






本次作业的要求为:
针对第三单元的三次作业和课程内容,撰写技术博客
(1)梳理JML语言的理论基础、应用工具链情况
(2)【改为选做,能较为完善地完成的将酌情加分】部署SMT Solver,至少选择3个主要方法来尝试进行验证,报告结果
• 有可能要补充JML规格
(3)部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例(简单方法即可,如果依然存在困难的话尽力而为即可,具体见更新通告帖), 并结合规格对生成的测试用例和数据进行简要分析
(4)按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
(5)按照作业分析代码实现的bug和修复情况
(6)阐述对规格撰写和理解上的心得体会
第三单元以JML规格为中心的三次作业,对我而言还是有很大难度的。个人感觉,这三次作业与其说是JML规格,不如说是“数据结构之图论的诱惑”,总是因为莫名其妙的TLE、CPU超时问题而在强测中爆炸。现在,在第三单元结束后,我将自己在这一单元中所做的工作总结如下:
一、 梳理JML语言的理论基础、应用工具链情况
1、理论基础
JML语言,是用于对Java程序进行规格化设计的一种表示语言,是一种行为接口规格语言(Behavior Interface Specification Language,BISL),基于Larch方法构建。BISL提供了对方法和类型的规格定义手段。所谓接口即一个方法或类型外部可见的内容。JML主要由Leavens教授在Larch上的工作,并融入了BetrandMeyer, John Guttag等人关于Design by Contract的研究成果。近年来,JML持续受到关注,为严格的程序设计提供了一套行之有效的方法。通过JML及其支持工具,不仅可以基于规格自动构造测试用例,并整合了SMT Solver等工具以静态方式来检查代码实现对规格的满足情况。
JML在实际设计中主要有两种用途:
(1)在实现前对设计的规格进行精确传达
(2)对已实现的代码进行总结梳理,主要体现在提高代码的可维护性。
2、基础内容
(1)注释结构
行注释://@annotation
块注释:/*@ annotation @*/
两种注释方法均适用@开头,并将JML注释放在被注释成分的近邻上部。
(2)常见表达式
①原子表达式
\result表达式:表示一个非 void 类型的方法执行所获得的结果,即方法执行后的返回值。这里此表达式的类型根据被注释的函数的返回值而定。
\old(expr)表达式:用来表示一个表达式expr在相应方法执行前的取值。当expr有被修改时,使用此表达式,表示expr被修改之前的值。这里有一点需要注意,对于一个引用对象,只能判断引用本身是否发生变化,即只能描述引用对象的地址是否发生变化,而不能描述对象的成员变量等是否发生变化。
\not_assigned(x,y,…)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。
\not_modified(x,y,…)表达式:限制括号中的变量在方法执行期间的取值未发生变化。
\nonnullelements(container)表达式:表示container对象中存储的对象不会有null。
②量化表达式
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。使用的结构如下:
(\forall 类型 变量; 变量满足的限制; 在限制条件下的结果)
以下几种表达式均有类似的使用结构。
