两者差不多。
随机查找指定节点的操作get,ArrayList速度要快于LinkedList.
这里只是理论上分析,事实上也不一定,ArrayList在末尾插入和删除数据的话,速度反而比LinkedList要快。
http://blog.csdn.net/qianzhiyong111/article/details/6678035
5、Java中的队列都有哪些,有什么区别
在java5中新增加了java.util.Queue接口,用以支持队列的常见操作。Queue接口与List、Set同一级别,都是继承了Collection接口。 Queue使用时要尽量避免Collection的add()和remove()方法,而是要使用offer()来加入元素,使用poll()来获取并移出元素。它们的优 点是通过返回值可以判断成功与否,add()和remove()方法在失败的时候会抛出异常。 如果要使用前端而不移出该元素,使用 element()或者peek()方法。 值得注意的是LinkedList类实现了Queue接口,因此我们可以把LinkedList当成Queue来用。
LinkedList实现了Queue接口。Queue接口窄化了对LinkedList的方法的访问权限(即在方法中的参数类型如果是Queue时,就完全只能访问Queue接口所定义的方法 了,而不能直接访问 LinkedList的非Queue的方法),以使得只有恰当的方法才可以使用。BlockingQueue 继承了Queue接口
http://blog.sina.com.cn/s/blog_566fd08d0101fwcr.html
6、反射中,Class.forName和classloader的区别。
首先这个问题,没有固定答案,全看个人理解,毕竟这2个的数据结构,大家肯定都是知道的。能有如下回答,基本就够用啦。
数组: 数组就像一个班级一样,一旦分完班,一个班多少人,每个人的学号啥的都是确定的啦,根据学号,喊一个学号就会有个人中, 这个学号就是下标,根据下标找人就是快。单个之间关系不大 链表: 链表就像一个铁链,一环扣一环,不能跳过一个,直接去找下一个,必须挨个找,根据节点的next的指向,查找,要查找就得一个个查。
(1) 从逻辑结构角度来看 a, 数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费。 b,链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项) (2)从内存存储角度来看 a,(静态)数组从栈中分配空间(这个有待确定,毕竟是Java的数组), 对于程序员方便快速,但自由度小。 b, 链表从堆中分配空间, 自由度大但申请管理比较麻烦.
数组和链表的区别整理如下:
数组静态分配内存,链表动态分配内存; 数组在内存中连续,链表不连续; 数组元素在栈区,链表元素在堆区; 数组利用下标定位,时间复杂度为O(1),链表定位元素时间复杂度O(n); 数组插入或删除元素的时间复杂度O(n),链表的时间复杂度O(1)。
9、Java内存泄露的问题调查定位:jmap,jstack的使用等等。
http://blog.csdn.net/gzh0222/article/details/8538727
http://www.open-open.com/lib/view/open1390916852007.html
10、string、stringbuilder、stringbuffer区别
http://www.cnblogs.com/xudong-bupt/p/3961159.html
http://blog.csdn.net/clam_clam/article/details/6831345
11、hashtable和hashmap的区别
http://www.cnblogs.com/carbs/archive/2012/07/04/2576995.html
12、异常的结构,运行时异常和非运行时异常,各举个例子。http://blog.csdn.net/qq_27093465/article/details/52268531
13、String 类的常用方法
http://gao851214.blog.163.com/blog/static/344574752013124115841575/
.ToLower() //转为小写字符串"AbC"-->"abc"
.ToUpper() //转为大写"AbC" -->"ABC"
.Trim() //去掉字符串首尾的空格" abc "-->"abc"
Equals(string value,StringComparison comparisonType); //相等判断
CompareTo(string value) //与value比较大小
.Split(params char [] separator) //separator 是分隔字符,如:','、'|' 等等。
.Split(char [] separator ,StringSplitOptions splitOpt)//StringSplitOptions.RemoveEmptyEntries
.Split(string[] separator,StringSplitOptions splitOpt)// 按字符串分隔
.Replace(char oldChar,char newChar) //替换字符串中的字符,如:'a'替换为'b'
.Replace(string oldStr,string newStr)//替换字符串中的字符串,如:"李时珍"替换为"李秀丽"
.SubString(int startIndex) //从指定序号开始,一直到最后,组成的字符串
.SubString(int startIndex,int length) //从指定序号startIndex,连续取length个,如果超过长度会报异常
.Contains(char c) // 是否包含 字符
.Contains(string str) // 是否包含 子字符串
