






基本任务
1.Github项目地址
https://github.com/LXL1314/WordCount
2.PSP表格填写
| PSP2.1 | PSP阶段 | 预估耗时 (分钟) | 实际耗时 (分钟) |
| Planning | 计划 | 20 | 20 |
| Estimate | 估计这个任务需要多少时间 | 1180 | 1250 |
| Development | 开发 | 480 | 540 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 90 |
| Design Spec | 生成设计文档 | 60 | 30 |
| Design Review | 设计复审 (和同事审核设计文档) | 30 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 50 | 20 |
| Design | 具体设计 | 120 | 60 |
| Coding | 具体编码 | 360 | 480 |
| Code Review | 代码复审 | 120 | 70 |
| Test | 测试(自我测试,修改代码,提交修改) | 180 | 300 |
| Reporting | 报告 | 30 | 30 |
| Test Report | 测试报告 | 60 | 80 |
| Size Measurement | 计算工作量 | 30 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 30 |
| 合计 | 2840 | 3040 |
3.接口的实现
WordCount为整个任务的核心类,需要完成单词的词频统计以及排序任务。
变量:
| 序号 | 变量名 | 类型 | 说明 |
| 1 | file_path | String | 文件名(路径名) |
| 2 | fileContent | String | 要统计的.txt文件的内容 |
| 3 | words | String[] | .txt文件分割出的所有的单词数组 |
| 4 | words_frequency_list | List<Map.Entry<String, Integer>> | 单词及其频率的list |
变量getter和setter方法:
| 序号 | 变量 | 变量方法 | 方法说明 | 返回类型 | 参数 | 参数说明 |
| 1 | file_path | setFile_path() | 设置file_path | void | String file_path | 文件路径 |
| getFile_path() | 返回file_path | String | 无 | 无 | ||