\exists表达式:与forall表达式使用结构类似,为存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
\sum表达式:返回给定范围内的表达式的和。
\product表达式:返回给定范围内的表达式的连乘结果。
\max表达式:返回给定范围内的表达式的最大值。
\min表达式:返回给定范围内的表达式的最小值。
\num_of表达式:返回指定变量中满足相应条件的取值个数。
③ 操作符
子类型关系操作符E1<:E2,如果类型E1是类型E2的子类型(sub type),则该表达式的结果为真,否则为假。如果E1和E2是相同的类型,该表达式的结果也为真。
等价关系操作符b_expr1<==>b_expr2或者 b_expr1<=!=>b_expr2,其中b_expr1和b_expr2都是布尔表达式,这两个表达式的意思是 b_expr1==b_expr2 或者b_expr1!=b_expr2 。
推理操作符b_expr1==>b_expr2 或者 b_expr2<==b_expr1,即数理逻辑中的蕴含运算。
变量引用操作符
\nothing 表示空集;
\everything 表示全集。
(3)方法规格
①前置条件(pre-condition):对调用者的限制,即要求调用者确保条件为真。
②后置条件(post-condition):对方法实现者的要求,即方法实现者确保方法执行返回结果一定满足谓词的要求,即确保后置条件为真。
③副作用范围限定(side-effects):
assignable 表示可赋值
modifiable 表示可修改
多数情况下二者可以交换使用
④ signals子句
signals子句的结构为signals (Exception e) b_expr,当b_expr为true时,方法会抛出括号中给出的相应异常e。signals_only子句是对signals子句的简化版本,不强调对象状态条件,强调满足前置条件时抛出相应的异常。
(4)类型规格
①不变式invariant
不变式是要求在所有可见状态下都必须满足的特性。可见状态主要包含以下几种:
对象的有状态构造方法(用来初始化对象成员变量初值)的执行结束时刻
在调用一个对象回收方法(finalize方法)来释放相关资源开始的时刻
在调用对象o的非静态、有状态方法(non-helper)的开始和结束时刻
在调用对象o对应的类或父类的静态、有状态方法的开始和结束时刻
在未处于对象o的构造方法、回收方法、非静态方法被调用过程中的任意时刻
在未处于对象o对应类或者父类的静态方法被调用过程中的任意时刻
②状态变化约束constraint
可以认为状态变化约束比上面的不变式放宽了一定的限制,它并不要求一定不发生变化,而是在变化过程中形成要满足一定的约束条件。
3、应用工具链
(1)openJML
首先,通过开源的JML编译器(在此处我们选择openJML),编译含有JML标记的代码。可以根据JML对实现进行静态的检查,其中用于进行JML分析的部分在solvers中,包括常见的如cvc4以及z3。
在openJML中,“-check”选项可以对生成的类文件进行JML规范检查。openJML中还包含z3等SMT Solver,可以对代码等价性进行验证。通过openJML“-esc”选项对代码的静态验证是不依赖JML的,SMT Solver会自动整理JML。
(2)JMLUnitNG
JML UnitNG可以生成一个Java类文件测试的框架,基于JML并结合Openjml“-rac”选项运行时检查选项,可以根据JML自动生成对应的测试样例,用于进行单元化、自动化测试(实践证明,这种测试主要是边界测试)。