.StartsWith(string str) //是否以str开头,如:http://baidu.com就以http://开头
.EndsWith(string str) //是否以str结尾
IndexOf(char c) //找到第一个字符c的index,如果没找到返回-1
.IndexOf(string str) //找到第一个字符串str的位置
14、 Java 的引用类型有哪几种
http://blog.csdn.net/yxpjx/article/details/6171868
在JDK 1.2以前的版本中,若一个对象不被任何变量引用,那么程序就无法再使用这个对象。也就是说,只有对象处于可触及(reachable)状态,程序才能使用它。从JDK 1.2版本开始,把对象的引用分为4种级别,从而使程序能更加灵活地控制对象的生命周期。这4种级别由高到低依次为:强引用、软引用、弱引用和虚引用。
⑴强引用(StrongReference) 强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。 ps:强引用其实也就是我们平时A a = new A()这个意思。
⑵软引用(SoftReference) 如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存(下文给出示例)。 软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。
⑶弱引用(WeakReference) 弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
⑷虚引用(PhantomReference) “虚引用”顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。 虚引用主要用来跟踪对象被垃圾回收器回收的活动。虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之 关联的引用队列中。
ReferenceQueue queue = new ReferenceQueue ();
PhantomReference pr = new PhantomReference (object, queue);
程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
15、抽象类和接口的区别
http://www.cnblogs.com/azai/archive/2009/11/10/1599584.html
1.abstract class 在 Java 语言中表示的是一种继承关系,一个类只能使用一次继承关系。但是,一个类却可以实现多个interface。
2.在abstract class 中可以有自己的数据成员,也可以有非abstarct的成员方法,而在interface中,只能够有静态的不能被修改的数据成员(也就是必须是static final的,不过在 interface中一般不定义数据成员),所有的成员方法都是abstract的。
3.abstract class和interface所反映出的设计理念不同。其实abstract class表示的是"is-a"关系,interface表示的是"like-a"关系。
4.实现抽象类和接口的类必须实现其中的所有方法。抽象类中可以有非抽象方法。接口中则不能有实现方法。
5.接口中定义的变量默认是public static final 型,且必须给其初值,所以实现类中不能重新定义,也不能改变其值。
6.抽象类中的变量默认是 friendly 型,其值可以在子类中重新定义,也可以重新赋值。
7.接口中的方法默认都是 public,abstract 类型的。
结论abstract class 和 interface 是 Java语言中的两种定义抽象类的方式,它们之间有很大的相似性。但是对于它们的选择却又往往反映出对于问题领域中的概 念本质的理解、对于设计意图的反映是否正确、合理,因为它们表现了概念间的不同的关系(虽然都能够实现需求的功能)。这其实也是语言的一种的惯用法,希望读者朋友能够细细体会。
16、 java的基础类型和字节大小
Int: 4 字节 Short: 2字节 Long: 8字节 Byte: 1字节 Character: 2字节 Float: 4字节 Double: 8字节Boolean:系统没有提供Size方法;http://www.cnblogs.com/doit8791/archive/2012/05/25/2517448.html
17、Hashtable,HashMap,ConcurrentHashMap底层实现原理与线程安全问题。
http://blog.csdn.net/qq_27093465/article/details/52279473
18、如果不让你用Java Jdk提供的工具,你自己实现一个Map,你怎么做。
说了好久,说了HashMap源代码,如果我做,就会借鉴HashMap的原理,说了一通HashMap实现。
http://www.cnblogs.com/xwdreamer/archive/2012/05/14/2499339.html
http://www.importnew.com/7099.html
HashMap是基于哈希表的Map接口的非同步实现。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,HashMap也不例外。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
HashMap的功能是通过“键(key)”能够快速的找到“值”。下面我们分析下HashMap存数据的基本流程:
1、 当调用put(key,value)时,首先获取key的hashcode,int hash = key.hashCode();
2、 再把hash通过一下运算得到一个int h.