| 2 | fileContent | setFileContent() | 设置fileContent | void | String fileContent | 文件内容 |
| getFileContent() | 返回fileContent | String | 无 | 无 | ||
| 3 | words | setWords() | 设置words | void | String[] words | 字符数组 |
| getWords() | 返回words | String[] | 无 | 无 | ||
| 4 | words_frequency_list | setWords_frequency_list() | 设置words_frequency_list | void | List<Map.Entry<String, Integer>> words_frequency_list | 单词及单词频率list |
| getWords_frequency_list() | 返回words_frequency_list | List<Map.Entry<String, Integer>> | 无 | 无 |
主要类方法:
| 序号 | 方法名 | 说明 | 返回类型 | 参数 |
| 1 | readFileToString() | 将文件内容读出,并存进字符串fileContent中 | void | 无 |
| 2 | splitWords() | 将fileContent分割为单词,并将各单词存进数组words中 | void | 无 |
| 3 | wordsFrequency() | 统计单词频率,并将单词及其频率存进list变量words_frequency_list中 | void | 无 |
| 4 | wordsSort() | 将统计后的频率按频率总高到低排序,且频率相同的按a-z排序,排序后存进list变量words_frequency_list中 | void | 无 |
主要类方法的实现(实现思路见注释):
readFileToString():


1 //1,读取文件内容,并将内容存到字符串fileContent中 2 public void readFileToString() throws IOException { 3 File file = new File(getFile_path()); 4 if(file.exists() == false) 5 file.createNewFile(); 6 BufferedReader br = new BufferedReader(new FileReader(file)); 7 String content=""; 8 StringBuilder sb = new StringBuilder(); 