JMLdoc工具与Javadoc工具类似,可在生成的HTML格式文档中包含JML规范。
二、 部署SMT Solver,并选择至少3个主要方法进行验证,报告结果
1、SMT Solver
SMT(Staisfiability modulo theories) Solver,是一个定理证明器其工作机理是:openJML将JML规范转换为SMT-LIB格式,并将Java+JML程序所隐含的证明问题传递给后端SMT求解器。
2、SMT Solver工作原理
OpenJML将JML规范转换为SMT-LIB格式,并将Java+JML程序所隐含的证明问题传递给后端SMT求解器。
OpenJML支持主要的SMT解决方案,如Z3、CVC4和YIES。
证明的成功将取决于SMT解算器的能力(例如,它支持哪些逻辑)、代码+规范的特定逻辑编码以及代码和规范编写的复杂性和样式。
3、进行检查
(1)进行检查的代码

(2)格式检查
指令“openjml -check .\Exp\Main.java”
无误
删除第二行注释末尾的一个分号,再次进行格式检查
报错

(3)静态检查
指令“openjml -esc -prove .\Exp\Main.java”
报错,部分报错信息如下
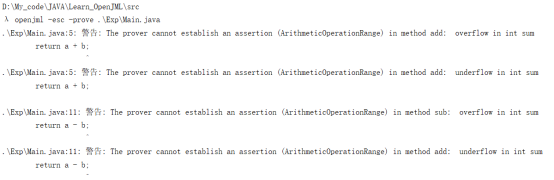
三、 部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例,结合规格对生成的测试用例和数据进行简要分析
(1) 测试代码
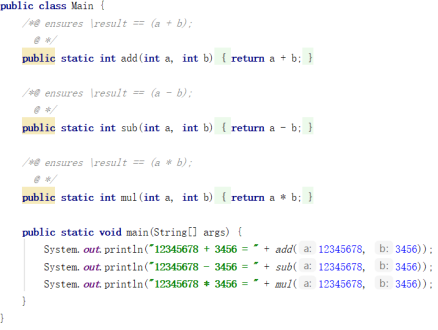
(2) 生成测试文件
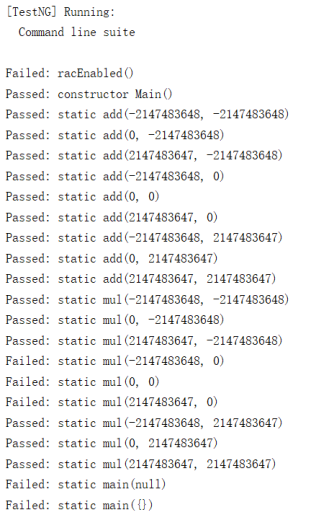
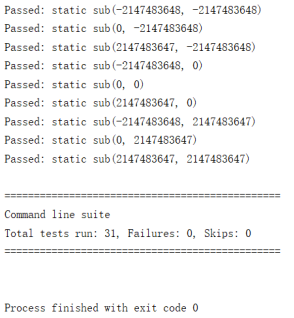
使用指令“java -jar ..\..\openjml\jmlunitng.jar .\Exp\Main.java”自动生成众多测试文件。对这些文件进行编译,进行运行测试。
(3) 测试结果
四、 按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
1、第9次作业
(1)结构分析
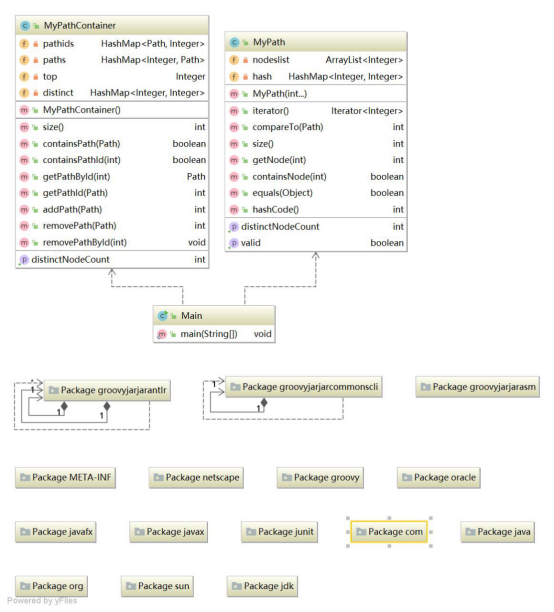
关于第9次作业,在主类Main中,通过将MyPath和MyPathContainer传给AppRunner,实现对这两个功能模块的测试。MyPathContainer类存在对Path类型量的各种操作,因此一定程度上依赖于Path类。
在MyPath类中,用Arraylist和hashmap同时存储一条路径中的所有点。当需要判断是否包含某个点时,用hashmap;当所进行的操作需要对这个路径中所有点按输入时的顺序进行遍历,或者取出按顺序的第i个点,或者对不同的路径进行相同比较、字典序比较时,使用arraylist。同时,因为在MyPathContainer中存在以MyPath类型的变量作hashmap的key值得情况,所以需要重写MyPath类中的equals和hashcode。
在MyPathContainer类中,用2个HashMap分别存储path到pathid(paths),和pathid到path(pathids)的对应关系。还需要一个hashmap(名为distinct)存储各个path中不同的点。名为paths的hashmap,key值类型为path,表示路径,value值类型为Integer,表示对应的路径编号;名为pathids的hashmap,key值类型为Integer路径编号,value值类型为path,表示对应的路径;名为distinct的hashmap,key值类型为Integer,表示节点序号,value值类型为Integer,表示对应节点的出现次数。