hash ^= (hash >>> 20) ^ (hash>>> 12);
int h = hash ^ (hash >>> 7) ^ (hash>>> 4);
为什么要经过这样的运算呢?这就是HashMap的高明之处。先看个例子,一个十进制数32768(二进制1000 0000 0000 0000),经过上述公式运算之后的结果是35080(二进制1000 1001 0000 1000)。看出来了吗?或许这样还看不出什么,再举个数字61440(二进制1111 0000 0000 0000),运算结果是65263(二进制1111 1110 1110 1111),现在应该很明显了,它的目的是让“1”变的均匀一点,散列的本意就是要尽量均匀分布。那这样有什么意义呢?看第3步。
3、 得到h之后,把h与HashMap的承载量(HashMap的默认承载量length是16,可以自动变长。在构造HashMap的时候也可以指定一个长 度。这个承载量就是上图所描述的数组的长度。)进行逻辑与运算,即 h & (length-1),这样得到的结果就是一个比length小的正数,我们把这个值叫做index。其实这个index就是索引将要插入的值在数组中的 位置。第2步那个算法的意义就是希望能够得出均匀的index,这是HashTable的改进,HashTable中的算法只是把key的 hashcode与length相除取余,即hash % length,这样有可能会造成index分布不均匀。还有一点需要说明,HashMap的键可以为null,它的值是放在数组的第一个位置。
4、 我们用table[index]表示已经找到的元素需要存储的位置。先判断该位置上有没有元素(这个元素是HashMap内部定义的一个类Entity, 基本结构它包含三个类,key,value和指向下一个Entity的next),没有的话就创建一个Entity<k,v>对象,在 table[index]位置上插入,这样插入结束;如果有的话,通过链表的遍历方式去逐个遍历,看看有没有已经存在的key,有的话用新的value替 换老的value;如果没有,则在table[index]插入该Entity,把原来在table[index]位置上的Entity赋值给新的 Entity的next,这样插入结束。
总结:keyàhashcodeàhàindexà遍历链表à插入
http://www.360doc.com/content/10/1214/22/573136_78200435.shtml
19、Hash冲突怎么办?哪些解决散列冲突的方法?
一)哈希表简介
非哈希表的特点:关键字在表中的位置和它之间不存在一个确定的关系,查找的过程为给定值一次和各个关键字进行比较,查找的效率取决于和给定值进行比较的次数。
哈希表的特点:关键字在表中位置和它之间存在一种确定的关系。
哈希函数:一般情况下,需要在关键字与它在表中的存储位置之间建立一个函数关系,以f(key)作为关键字为key的记录在表中的位置,通常称这个函数f(key)为哈希函数。
hash : 翻译为“散列”,就是把任意长度的输入,通过散列算法,变成固定长度的输出,该输出就是散列值。
这种转换是一种压缩映射,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。
简单的说就是一种将任意长度的消息压缩到莫伊固定长度的消息摘要的函数。
hash冲突:(大师兄自己写的哦)就是根据key即经过一个函数f(key)得到的结果的作为地址去存放当前的key value键值对(这个是hashmap的存值方式),但是却发现算出来的地址上已经有人先来了。就是说这个地方要挤一挤啦。这就是所谓的hash冲突啦
二)哈希函数处理冲突的方法
开放地址法 基本思想:当发生地址冲突时,按照某种方法继续探测Hash表中其它存储单元,直到找到空位置为止。描述如下
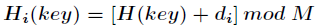
其中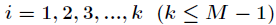
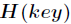
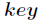
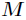
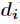
每次再探测时的地址增量。根据
线性探测再散列
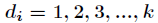
二次探测再散列
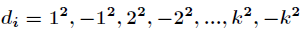
伪随机再散列 
(2)拉链法 拉链法又叫链地址法,适合处理冲突比较严重的情况。基本思想是把所有关键字为同义词的记录存储在同一个 线性链表中。
(3)再哈希法
再哈希法又叫双哈希法,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,....,等哈希函数
计算地址,直到无冲突。虽然不易发生聚集,但是增加了计算时间。
(4)建立公共溢出区
建立公共溢出区的基本思想是:假设哈希函数的值域是[1,m-1],则设向量HashTable[0...m-1]为基本
表,每个分量存放一个记录,另外设向量OverTable[0...v]为溢出表,所有关键字和基本表中关键字为同义
词的记录,不管它们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表。
http://blog.csdn.net/qq_27093465/article/details/52269862
Java NIO非堵塞应用通常适用用在I/O读写等方面,我们知道,系统运行的性能瓶颈通常在I/O读写,包括对端口和文件的操作上,过去,在打开一个I/O通道后,read()将一直等待在端口一边读取字节内容,如果没有内容进来,read()也是傻傻的等,这会影响我们程序继续做其他事情,那么改进做法就是开设线程,让线程去等待,但是这样做也是相当耗费资源的。
Java NIO非堵塞技术实际是采取Reactor模式,或者说是Observer模式为我们监察I/O端口,如果有内容进来,会自动通知我们,这样,我们就不必开启多个线程死等,从外界看,实现了流畅的I/O读写,不堵塞了。