9 while((content = br.readLine()) != null){ 10 sb.append(content+"\r\n"); 11 } 12 br.close(); 13 setFileContent(sb.toString());//sb.toString()是将StringBuilder变量sb转化为String类型 14 }
splitWords():
1 //2,分割出单词,并将分割后的各单词存入到String类型数组words中 2 public void splitWords() { 3 char[] cha = getFileContent().toCharArray();//将fileContent转化为cha数组 4 String token=""; 5 //构建动态数组,存单词 6 ArrayList<String> fileWords=new ArrayList<String>(); 7 int len=0; 8 //分割单词 9 for(int i=0;i<cha.length;i++) { 10 if((97<=cha[i]&&cha[i]<=122)||(65<=cha[i]&&cha[i]<=90)) {//如果该字符是字母 11 token=token+cha[i]; 12 if(i==cha.length-1) {//如果该字符是字母,且为最后一个字符,则token=token+cha[i] 13 fileWords.add(token); 14 len=len+1; 15 token=""; 16 } 17 //如果该字符是字母,且不为最后一个字符 18 else if(cha[i+1]!=45&&(cha[i+1]<65||(cha[i+1]>90&&cha[i+1]<97)||cha[i+1]>122)) {//若下一个字符不为短横线“-”且不为字母,则分割单词 19 fileWords.add(token); 20 len=len+1; 21 token=""; 22 } 23 } 24 //此字符不为字母 25 else if(i>0&&i<cha.length-1&&cha[i]==45) { //对于最开始和最后面的一个非字母的字符直接忽略,若该字符为短横线“-”, 26 if(((97<=cha[i-1]&&cha[i-1]<=122)||(65<=cha[i-1]&&cha[i-1]<=90))&&((97<=cha[i+1]&&cha[i+1]<=122)||(65<=cha[i+1]&&cha[i+1]<=90))) 27 //若短横线的前一个和后一个字符都是字母,则把短横线加入token 28 token=token+cha[i]; 29 