






分词是自然语言处理中最基本的一个任务,这篇小文章不介绍相关的理论,而是介绍一个电子病历分词的小实践。
开源的分词工具中,我用过的有jieba、hnlp和stanfordnlp,感觉jieba无论安装和使用都比较便捷,拓展性也比较好。是不是直接调用开源的分词工具,就可以得到比较好的分词效果呢?答案当然是否定的。尤其是在专业性较强的领域,比如医疗行业,往往需要通过加载相关领域的字典、自定义字典和正则表达式匹配等方式,才能得到较好的分词效果。
这次我就通过一个电子病历分词的小实践,分析在具体的分词任务中会踩哪些坑,然后如何运用jieba的动态加载字典功能和正则表达式,得到更好的分词结果。
代码和数据可以去我的Github主页下载:https://github.com/DengYangyong/medical_segment
一、原始文本数据
原始文本是100篇txt格式的电子病历文档,其中一篇文档的内容是这样的:

医疗文本中有一些文言文,比如神志清、神清、情况可等,对分词任务造成一定的困难。
二、使用jieba直接分词
首先使用jieba直接对100篇电子病历进行分词(jieba的基本使用可以看它的github页面:https://github.com/fxsjy/jieba )。在jieba.cut()中,选择精准模式(cut_all=False),同时不使用HMM模型进行分词,因为我在尝试使用HMM模式时,切出了一些没见过也不合理的新词。
1 #-*- coding=utf8 -*- 2 import jieba,os 3 #定义一个分词的函数 4 def word_seg(sentence): 5 #使用jieba进行分词,选择精准模式,关闭HMM模式,返回一个list:['患者','精神',...] 6 str_list = list(jieba.cut(sentence, cut_all=False, HMM=False)) 7 result = " ".join(str_list) 8 return result 9 10 if __name__=="__main__": 11 # 100篇电子病历文档所在的目录 12 c_root = os.getcwd()+os.sep+"source_data"+os.sep 13 fout = open("cut_direct.txt","w",encoding="utf8") 14 15 for file in os.listdir(path=c_root): 16 if "txtoriginal.txt" in file: 17 fp = open(c_root+file,"r",encoding="utf8") 18 for line in fp.readlines(): 19 if line.strip() : 20 result = word_seg(line) 21 fout.write(result+'\n') 22 fp.close() 23 24 fout.close()
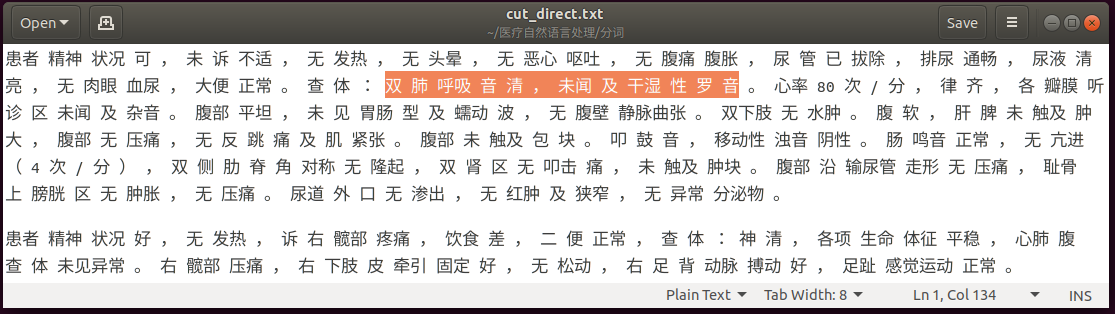
下面是其中两篇电子病历的分词结果,可以看到,有很多医疗行业的词语没有切分正确,比如“双肺呼吸音清”、“湿性罗音”、“尿管”、“胃肠型及蠕动波” 、“反跳痛”等,所以下一步加载医疗行业的字典,希望能改善这个情况。
三、加载行业专属字典
最近在看一个电子病历命名实体识别项目的代码,这个项目使用加载字典的方式进行命名实体识别,里面有一个字典,恰好可以用在这里做分词。
这个字典是一个csv文件,有17713个医疗行业的命名实体,主要包括疾病名称、诊断方法、症状、治疗措施这几类,字典里每一行有两个元素,一个是命名实体(如肾性高血压);第二个是相应的符号标注(如DIS,即disease),类似于词性标注。