(2)复杂度与依赖度分析
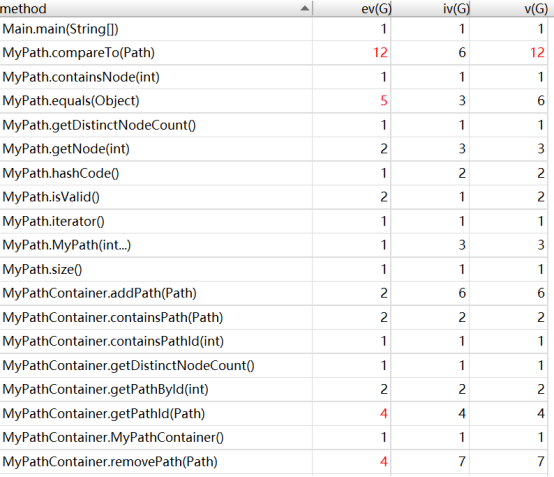


这次作业,复杂度较高的主要是MyPath类的compareTo字典序比较方法。但要进行字典序比较,遍历path中所有点在所难免,且这也是强测允许的方法,故我认为它是合理的。
2、第10次作业
(1)结构分析

我的第10次的oo作业,是在第9次作业的基础上,在第9次作业的基础上增加了MyGraph类的功能而完成的。在这些增加的功能中,比较特殊的是:isConnect()判断fromNodeId的对应点和toNodeId的对应点是否连接,以及getShortestPathLength在相连的情况下求从fromNodeId的对应点到toNodeId的对应点的最短距离。
这对于这两个功能,我的思路主要是:
在每次addpath时,除了要更新表示path 和pathid对应关系的两个hashmap,存储不同节点的distinct结构;还要更新由所有path构成的无向图,清空以前的“是否连通”“最短距离”储存结果。
在每次removepath时,同样,在remove pathids paths distinct这3个hashmap的同时,还要删除无向图中的这个path,同时清空以前的“是否连通”“最短距离”储存结果。
在“判断是否相连”“求最短距离时”,首先查找以前的“是否连通”“最短距离”储存结果,如果有,直接返回,如果没有,针对无向图graph使用广度遍历算法,并且保存所有中间结果和最终结果。最后,总能判断出“是否连通”或“最短距离”。
在isConnected和getShortestLength函数中,我的思路是这样的:
现判断fromNodeId的对应点和toNodeId的对应点是否存在于现有无向图中,如果否,那么抛出异常;如果都存在于现有无向图,那么判断这两点是否是同一点,是否在lengthgraph中已经保存了它们之间的连接关系或最短距离。在这里,如果对应的fromNodeId和toNodeId存在于lengthgraph中,如果对应数字-1,则两点不相连,否则对应数字就是两点之间的距离。
对应关系无法在lengthgraph中取得,那么,需要进行一次fromNodeId的对应点到其他能直接或间接相连的所有点的广度优先遍历。我的广度优先遍历,是在《数据结构》课程的广度优先遍历,和CDSN上类似代码分享的基础上完成的,在不停地调用自身中,需要这些参数:
其中,queue1的key与list1的内容相同,表示当前“层”中需要被查找的点,queue2中的点是已经被查找过的点。每次调用这个广度优先遍历函数之前,都需要重新构建符合当前情况的queue1、list1和queue2。
同时,我对我在MyGraph类中2个双重嵌套Hashmap进行拆分的结果。原本,我在MyGraph类中使用了这样的2个Hashmap:

来表示若干条路径组成的无向图,以及储存每次进行广度遍历的中间结果和最终结果。后来在写代码的过程中,我发现,如果这样设计,每次在graph和lengthgraph中进行查找时,都要先通过“.get()”取出整个HashMap<Integer,Integer>,再进行查找;每次对graph和lengthgraph中的内容进行增减时都要先通过“.get()”取出整个HashMap<Integer,Integer>,进行增减,再放回原位。我认为这种方式太过笨拙,占用空间也相对大了很多,因此将嵌套在内层的HashMap<Integer,Integer>取出,封装成Line类,并构造相应的一些函数完成“查找”、“更改”等功能。进行封装后,我的MyGraph类更改为:

(2)复杂度与依赖度分析
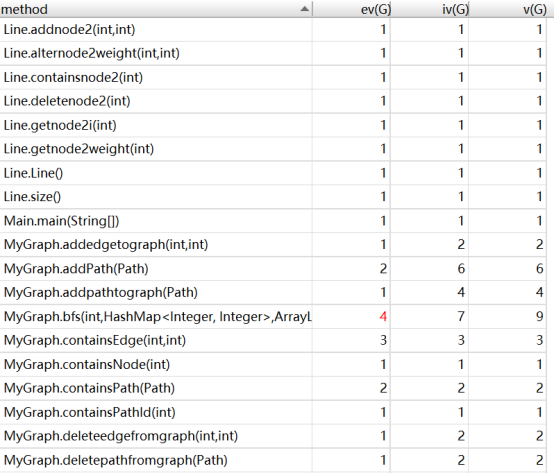


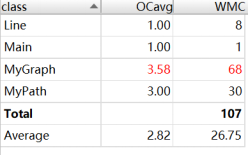
在这次作业中,复杂度较高的部分,主要在于继承自第9次作业的compareTo函数,和本次新增功能的isConnect函数。compareTo函数的遍历path问题无法避免,isConnect函数同样需要进行广度优先遍历。
3、第11次分析
(1)结构分析

我的第11次的oo作业,是在第10次作业的基础上,在第10次作业的基础上增加了MyRailwaySystem类的功能而完成的。在这些增加的功能中,比较特殊的是:getConnectBlockCount()判断连通块的数目,isConnect()判断fromNodeId的对应点和toNodeId的对应点是否连接,getShortestPathLength在相连的情况下求从fromNodeId的对应点到toNodeId的对应点的最短距离,getLeastTicketPrice在相连的情况下求从fromNodeId的对应点到toNodeId的对应点的最低票价,getLeastTransPrice在相连的情况下求从fromNodeId的对应点到toNodeId的对应点的最少换乘,getLeastUnpleasentValue在相连的情况下求从fromNodeId的对应点到toNodeId的对应点的最小不满意度。
相对于第10次作业,我这次作业主要进行了这些设计:
(1)
我用Map类来存储彼此不联通的子图。每次新加入一个path,我都首先判断,这个path是需要加入一个已经存在的子图(也就是说,这个path和这个已存在的子图是相连的,有相同的点),还是需要以这个path为基础new一个新的子图。
如果是加入已有子图中(记为子图A),会不会有不同于子图A的子图B,因这个path而联通在了一起。如果有这样的子图B,那么,需要销毁子图B,将子图B中所有path和对应的pathid,一组一组地加入子图A中。
每次remove一个path,也都需要销毁这个path所在的子图(记作子图A),再将子图A中不同于path的其他路径,进行“加入操作”;又因为这些“不同于path的其他路径”已经有对应的pathid,因此不能直接采用addpath操作,而应该使用相似而不同的insertpath函数。当需要用getConnectBlockCount()判断连通块的数目时,直接返回子图的数量即可。
(2)
在计算最低票价、最少换乘、最小不满意度时,都涉及到不同path同一站点的换乘问题。我设计了区别于普通node的NodePathId,用于配合拆点法使用(虽然事实证明拆点法易燃易爆炸)。只有两个NodePathId的点序号node和所在路径序号pathId都相同时,才判断这两点是同一个点。因为存在用NodePathId作hashmap的key的情况,需要重写其equals函数和hashcode函数。
(3)
在计算最短距离、最低票价、最少换乘、最小不满意度时,我使用的都是迪杰斯特拉算法。但由于在计算最低票价、最少换乘、最小不满意度时,需要考虑不同线路的换乘,需要采用拆点法,因此,我完成了两个迪杰斯特拉算法函数,分别适用于“普通node + 最短距离”与“NodePathId + 最低票价、最少换乘、最小不满意度”。
