






【分布的拟合】
把样本的分布函数(也称为“经验分布函数”),与某种理论的分布函数(如正态分布)叠放在一起,进行比較。
比如:
score = xlsread('examp02_14.xls','Sheet1','G2:G52');
% 去掉总成绩中的0。即缺考成绩
score = score(score > 0); %样本
figure; % 新建图形窗体
% 绘制经验分布函数图,并返回图形句柄h和结构体变量stats,
% 结构体变量stats有5个字段。分别相应最小值、最大值、平均值、中位数和标准差
[h,stats] = cdfplot(score);
set(h,'color','k','LineWidth',2); % 设置线条颜色为黑色,线宽为2
%************************绘制理论正态分布函数图******************************
x = 40:0.5:100; % 产生一个新的横坐标向量x
% 计算均值为stats.mean。标准差为stats.std的正态分布在向量x处的分布函数值
y = normcdf(x,stats.mean,stats.std);
hold on
% 绘制正态分布的分布函数曲线,并设置线条为品红色虚线。线宽为2
plot(x,y,':k','LineWidth',2);
% 加入标注框,并设置标注框的位置在图形窗体的左上角
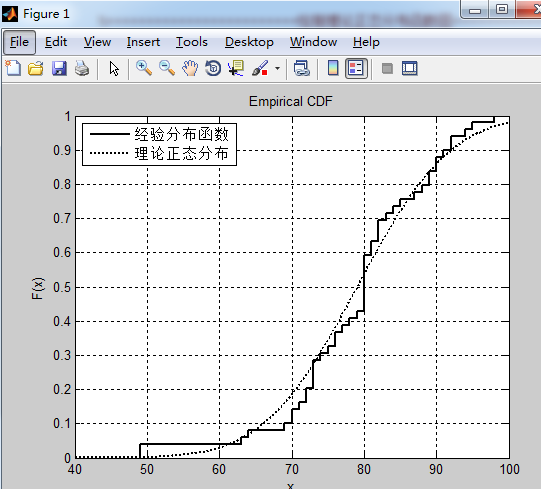
legend('经验分布函数','理论正态分布','Location','NorthWest');结果:
由图可知该样本近似服从正态分布。
【分布的检验】
(1)利用kstest函数检验单个样本是否服从指定分布(双側检验)。或者是否在指定的分布函数之下或之下(单側检验)。注意这里的分布是全然确定的,不含未知參数。
比如:
% 读取文件examp02_14.xls的第1个工作表中的G2:G52中的数据,即总成绩数据
score = xlsread('examp02_14.xls','Sheet1','G2:G52');
% 去掉总成绩中的0,即缺考成绩
score = score(score > 0);
% 生成cdf矩阵。用来指定分布:均值为79,标准差为10.1489的正态分布
cdf = [score, normcdf(score, 79, 10.1489)];
% 调用kstest函数,检验总成绩是否服从由cdf指定的分布
[h,p,ksstat,cv] = kstest(score,cdf)注意:
结果:
由h=0,p=0.5486>0.05知接受如果,即觉得总成绩服从均值为79,标准差为10.1489的正态分布。