if(((97<=cha[i-1]&&cha[i-1]<=122)||(65<=cha[i-1]&&cha[i-1]<=90))&&(cha[i+1]<65||(cha[i+1]>90&&cha[i+1]<97)||cha[i+1]>122)) { 30 //若短横线前一个字符为字母,后一个不为字母,则分割 31 fileWords.add(token); 32 len=len+1; 33 token=""; 34 } 35 } 36 } 37 //将ArrayList<String>动态数组转化为String类型数组 38 int size=fileWords.size(); 39 String[] wordsArray = (String[])fileWords.toArray(new String[size]); 40 setWords(wordsArray); 41 }
wordsFrequency():
1 //3,将单词和单词的频率存入到List<Map.Entry<String, Integer>>类型变量words_frequency_list中 2 public void wordsFrequency() { 3 Map<String, Integer> map = new HashMap<String, Integer>(); 4 for (String word:getWords()) { 5 if(map.containsKey(word)) //若map中存在KEY为该单词,则让该键所对应的value加1 6 map.put(word, map.get(word)+1); 7 else //若不存在,则添加KEY为该单词,value为1 8 map.put(word, 1); 9 } 10 // map转换成list进行排序 11 List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String,Integer>>(map.entrySet()); 12 setWords_frequency_list(list); 13 }
wordsSort():
1 //4,单词词频排序,words_frequency_list按词频降序排序 2 public void wordsSort() { 3 Comparator<Map.Entry<String, Integer>> valueComparator = new Comparator<Map.Entry<String,Integer>>() { 4 @Override 5 public int compare(Entry<String, Integer> o1, 6 Entry<String, Integer> o2) { 7 // TODO Auto-generated method stub 8 if(o1.getValue()!