Java NIO出现不只是一个技术性能的提高,你会发现网络上到处在介绍它,因为它具有里程碑意义,从JDK1.4开始,Java开始提高性能相关的功能,从而使得Java在底层或者并行分布式计算等操作上已经可以和C或Perl等语言并驾齐驱。
如果你至今还是在怀疑Java的性能,说明你的思想和观念已经完全落伍了,Java一两年就应该用新的名词来定义。从JDK1.5开始又要提供关于线程、并发等新性能的支持,Java应用在游戏等适时领域方面的机会已经成熟,Java在稳定自己中间件地位后,开始蚕食传统C的领域。
NIO主要原理和适用。
NIO 有一个主要的类Selector,这个类似一个观察者,只要我们把需要探知的socketchannel告诉Selector,我们接着做别的事情,当有事件发生时,他会通知我们,传回一组SelectionKey,我们读取这些Key,就会获得我们刚刚注册过的socketchannel,然后,我们从这个Channel中读取数据,放心,包准能够读到,接着我们可以处理这些数据。
Selector内部原理实际是在做一个对所注册的channel的轮询访问,不断的轮询(目前就这一个算法),一旦轮询到一个channel有所注册的事情发生,比如数据来了,他就会站起来报告,交出一把钥匙,让我们通过这把钥匙来读取这个channel的内容。
http://ifeve.com/overview/
25、 String 编码UTF-8 和GBK的区别?
UTF-8:Unicode TransformationFormat-8bit,允许含BOM,但通常不含BOM。是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24为(三个字节)来编码。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。UTF-8编码的文字可以在各国支持UTF8字符集的浏览器上显示。如,如果是UTF8编码,则在外国人的英文IE上也能显示中文,他们无需下载IE的中文语言支持包。
GBK是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBD大。
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:
GBK、GB2312--Unicode--UTF8
UTF8--Unicode--GBK、GB2312
对于一个网站、论坛来说,如果英文字符较多,则建议使用UTF-8节省空间。不过现在很多论坛的插件一般只支持GBK。
个编码的区别详细解释
简单来说,unicode,gbk和大五码就是编码的值,而utf-8,uft-16之类就是这个值的表现形式.而前面那三种编码是一兼容的,同一个汉字,那三个码值是完全不一样的.如"汉"的uncode值与gbk就是不一样的,假设uncode为a040,gbk为b030,而uft-8码,就是把那个值表现的形式.utf-8码完全只针对uncode来组织的,如果GBK要转UTF-8必须先转uncode码,再转utf-8就OK了.
26、什么时候使用字节流、什么时候使用字符流?
字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,所以它对多国语言支持性比较好!如果是音频文件、图片、歌曲,就用字节流好点,如果是关系到中文(文本)的,用字符流好点.
所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。在读取文件(特别是文本文件)时,也是一个字节一个字节地读取以形成字节序列.
字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串; 2.
字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以。
27、递归读取文件夹下的文件,代码怎么实现?http://www.360doc.com/content/10/0518/00/1121193_28143533.shtml
/**
* 递归读取文件夹下的 所有文件
*
* @param testFileDir 文件名或目录名
*/
private static void testLoopOutAllFileName(String testFileDir) {
if (testFileDir == null) {
//因为new File(null)会空指针异常,所以要判断下
return;
}
File[] testFile = new File(testFileDir).listFiles();
if (testFile == null) {
return;
}
for (File file : testFile) {
if (file.isFile()) {
System.out.println(file.getName());
} else if (file.isDirectory()) {
System.out.println("-------this is a directory, and its files are as follows:-------");
testLoopOutAllFileName(file.getPath());
} else {
System.out.println("文件读入有误!");
}
}
}
28、session和cookie的区别和联系,session的生命周期,多个服务部署时session管理。
二者的定义:
当你在浏览网站的时候,WEB 服务器会先送一小小资料放在你的计算机上,Cookie 会帮你在网站上所打的文字或是一些选择,都纪录下来。当下次你再光临同一个网站,WEB 服务器会先看看有没有它上次留下的 Cookie 资料,有的话,就会依据 Cookie
