






上得厅堂,下得厨房,写得代码,翻得围墙,欢迎来到睿不可挡的每日一小练!
题目:按字典顺序列出全部子集
内容:
请写一个程序用字典顺序把一个{1,2,3,4,...,n}集合的全部子集找出来。
解答:
想必我就不用解释什么是字典顺序了,作为乘虚猿和攻城狮大家应该懂得,无论你懂不懂,反正我懂了!
事实上我们能够先列出一个实例,观察规律:
比如n=3
{1}
{1,2}
{1,2,3}
{1,3}
{2}
{2,3}
{3}
能够看出这种规律(假设你说我怎么没看出来,事实上你能够再多看一会!)
令一个指针指向第一个元素,假设指针指向的元素小于n就使指针加一,后指针指向元素等于指针指向前一个元素加一。当指针指向元素等于n时,指针回指一位即指针减一,指针指向元素加以,当指针指向位置为初始位置时,指向元素等于n则输出结束了。
事实上这个规律也不是观察实例得出的,这就是我们在按字典排序时做的事情,仅仅只是人的大脑速度太快,非常多过程一步到位而已,假设不信,你拿出一本字典慢慢尝试看看是不是这种!
我的解法:上来没多想,打开vs2013就敲了起来,问题果然非常easy,分分钟就超神。。奥,不正确就攻克了!
#include <iostream>
using namespace std;
int _tmain(int argc, _TCHAR* argv[])
{
void subsetInDic(int n);
int n;
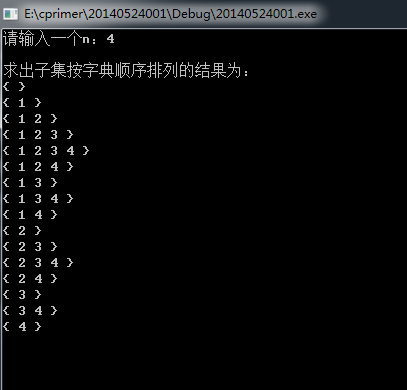
cout << "请输入一个n:";
cin >> n;
cout << endl;
cout << "求出子集按字典顺序排列的结果为:" << endl;
subsetInDic(n);
getchar();
getchar();
return 0;
}
void subsetInDic(int n)
{
int i,j,set_Index = 0;
int subsetNum[1000];
subsetNum[set_Index] = 1;
cout << "{ }" << endl;
while (true)
{
cout << "{ ";
for (i = 0; i <= set_Index; i++)
cout << subsetNum[i] << " ";
cout << "}";
cout << endl;
if (subsetNum[set_Index] < n)
{
subsetNum[set_Index + 1] = subsetNum[set_Index] + 1;
set_Index++;
}
else if (set_Index != 0)
subsetNum[--set_Index] += 1;
else
break;
}
}
最后感谢 @hikean 同学在 《列出全部子集》中给给出的更简便,效率更快的方法。欢迎大家能给出更好的方法!
欢迎大家添�每日一小练,嘿嘿!
每天练一练,日久见功夫,加油!
-End-
參考文献:《c语言名题精选百则》















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