=o2.getValue()) 9 return o2.getValue().compareTo(o1.getValue());//值按降序排序 10 else 11 return o1.getKey().toLowerCase().compareTo(o2.getKey().toLowerCase());//值相等,则按键(全转化为小写字母)a-z排序,即升序 12 } 13 }; 14 //将words_frequency_list按词频降序排序 15 Collections.sort(getWords_frequency_list(),valueComparator); 16 }
4.说明如何考虑测试用例的设计,如何满足测试效率的要求
对于黑盒测试,由于对于程序的内部结构等是完全没有了解的,所以黑盒测试是随意输入测试数据,或者根据需求去设计测试用例,看用例的结果是否符合需求。
对于白盒测试,程序结构等对我们是可见的,所以在做白盒测试时,找到程序的各个分支等,根据分支设计测试用例。
测试用例截图:
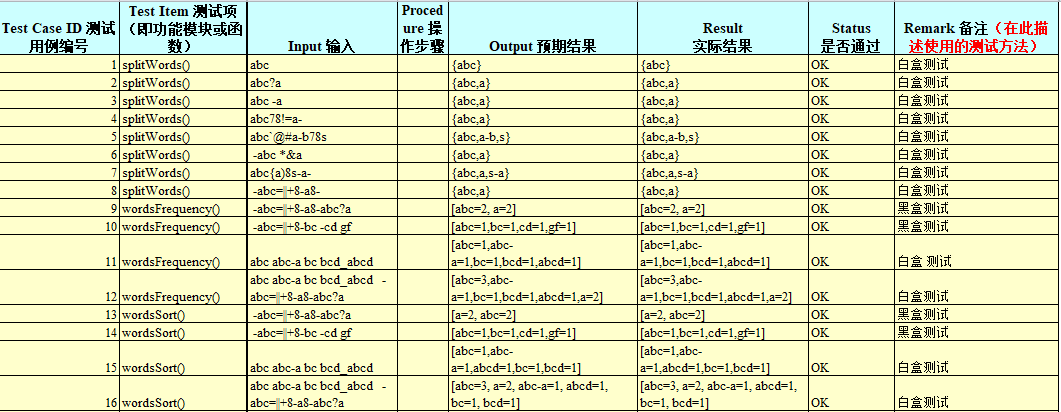

5.给出单元测试的运行截图,评价测试质量和被测模块的质量
运行截图如下:

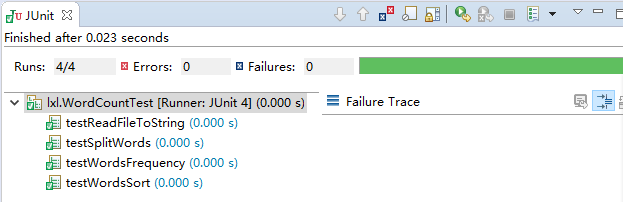
测试质量分析:
测试模块中,testSplitWords()的预期结果要提前写入到words.txt文件中,且对格式有要求,即单词之间只以“,”分隔,不能加空格等其他任何符号,且最后一个单词后面不能加任何符号;testWordsFrequency()也要的预期结果要提前写入到words.txt文件中,但是还要对其进行处理,即将words.txt文件中单词进行统计并将单词和单词频率用List<Map.Entry<String, Integer>>类型变量保存。testWordsSort()的预期结果要提前写入到wordSort.txt文件中,wordSort.txt文件中每行为单词和单词频率,两者以空格分隔。测试代码秩序修改inputPath的值就能够达到测试代码的复用,且测试脚本中可以看到预期结果和实际输出结果。所以整体上来说测试代码的质量良好。但是由于预期结果要先输入到指定文件中,由于对输入的格式有要求,而且输入预期结果很有可能出现人为错误,可能导致测试结果错误(实际结果正确,因输入预期结果有误而到时测试结果错误)。
被测模块质量分析:
被测试模块质量良好。能够完成所规定的所有功能,如单词分割及频率统计,频率排序等,并且结果正确。
6.个人的小组贡献分
见毕博
扩展部分
1.说明选择了哪种开发规范文档中的哪一部分
选择了阿里巴巴java开发手册的命名风格部分