1 import csv 2 dic = csv.reader(open("DICT_NOW.csv","r",encoding='utf8')) 3 dic_list = list(dic) 4 5 # 打印出字典的前五行内容 6 print("字典的内容是这样的:\n\n",a[:5]) 7 print("\n字典的长度为:",len(dic_list))
字典的内容是这样的: [['肾抗针', 'DRU'], ['肾囊肿', 'DIS'], ['肾区', 'REG'], ['肾上腺皮质功能减退症', 'DIS'], ['肾性高血压', 'DIS']] 字典的长度为: 17713
然后把这个字典加载到jieba里:
1 #-*- coding=utf8 -*- 2 import jieba,os,csv 3 4 def add_dict(): 5 dic = csv.reader(open("DICT_NOW.csv","r",encoding='utf8')) 6 # row: ['肾抗针', 'DRU'] 7 for row in dic: 8 if len(row) ==2: 9 #把字典加进去 10 jieba.add_word(row[0].strip(),tag=row[1].strip()) 11 #需要调整词频,确保它的词频足够高,能够被分出来。 12 #比如双肾区,如果在jiaba原有的字典中,双肾的频率是400,区的频率是500,而双肾区的频率是100,那么即使加入字典,也会被分成“双肾/区” 13 jieba.suggest_freq(row[0].strip(),tune=True) 14 15 def word_seg(sentence): 16 17 str_list = list(jieba.cut(sentence, cut_all=False, HMM=False)) 18 result = " ".join(str_list) 19 return result 20 21 if __name__=="__main__": 22 23 add_dict() 24 c_root = os.getcwd()+os.sep+"source_data"+os.sep 25 fout = open("cut_dict.txt","w",encoding="utf8") 26 27 for file in os.listdir(path=c_root): 28 if "txtoriginal.txt" in file: 29 fp = open(c_root+file,"r",encoding="utf8") 30 for line in fp.readlines(): 32 if line.strip(): 33 result = word_seg(line) 34 fout.write(result+'\n') 35 fp.close() 36 37 fout.close()
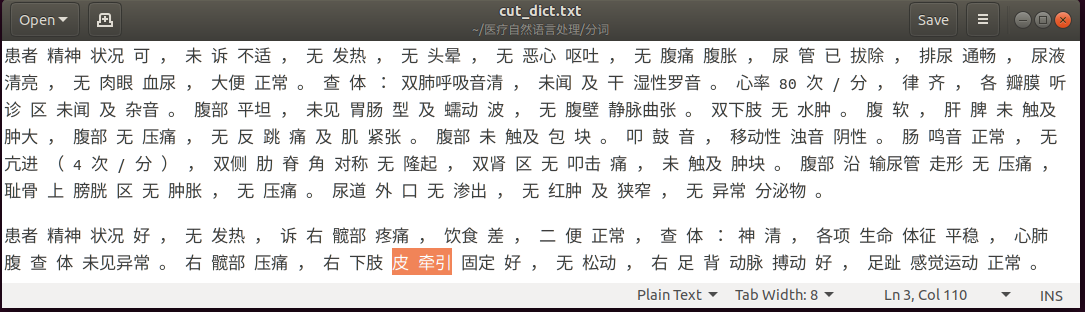
分词完毕后,再看看前两篇病历的分词结果。可以看到,“双肺呼吸音清”,“湿性罗音”分词正确,可是还有一大堆词没有切分正确:尿管、胃肠型及蠕动波、反跳痛、肌紧张、皮牵引等等。可见一方面这个字典太小,只有17713个医疗词语,另一方面这是命名实体的字典,倾向于识别疾病名词、症状、检查手段和治疗措施这类命名实体,一般的身体部位、医疗用具并没有包含在内。
当然,尽管从这两篇病历来看,加载命名实体识别字典的效果不是太明显,但是查看100篇病历的分词结果,效果还是有较大的提升。既然命名实体识别的字典太小,那没办法,对于一些在病历中经常出现的词,可以通过自定义字典的方式进行正确分词。