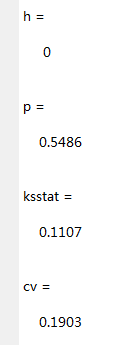
(2)利用ktest2函数检验两个样本是否服从同样的分布(双側检验),或者检验一个样本的分布函数是否在还有一个样本的分布函数之上或者之下(单側检验),ktest2函数对照两个样本的经验分布函数,即这里的分布也是确定的。
【例1】:
% 读取文件examp02_14.xls的第1个工作表中的B2:B52中的数据,即班级数据
banji = xlsread('examp02_14.xls','Sheet1','B2:B52');
% 读取文件examp02_14.xls的第1个工作表中的G2:G52中的数据,即总成绩数据
score = xlsread('examp02_14.xls','Sheet1','G2:G52');
% 去除缺考数据
score = score(score > 0);
banji = banji(score > 0);
% 分别提取60101和60102班的总成绩
score1 = score(banji == 60101);
score2 = score(banji == 60102);
% 调用kstest2函数检验两个班的总成绩是否服从同样的分布
[h,p,ks2stat] = kstest2(score1,score2)
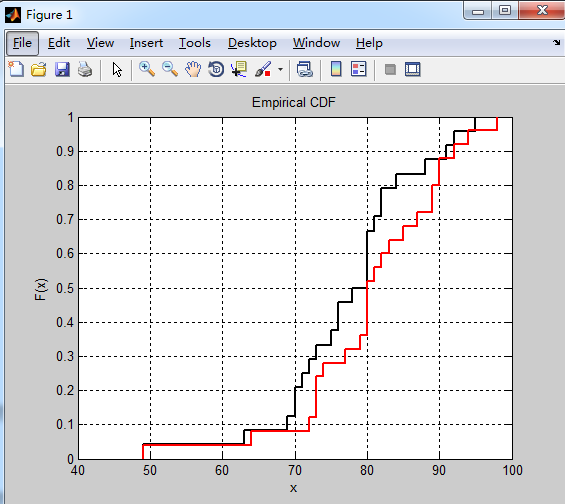
[h1,stats1] = cdfplot(score1);%绘制score1的经验分布函数图,并返回图形句柄h1和结构体变量stats1
set(h1,'color','k','LineWidth',2);
hold on
[h2,stats2] = cdfplot(score2);%绘制score2的经验分布函数图,并返回图形句柄h2和结构体变量stats2
set(h2,'color','r','LineWidth',2); 结果:
由h=0,p=0.7016>0.05故接受如果,即觉得两个班级的总成绩服从同样的分布.
【例2】:利用ktest2完毕(1)中例题
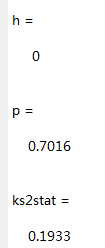
score = xlsread('examp02_14.xls','Sheet1','G2:G52');
% 去除缺考数据
score = score(score > 0);randn('seed',0) % 指定随机数生成器的初始种子为0
% 产生10000个服从均值为79。标准差为10.1489的正态分布的随机数,构成一个列向量x
x = normrnd(mean(score),std(score),10000,1);
% 调用kstest2函数检验总成绩数据score与随机数向量x是否服从同样的分布
[h,p] = kstest2(score,x,0.05)结果:
由h=0,p=0.5138>0.05知接受如果,即觉得总成绩服从均值为79,标准差为10.1489的正态分布。
(3)利用lillietest函数检验样本是否服从指定的分布(默认情况下为正态分布),注意这里分布的參数是依据样本预计的。
【例1】:
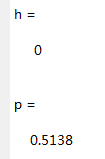
score = xlsread('examp02_14.xls','Sheet1','G2:G52');
% 去除缺考数据
score = score(score > 0);
% 调用lillietest函数进行Lilliefors检验,检验总成绩数据是否服从正态分布
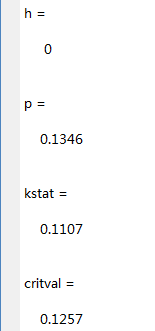
[h,p,kstat,critval] = lillietest(score)结果:
由h=0,p=0.1346>0.05可知接受如果。即觉得总成绩服从正态分布,该分布的均值、方差由样本均值和方差取代。
【例2】:
score = xlsread('examp02_14.xls','Sheet1','G2:G52');
% 去除缺考数据
score = score(score > 0);
% 调用lillietest函数进行Lilliefors检验,检验总成绩数据是否服从指数分布
[h, p] = lillietest(score,0.05,'exp')结果:
由h=1,p<0.05知拒绝如果。即觉得总成绩不服从指数分布
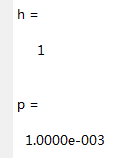














 621
621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