里的内容来判断使用者,送出特定的网页内容给你。 Cookie 的使用很普遍,许多有提供个人化服务的网站,都是利用 Cookie来辨认使用者,以方便送出使用者量身定做的内容,像是 Web 接口的免费 email 网站,都要用到 Cookie。具体来说cookie机制采用的是在客户端保持状态的方案,而session机制采用的是在服务器端保持状态的方案。同时我们也看到,由于采用服务器端保持状态的方案在客户端也需要保存一个标识,所以session机制可能需要借助于cookie机制来达到保存标识的目的,但实际上它还有其他选择。
cookie机制。正统的cookie分发是通过扩展HTTP协议来实现的,服务器通过在HTTP的响应头中加上一行特殊的指示以提示浏览器按照指示生成相应的cookie。然而纯粹的客户端脚本如JavaScript或者VBScript也可以生成cookie。而cookie的使用是由浏览器按照一定的原则在后台自动发送给服务器的。浏览器检查所有存储的cookie,如果某个cookie所声明的作用范围大于等于将要请求的资源所在的位置,则把该cookie附在请求资源的HTTP请求头上发送给服务器。 cookie的内容主要包括:名字,值,过期时间,路径和域。路径与域一起构成cookie的作用范围。若不设置过期时间,则表示这个cookie的生命期为浏览器会话期间,关闭浏览器窗口,cookie就消失。这种生命期为浏览器会话期的cookie被称为会话cookie。会话cookie一般不存储在硬盘上而是保存在内存里,当然这种行为并不是规范规定的。若设置了过期时间,浏览器就会把cookie保存到硬盘上,关闭后再次打开浏览器,这些cookie仍然有效直到超过设定的过期时间。存储在硬盘上的cookie可以在不同的浏览器进程间共享,比如两个IE窗口。而对于保存在内存里的cookie,不同的浏览器有不同的处理方式
session机制。session机制是一种服务器端的机制,服务器使用一种类似于散列表的结构(也可能就是使用散列表)来保存信息。当程序需要为某个客户端的请求创建一个session时,服务器首先检查这个客户端的请求里是否已包含了一个session标识(称为session id),如果已包含则说明以前已经为此客户端创建过session,服务器就按照session id把这个session检索出来使用(检索不到,会新建一个),如果客户端请求不包含session id,则为此客户端创建一个session并且生成一个与此session相关联的session id,session id的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个session id将被在本次响应中返回给客户端保存。保存这个session id的方式可以采用cookie,这样在交互过程中浏览器可以自动的按照规则把这个标识发送给服务器。一般这个cookie的名字都是类似于SEEESIONID。但cookie可以被人为的禁止,则必须有其他机制以便在cookie被禁止时仍然能够把session id传递回服务器。经常被使用的一种技术叫做URL重写,就是把session id直接附加在URL路径的后面。还有一种技术叫做表单隐藏字段。就是服务器会自动修改表单,添加一个隐藏字段,以便在表单提交时能够把session id传递回服务器。比如: <form name="testform" action="/xxx"> < input type="hidden" name="jsessionid" value="ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-145788764"> < input type="text"> < /form> 实际上这种技术可以简单的用对action应用URL重写来代替。
cookie 和session 的区别:
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗 考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能 考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、所以个人建议: 将登陆信息等重要信息存放为SESSION 其他信息如果需要保留,可以放在COOKIE中
29、servlet的一些相关问题
一,什么是Servlet?
Servlet是一个Java编写的程序,此程序是基于Http协议的,在服务器端运行的(如tomcat),是按照Servlet规范编写的一个Java类。
二,Servlet有什么作用?主要是处理客户端的请求并将其结果发送到客户端。
三,Servlet的生命周期?Servlet的生命周期是由Servlet的容器来控制的,它可以分为3个阶段;初始化,运行,销毁。
初始化阶段: 1,Servlet容器加载servlet类,把servlet类的.class文件中的数据读到内存中。
2,然后Servlet容器创建一个ServletConfig对象。ServletConfig对象包含了Servlet的初始化配置信息。
3,Servlet容器创建一个servlet对象。
4,Servlet容器调用servlet对象的init方法进行初始化。
运行阶段:
当servlet容器接收到一个请求时,servlet容器会针对这个请求创建servletRequest和servletResponse对象。然后调用service方法。并把这两个参数传递给service方法。Service方法通过servletRequest对象获得请求的信息。并处理该请求。再通过servletResponse对象生成这个请求的响应结果。然后销毁servletRequest和servletResponse对象。我们不管这个请求是post提交的还是get提交的,最终这个请求都会由service方法来处理。
销毁阶段:
当Web应用被终止时,servlet容器会先调用servlet对象的destrory方法,然后再销毁servlet对象,同时也会销毁与servlet对象相关联的servletConfig对象。我们可以在destroy方法的实现中,释放servlet所占用的资源,如关闭数据库连接,关闭文件输入输出流等。
在这里该注意的地方:在servlet生命周期中,servlet的初始化和和销毁阶段只会发生一次,而service方法执行的次数则取决于servlet被客户端访问的次数
四,Servlet怎么处理一个请求?