2.说明使用该规范分析了哪位组员(说明学号后5位即可)的代码,并说明其代码有什么问题,或者说明其代码遵循了哪些好的规范。
分析了17096同学的代码,存在以下问题:
(1)小部分变量名,方法名等使用下划线进行连接,而不是使用驼峰式命名规则
遵循了的好的规范:
(1)大部分方法名,变量名都是使用驼峰式命名方式
(2)类型与中括号紧挨相连来定义数组
(3)代码中的命名未使用拼音与英文混合的方式,也没有直接使用中文的方式
3.静态检查工具及下载地址
PMD: https://dl.bintray.com/pmd/pmd-eclipse-plugin/updates/(在eclipse中在线安装)
4.工具对代码扫描的结果和界面运行截图,并说明代码存在的问题和改进的方法
改进前:
扫描的结果和界面运行截图:
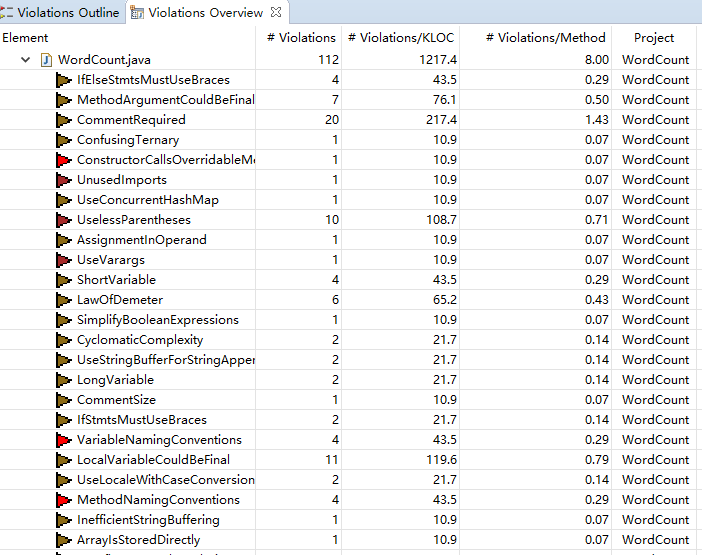
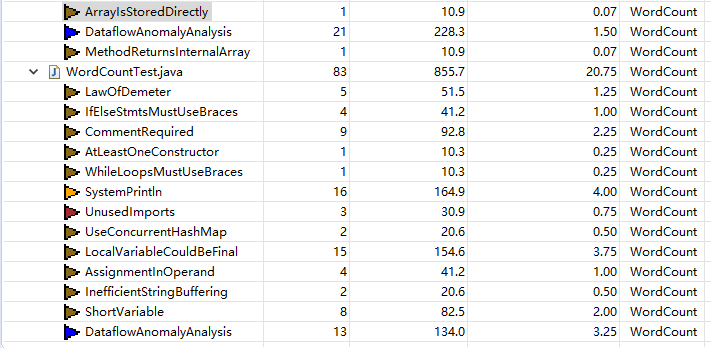
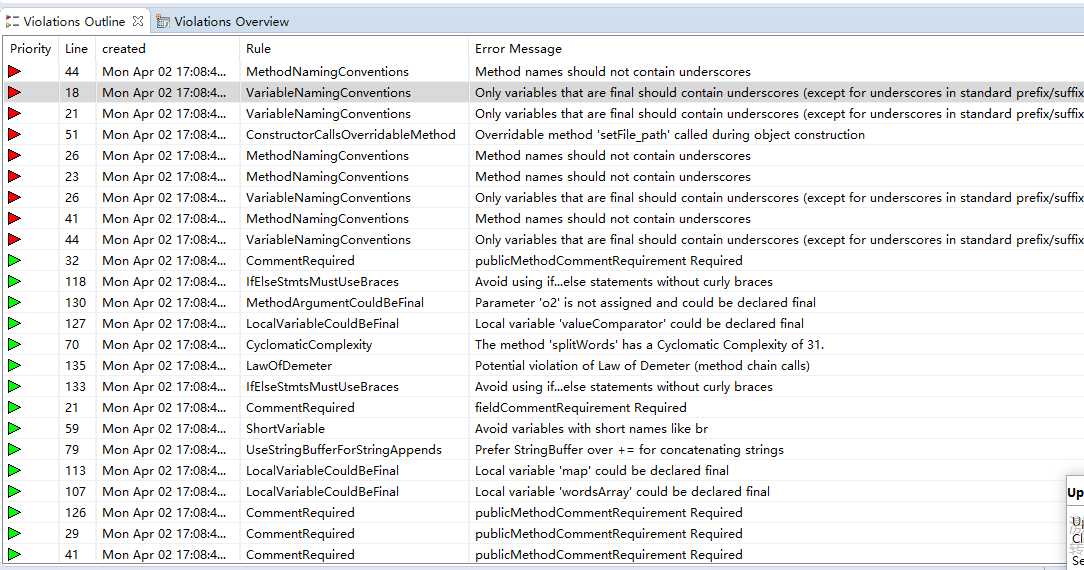
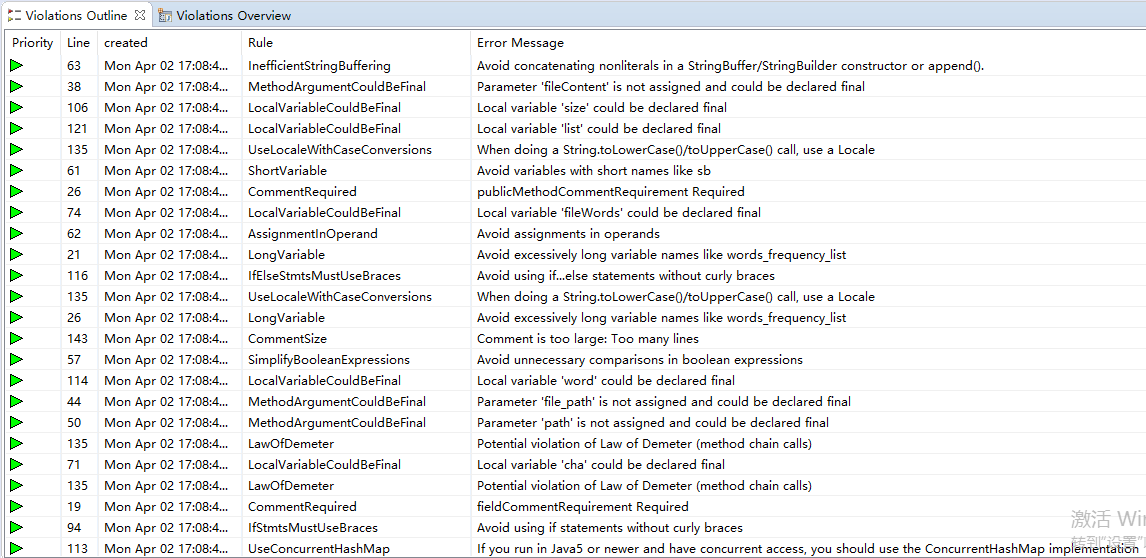
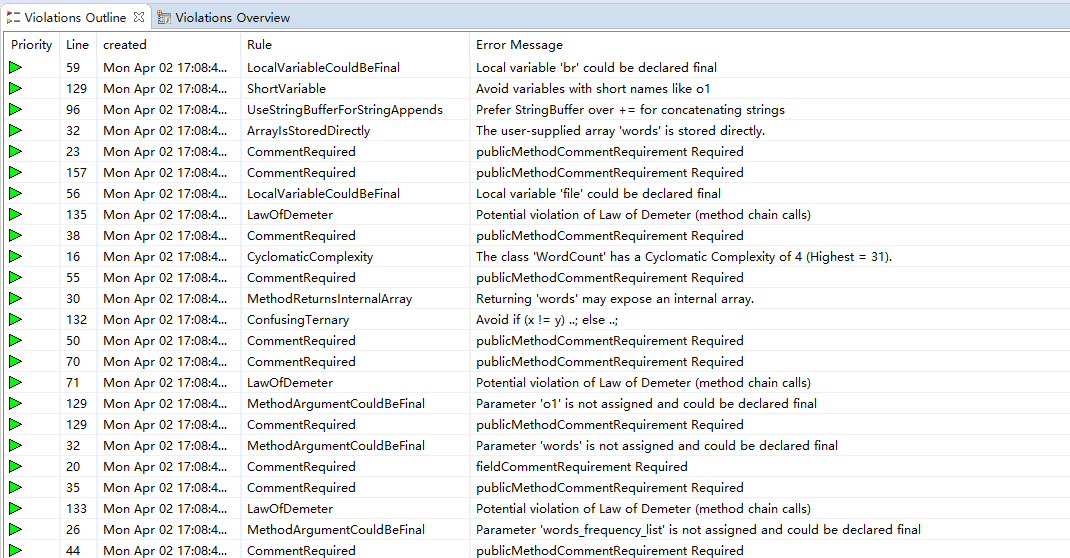
代码存在的问题和改进的方法:
| 存在的问题 | 改进方法 |
| 变量名,方法名等使用下划线进行连接 | 改用驼峰式 |
| import未使用到的包 | 删除多余的import语句 |
| 构造方法中调用重写的方法 | 直接在构造函数中为变量赋值,而不使用其setter方法 |
| 字符串连接形如:str = str +“a”; | 改为形如:str += “a”; |
| 布尔表示式中不必要的比较 | 去掉布尔表示式中不必要的比较 |
| 调用链导致效率低 | 拆分调用链 |
| 存在多余的括号 | 去掉多余的括号(为了阅读方便,适当保留一些多余的括号,使得代码更容易阅读) |
改进后:
扫描的结果和界面运行截图:
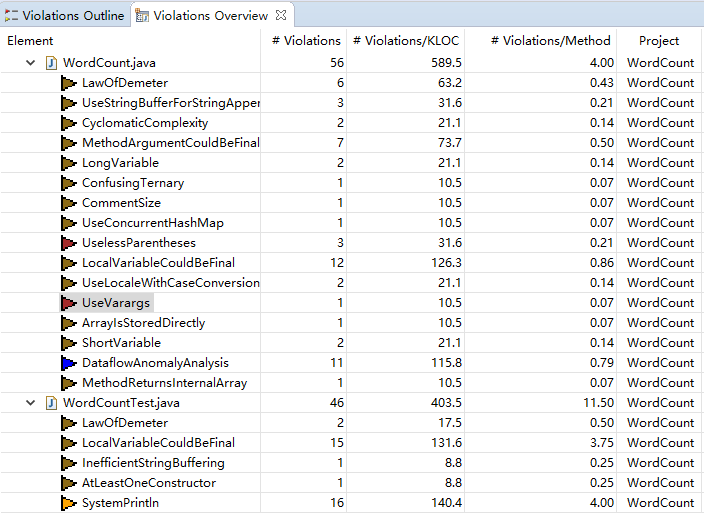

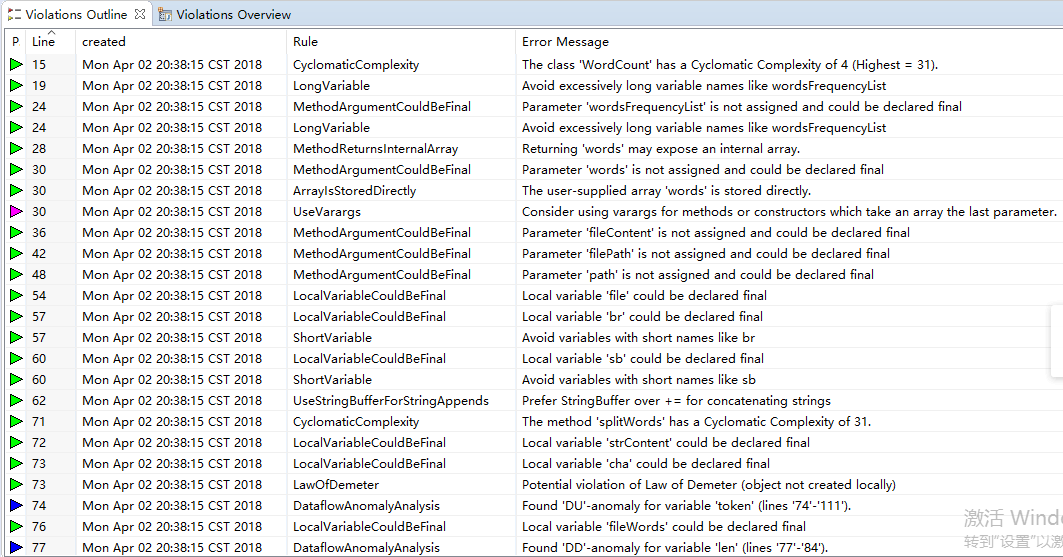
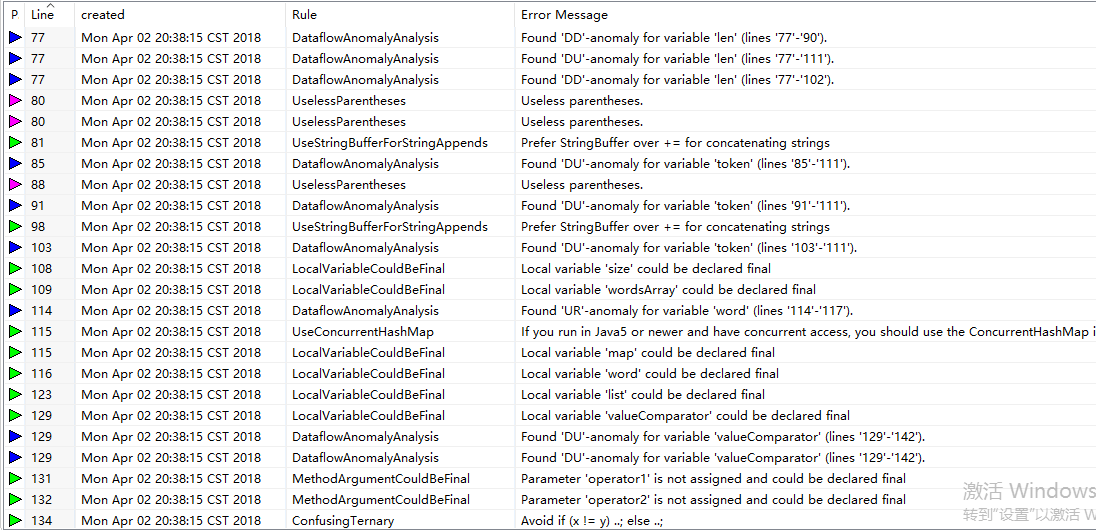

总结:进行静态扫描,并改进后:WordCount类和WordCountTest类的错误减少了一半。
5.说明整个小组的代码主要存在的问题,并说明代码改进的方法,最好能给出图、表等形式。
代码主要的问题,部分变量名和方法名没有遵循驼峰式的命名方式,一些变量的初始化不正确等。

















 3504
3504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