四、自定义字典、正则表达式匹配和停用词
自定义字典就是把肠鸣音、皮牵引、胃肠型及蠕动波等没有正确切分的词语汇总,做成一个文件,然后加载到jieba当中去。代码实现起来比较简单,打开一个txt文件,每一行放一个词,然后保存文件即可,麻烦在于要手动挑选出这些专业词汇。100篇病历太多了,我简单做个尝试,从前10篇病历中大致找了些没有被正确切分的词做成字典,有下面这些:
听诊区 胃肠型及蠕动波 膀胱区 干湿性罗音 移动性浊音 皮牵引 反跳痛 肌紧张 肠鸣音 肋脊角 双肾区 查体 二便 痂皮 律齐 听诊区 发绀 湿罗音 外口
膝腱反射 巴彬斯基氏征 克尼格氏征 气过水声
我在查看100篇病历的分词结果时,发现其实除了这些比较规范的词外,还有一些与数字相关的词没有被正确切分(当然这也带有一定主观性,我有些强迫症),比如小数被 “.” 号分开,“%” 号与数字分开,* ^ 与数字分开。所以我想构造正则表达式,把正确的词匹配出来,然后作为字典加载到jieba中去。下面是一些我认为没有切分正确的词:
心率 62 次 / 分 ;右 下肢 直 腿 抬高 试验 阳性 50 度; 右手 拇指 可见 一 约 1 * 1cm 皮肤 挫伤 ;血常规 : 红细胞 6 . 05 * 10 ^ 12 / L , 血红蛋白 180 . 00g / L;
尿蛋白 + 2 红细胞 + 2;查 体 : T : 36 . 8 ℃ , 精神 可;中性 细胞 比率 77 . 6 % , 淋巴细胞 比率 19 . 6 % , 中 值 细胞 比率 2 . 8 % 。
正则表达式的代码如下,使用python的re模块。
先看p1,r'\d+[次度]'用来匹配“80次”、“50度” 这两种表示心率、温度的常见的词,\d+表示匹配一个或多个数字,[次度]表示数字后的字是次或者度。
然后看p2,用来匹配6.05,10^12,77.6%这类的数据,[a-zA-Z0-9+]+ 表示字母数字或者+号,然后匹配一次或多次。[\.^]* 中,表示匹配.或^号0次或1次,\是转义符号,因为后面的.本身就是正则表达式中的特殊字符,而在这里是表示小数点。[A-Za-z0-9%(℃)]+含义比较明确,然后(?![次度])是负前向查找,当后面的字不是次或度时就匹配,避免去匹配p1应该匹配的内容。当然其实这个表达式有很多问题,但是暂时想不出其他的了。
1 p1 = re.compile(r'\d+[次度]').findall(line) 2 p2 = re.compile(r'([a-zA-Z0-9+]+[\.^]*[A-Za-z0-9%(℃)]+(?![次度]))').findall(line)
所有匹配到的词如下所示,正则表达式刚入门还是小弱,费了老大的劲,还是匹配到了很多不想要的东西。先这样,看到的人欢迎拍砖。
" ".join([word.strip()for word in open("regex_dict.txt",'r',encoding='utf8').readlines()])
'80次 4次 62次 1cm 78次 BP130 80mmhg 80次 4次 4700ml CT 80次 4次 6.05 10^12 180.00g 0.550L 6.4fL +2 +2 25 38 HP 62.0U 100.00U 50度 76次 36.8C 84次 20次 74次 4次 3000ml 36.8C Fr20 3次
36.8℃ 84次 4次 140 90mmHg 4次 3cm 4X3cm CT 64次 4次 CT 90次 3mm 76次 4次 2.0cm 3.0 2.5cm 1.5 1.0cm 4次 36.4℃ 64次 3次 98次 300ml 12cm 74次 36.3C 80次 18次 80次 4次 37.0C 4次 12cm
