






多进程模板
1、多进程获取url的前20个字符
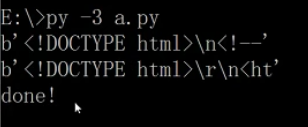
#coding=utf-8 import multiprocessing import urllib.request import time def func1(url) : response = urllib.request.urlopen(url) html = response.read() print(html[0:20]) time.sleep(1) def func2(url) : response = urllib.request.urlopen(url) html = response.read() print(html[0:20]) time.sleep(1) if __name__ == '__main__' : p1 = multiprocessing.Process(target=func1,args=("http://www.sogou.com",),name="gloryroad1") p2 = multiprocessing.Process(target=func2,args=("http://www.baidu.com",),name="gloryroad2") p1.start() p2.start() p1.join() p2.join() time.sleep(1) print("done!")
运行结果














 2006
2006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









