






经再次测试发现第一次调用时候语音播放多遍,请待我继续完善。
环境:
windows10;
IIS 10;
.Net4.5.2;
例子代码:传送门
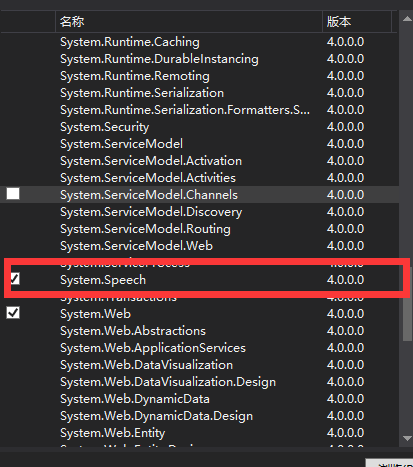
首先在程序中添加System.Speech的引用
在控制器中加入以下代码:
1 public async Task GetSpeek(string context) 2 { 3 try 4 { 5 using (SpeechSynthesizer hello = new SpeechSynthesizer()) 6 { 7 var speek = hello.SpeakAsync(context); 8 while (!speek.IsCompleted) 9 { 10 System.Threading.Thread.Sleep(100); 11 } 12 using (System.IO.MemoryStream ms = new System.IO.MemoryStream()) 13 { 14 hello.SetOutputToWaveStream(ms); 15 16 HttpContext.Response.ClearContent(); 17 HttpContext.Response.ContentType = "audio/mp3"; 18 HttpContext.Response.BinaryWrite(ms.ToArray()); 19 //Dispose 20 await ms.FlushAsync(); 21 // ms.Dispose(); 22 ms.Close(); 23 hello.Dispose(); 25 HttpContext.Response.Close(); 26 } 27 } 28 } 29 catch (Exception ex) 30 { 31 32 } 33 }
注意:这里只能使用异步方法
为什么?异常会告诉你。
最后一句
HttpContext.Response.Close();
这句,为什么,等会我再解释,先上前端代码:(弃用)
function speckText() { try { var n = new Audio(); var url = "http://localhost:8211/Home/GetSpeek?context=" + Math.random(); n.src = url; n.loop = false; n.play(); } catch (e) { } }
这里使用html5的audio控件,我这边加了一个
n.loop=false
但是,在测试时候,发现若后台不断开链接,该audio会重复读3遍。而在javascript加这句也没用。所以后台必须给前端一个停止的信息,用来停止这次链接。
这里就有一个不好的地方。
上图!!!
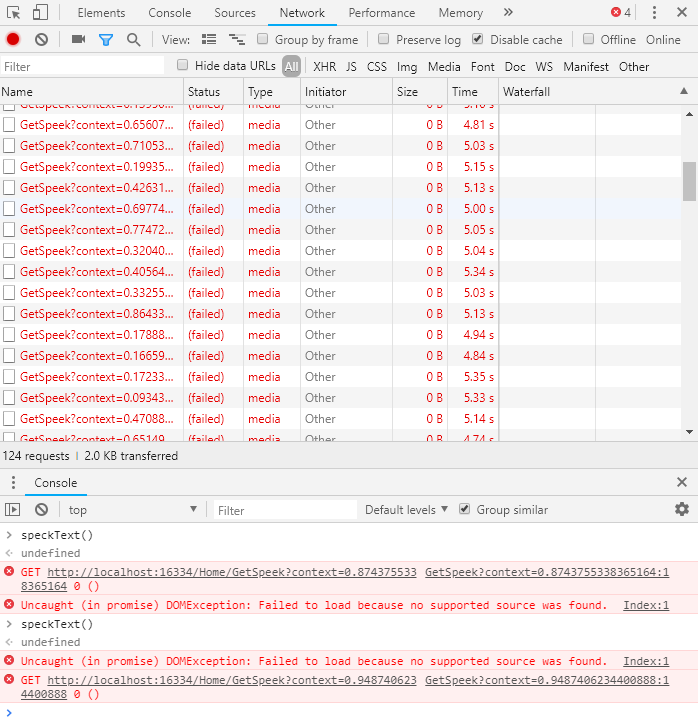
可以看出由于是后台发送停止的,所以前端这边都是显示链接失败,但是!语音的确是有的。
还有一个点就是,发布到IIS上时

进程模型=>标识=>修改为LocalSystem。
没了~
若大家有什么更好的可以推荐给我。有什么优化建议也可以交流交流。
最新处理方案
1 var messageArray = new Array();//用于存储数据信息 2 3 startSpeech(); 4 function startSpeech() { 5 //定时器读取数据内容,并移除已读数据,由于不熟悉js所以直接用获取 6 //第一个数据信息,然后再移除第一个数据信息,作为一个队列来处理 7 window.setInterval(function () { 8 if (messageArray.length != 0) { 9 var item = messageArray[0]; 10 getAudio(item); 11 console.log(item); 12 messageArray.splice(0, 1); 13 } 14 }, 5000); 15 } 16 17 function getAudio(item) { 18 //使用异步链接地址 19 $.ajax({ 20 url: "http://localhost:64441/StatsShow/GetSpeek?context=" + item, 21 type: "get", 22 })
}
神异步...
灰常感谢














 2729
2729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