76次 4次 Murphy CT 7.40 10^9 77.6% 19.6% 2.8% 3.49 10^12 99.00g 0.302L 78次 18次 36.5℃ BP130 80 mmHg 36.4℃ 80次 4次 4次 37℃ 82次 22次 82次 4次 3250ml 37℃ BP 149 97mmHg 100% 6cm
10cm 15cm 5cm 3cm 3cm 1.5 8cm 92次 Bp129 75mmHg 4次 72 4次 80次 4次 76次 4次 12 42 12 42 12cm 79次 37.0C 80次 4次 70次 4次 3次 72次 5度 100度 5度 105度 10 10 75次 18次 72次 T36.4℃
P7 R1 BP130 85mmhg'
第三步是去掉以标点符号为主的停用词(停用词是诸如“的、地、得”这些没有实际含义的词以及标的符号特殊符号等)。我尝试使用从网上下载的中文停用词表,挺齐全,有2000多个停用词,可是使用后发现结果不好,因为它会把 类似“无”,“可”这种词去掉,于是“无头晕”只剩下了“头晕”,“精神可”只剩下了“精神”,要么意思反了,要么不知所云。
所以我自己弄了个简单的停用词表,只去掉 “ ,。!?:、)( ” 这些符号。
完整的代码如下:
1 #-*- coding=utf8 -*- 2 import jieba,os,csv,re 3 import jieba.posseg as pseg 4 5 def add_dict(): 6 # 导入自定义字典,这是在检查分词结果后自己创建的字典 7 jieba.load_userdict("userdict.txt") 8 dict1 = open("userdict.txt","r",encoding='utf8') 9 #需要调整自定义词的词频,确保它的词频足够高,能够被分出来。 10 #比如双肾区,如果在jiaba原有的字典中,双肾的频率是400,区的频率是500,而双肾区的频率是100,那么即使加入字典,也会被分成“双肾/区” 11 [jieba.suggest_freq(line.strip(), tune=True) for line in dict1] 12 13 #加载命名实体识别字典 14 dic2 = csv.reader(open("DICT_NOW.csv","r",encoding='utf8')) 15 for row in dic2: 16 if len(row) ==2: 17 jieba.add_word(row[0].strip(),tag=row[1].strip()) 18 jieba.suggest_freq(row[0].strip(),tune=True) 19 20 # 用正则表达式匹配到的词,作为字典 21 fout_regex = open('regex_dict.txt','w',encoding='utf8') 22 for file in os.listdir(path=c_root): 23 if "txtoriginal.txt" in file: 24 fp = open(c_root+file,"r",encoding="utf8") 25 for line in fp.readlines(): 26 if line.strip() : 27 #正则表达式匹配 28 p1 = re.compile(r'\d+[次度]').findall(line) 29 p2 = re.compile(r'([a-zA-Z0-9+]+[\.^]*[A-Za-z0-9%(℃)]+(?![次度]))').findall(line) 30 p_merge = p1+p2 31 for word in p_merge: 32 jieba.add_word(word.strip()) 33 jieba.suggest_freq(word.strip(),tune=True) 34 fout_regex.write(word+'\n')