在计算最低票价时,我首先看以往的迪杰斯特拉有没有顺带着得出并保存我想要的结果(正着找一次,反着找一次);如果没有找到,那么,需要进行一次从fromNodeId的对应点到剩下同一连通图中所有点的迪杰斯特拉查找,在此之前,因为我的计算最短距离、最低票价、最少换乘、最小不满意度使用同一个迪杰斯特拉算法,所以我们需要将迪杰斯特拉需要用到的一些参数(在计算最短距离、最低票价、最少换乘、最小不满意度时有所不同的部分)提前算好,传入迪杰斯特拉函数中。
计算最少换乘、最低不满意度的算法与此大同小异(其实我是复制自己的计算最低票价的函数写的最少换乘、最低不满意度来着)。
在向Map中加入一个path时,我需要做的事情包括:
更新用于表示path和pathid对应关系的hashmap,在用于计算最短距离、最低票价、最少换乘、最小不满意度的无向图中讨论是否插入新的“行”(抽象地理解为一个二维矩阵,或者链表);为方便拆点法的使用,构建不同path上相同node的关系(注意,在不同无向图中赋值不同);将新加入的path,一条边一条边地加入;最后,更新“某一点都在哪些path中出现”的hashmap,清空之前所有保存的迪杰斯特拉算法的结果。
(2)复杂度与依赖度分析
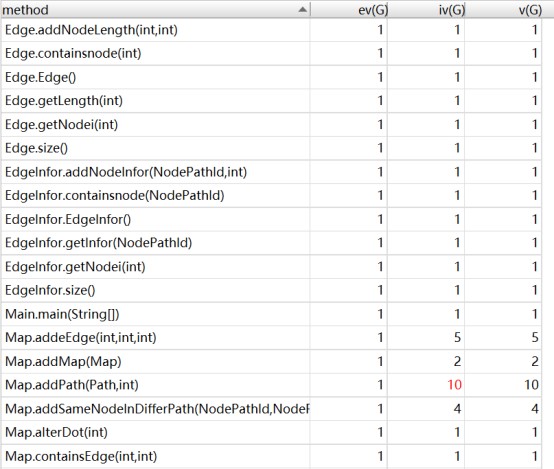
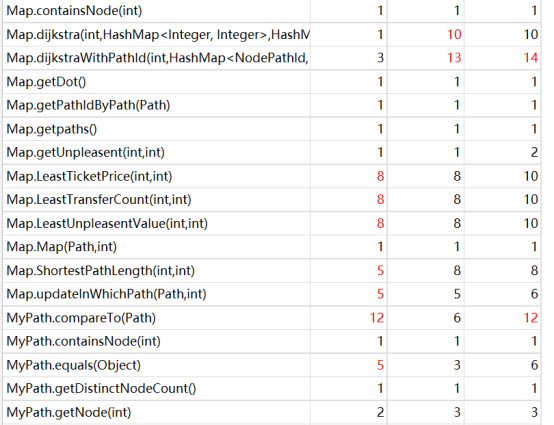
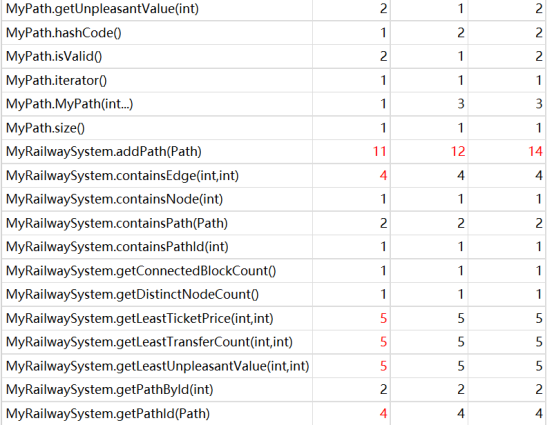
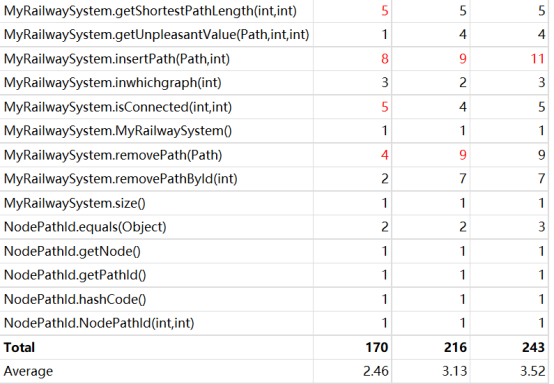
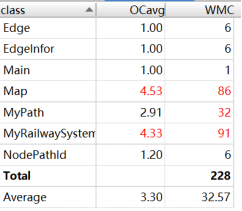
在这次作业中,我使用了拆点法+迪杰斯特拉,但由于拆出来的点实在过多,因此,在强测中tle了一些点。改用普通点+弗洛伊德的方法,可以避免tle问题。
五、 按照作业分析代码实现的bug和修复情况
第9次作业:
在MyPath类中,只是用hashmap,无法很好地按存储的顺序取出路径中的所有点,同时在取得过程中可能发现各种错误,所以出现了各种tle问题。在改用arraylist和hashmap的结合体后,可以解决所有出现的tle问题。
第10次作业:
无bug.
第11次作业:
在计算最少换乘等问题时,使用了拆点法+迪杰斯特拉,但由于拆出来的点实在过多,因此,在强测中出现了一些tle的点。改用“普通点(二维数组储存)+弗洛伊德”的方法,可以解决所有出现的tle问题。
六、 阐述对规格撰写和理解上的心得体会
经过这个单元对JML规格语言的学习,我已经在大体上掌握了这种规格的使用方法。在我看来,这种语言主要是与“面向对象”的思想相结合,表示“希望下一步能得到怎样的状态”,而不是“下一步具体要进行怎样的动作”,即,是“状态”描述,而不是“动作”。但是,可能是因为在课下作业中,主要是阅读已经给出的JML规格,写相应的代码,而完成代码部分似乎也与数据结构的图论部分关系更加密切,只是在一次课上完成过写JML规格的练习,所以,我更能阅读JML规格,而相对而言不太能写JML规格,易于存在不完善的地方。
总体而言,JML语言可以很好的用“面向对象”的思想描述一个函数的功能,在实际的编程、特别是合作编程中,具有极大的交流合作方面的可操作性,因此其重要性不言而喻,值得拿出一个单元专门训练。















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









