






简单的网络爬虫是对一个url进行请求,并等待其返回响应。在数据量小的情况下很实用,但是当你的数据量很大,显然分布式爬虫就更占优势!关于分布式,一般是使用一台主机(master)充当多个爬虫的共享redis队列,其他主机(slave)采用远程连接master,关于redis如何安装,这里不多做介绍!
以爬虫伯乐在线的python文章为例,我的分布式爬虫由main01 main02 main03三个python文件构成,main01的主要任务是运行在master上,将文章的url爬取下来存入redis以供main02和main03读取解析数据。main01的主要代码如下:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
from redis import Redis
from lxml import etree
r = Redis.from_url("redis://x.x.x.x:6379", decode_responses=True)
def get_urls(url="http://python.jobbole.com/all-posts/"):
result = requests.get(url=url)
selector = etree.HTML(result.text)
links = selector.xpath(r'//*[@id="archive"]/div/div[2]/p[1]/a[1]/@href')
for link in links:
r.sadd("first_urls", link)
next_url = extract_next_url(result.text)
if next_url:
get_urls(next_url)
def extract_next_url(html):
soup = BeautifulSoup(html, "lxml")
next_url = soup.select('a[class="next page-numbers"]')
for url in next_url:
url = str(url)
soup = BeautifulSoup(url, "lxml")
next_url = soup.a["href"]
return next_url
if __name__ == '__main__':
get_urls()
从本地连接master的redis可以看到,数据已经成功写入redis
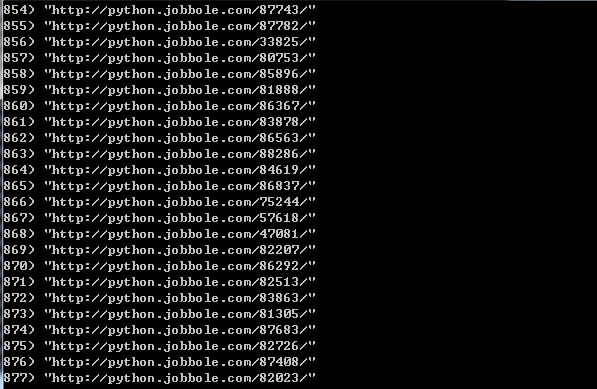
下面是main02的代码:
# -*- coding: utf-8 -*-
import json
import codecs
import requests
from redis import Redis
from lxml import etree
from settings import *
import MySQLdb
r = Redis.from_url(url=REDIS_URL, decode_responses=True)
def parse_urls():
if "first_urls" in r.keys():
while True:
try:
url = r.spop("first_urls")
result = requests.get(url=url, timeout=10)
selector = etree.HTML(result.text)
title = selector.xpath(r'//*[@class="entry-header"]/h1/text()')
title = title[0] if title is not None else None
author = selector.xpath(r'//*[@class="copyright-area"]/a/text()')
author = author[0] if author is not None else None
items = dict(title=title, author=author, url=url)
insert_mysql(items)
except:
if "first_urls" not in r.keys():
print("爬取结束,关闭爬虫!")
break
else:
print("{}请求发送失败!".format(url))
continue
else:
parse_urls()
def insert_json(value):
file = codecs.open("save.json", "a", encoding="utf-8")
line = json.dumps(value, ensure_ascii=False) + "," + "\n"
file.write(line)
file.close()
def insert_mysql(value):
conn = MySQLdb.connect(MYSQL_HOST, MYSQL_USER, MYSQL_PASSWORD, MYSQL_DBNAME, charset="utf8", use_unicode=True)
cursor = conn.cursor()
insert_sql = '''
insert into article(title, author, url) VALUES (%s, %s, %s)
'''
cursor.execute(insert_sql, (value["title"], value["author"], value["url"]))
conn.commit()
if __name__ == '__main__':
parse_urls()
main02和main03(同main02的代码可以一样)可以运行在你的本地机器,在main02中我们会先判断master的redis中是否已经生成url,如果没有main02爬虫会等待,直到master的redis存在url,才会进行下面的解析!
运行main02可以发现本地的mysql数据库中已经成功被写入数据!
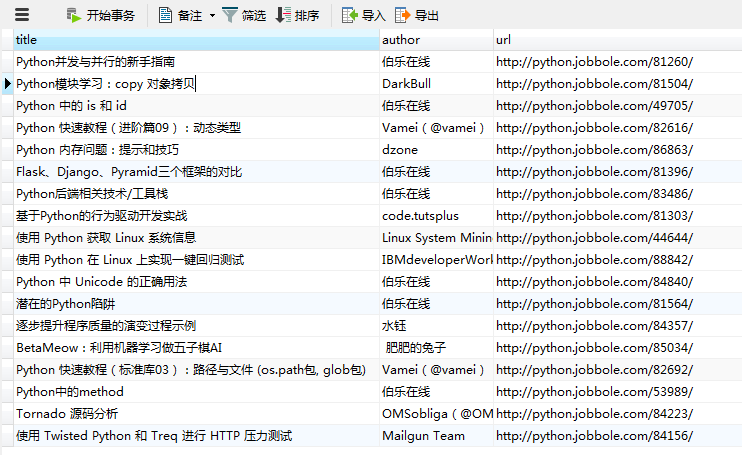
以上就是一个简单的分布式爬虫,当然真正运行的时候,肯定是几个爬虫同时运行的,这里只是为了调试才先运行了main01!
















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