35 fp.close() 36 fout_regex.close() 36 37 # 用停用词表过滤掉停用词 38 def stop_words(): 39 # "ChineseStopWords.txt"是非常全的停用词表,然后效果不好。 40 #stopwords = [word.strip() for word in open("ChineseStopWords.txt","r",encoding='utf-8').readlines()] 41 stopwords = [word.strip() for word in open("stop_words.txt","r",encoding='utf-8').readlines()] 42 return stopwords 43 44 # 进行分词 45 def word_seg(sentence): 46 47 str_list = list(jieba.cut(sentence, cut_all=False, HMM=False)) 48 str_list = [word.strip() for word in str_list if word not in stopwords] 49 result = " ".join(str_list) 50 return result 51 52 if __name__=="__main__": 53 54 add_dict() 55 stopwords = stop_words() 56 c_root = os.getcwd()+os.sep+"source_data"+os.sep 57 fout = open("cut_stopwords.txt","w",encoding="utf8") 58 59 for file in os.listdir(path=c_root): 60 if "txtoriginal.txt" in file: 61 fp = open(c_root+file,"r",encoding="utf8") 62 for line in fp.readlines(): 63 if line.strip() : 64 result = word_seg(line) 65 fout.write(result+'\n\n') 66 fp.close() 67 68 fout.close()
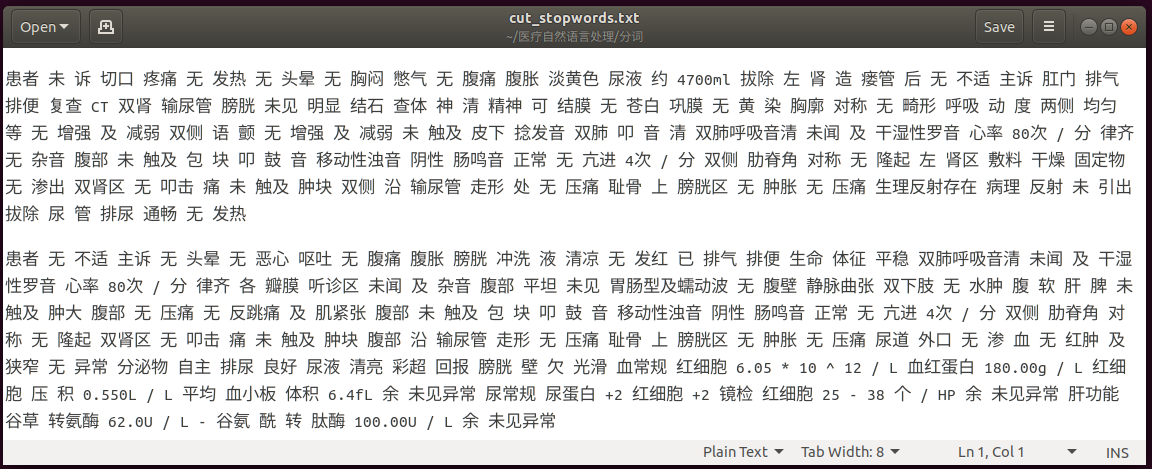
部分分词结果如下,可以看到,像80次、6.05,+2这种格式的数据分词正确,但是我发现尽管能已经匹配到了1*1,10^12,36.4℃这些词,但是加载进去后用jieba分词还是不能正确划分,看来在jieba中,* ^ / 这些符号是必须要被切开的。
五、小结
这一个简单的电子病历分词实践到此告一段落,说说两点体会吧。
一是分词有基于字典的方法,基于规则的方法和基于机器学习的方法,尽管机器学习的方法听起来高大上,但可能会切出一些没见过的词,而基于字典的方法看上去比较土,其实更好用,准确性更高。
二是医疗行业的自然语言处理非常不好做,这些电子病历、医疗文献是英文、现代文和文言文的混合体,医生写病历、处方有时喜欢文言体(简洁省事),各种疾病、治疗手段的专业术语又非常多,每种疾病又有很多主流和非主流的名称,给分词、实体识别这些任务造成了很大麻烦。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