当用户发送一个请求到某个Servlet的时候,Servlet容器会创建一个ServletRequst和ServletResponse对象。在ServletRequst对象中封装了用户的请求信息,然后Servlet容器把ServletRequst和ServletResponse对象传给用户所请求的Servlet,Servlet把处理好的结果写在ServletResponse中,然后Servlet容器把响应结果传给用户。
五,Servlet与JSP有什么区别?
1,jsp经编译后就是servlet,也可以说jsp等于servlet。
2,jsp更擅长页面(表现)。servlet更擅长逻辑编辑。 (最核心的区别)。
3,在实际应用中采用Servlet来控制业务流程,而采用JSP来生成动态网页.
在struts框架中,JSP位于MVC设计模式的视图层,而Servlet位于控制层。
六,Servlet里的cookie技术?
cookies是一种WEB服务器通过浏览器在访问者的硬盘上存储信息的手段,是由Netscape公司开发出来的。
1,Cookie有效期限未到时,Cookie能使用户在不键入密码和用户名的情况下进入曾经浏览过的一些站点。
2,Cookie能使站点跟踪特定访问者的访问次数、最后访问时间和访问者进入站点的路径。
七,Servlet里的过滤器?
过滤器的主要作用
1,任何系统或网站都要判断用户是否登录。
2,网络聊天系统或论坛,功能是过滤非法文字
3,统一解决编码
(2)怎么创建一个过滤器:
1,生成一个普通的class类,实现Filter接口(javax.servlet.Filter;)。
2,重写接口里面的三个方法:init,doFilter,destroy。
3,然后在web.xml配置过滤器
八,Servlet里的监听器?
监听器的作用:自动执行一些操作。
三种servlet监听器:
对request的监听。对session的监听。对application的监听。
怎么创建一个session监听器:
1,生成一个普通的class类,如果是对session的监听,则实现HttpSessionListener。
2,然后重写里面的五个方法:Servlet是运行在Servlet容器中的,由Servlet容器来负责Servlet实例的查找、创建以及整个生命周期的管理,Servlet整个生命周期可以分为四个阶段:类装载及实例创建阶段、实例初始化阶段、服务阶段以及实例销毁阶段。
类装载及实例创建阶段
默认情况下,Servlet实例是在接受到第一个请求时进行创建并且以后的请求进行复用,如果有Servlet实例需要进行一些复杂的操作,需要在初始化时就完成,比如打开文件、初始化网络连接等,可以配置在服务器启动时就创建实例,具体配置方法为在声明servlet标签中添加<load-on-startup>1</load-on-startup>标签。
初始化 init(ServletConfig config)一旦Servlet实例被创建,将会调用Servlet的inint方法,同时传入ServletConfig实例,传入Servlet的相关配置信息,init方法在整个Servlet生命周期中只会调用一次。
服务 services()为了提高效率,Servlet规范要求一个Servlet实例必须能够同时服务于多个客户端请求,即service()方法运行在多线程的环境下,Servlet开发者必须保证该方法的线程安全性。
销毁 destory()当Servlet容器将决定结束某个Servlet时,将会调用destory()方法,在destory方法中进行资源释放,一旦destory方法被调用,Servlet容器将不会再发送任何请求给这个实例,若Servlet容器需再次使用该Servlet,需重新再实例化该Servlet实例。
二、Servlet执行流程
web服务器接受到一个http请求后,web服务器会将请求移交给servlet容器,servlet容器首先对所请求的URL进行解析并根据web.xml 配置文件找到相应的处理servlet,同时将request、response对象传递给它,servlet通过request对象可知道客户端的请求者、请求信息以及其他的信息等,servlet在处理完请求后会把所有需要返回的信息放入response对象中并返回到客户端,servlet一旦处理完请求,servlet容器就会刷新response对象,并把控制权重新返回给web服务器。
三、与其它技术的比较 v 其它服务相比servlet有以下的一些优点:
1、运行速度上比CGI快,因为使用了多线程
2、servlet使用了标准的api,可被许多web服务支持
3、与系统无关性,一次编译多次使用















 173
173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









