






背景
首先什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。
为了拓展视野、接触一些从未接触过的东西(废话),就有了这篇blog 难道你要我说我是闲得蛋疼来搞搞正
咳咳,正题正题
基础知识
- python(废话)
- urllib和urllib2 库的用法
- 正则表达式挂逼一样的利器
大概就是这样了
顺便说一下我用的是python 2.7,系统自带也就懒得装别的了
实现功能?
在贴吧上抓一些图♂片并且保存到本地
话说熟能生巧是tm真的,写一个晚上已经很熟练了
import urllib2
import urllib
import re
def getHtml(url):
headers={'User-Agent':'Mozilla/5.0 (compatible; MSIE 5.5; Windows NT)'}#浏览器认证,大多数网站都需要
request=urllib2.Request(url,headers=headers)#构造一个带认证的网页请求
html=urllib2.urlopen(request)
return html.read()#返回扒下来的整个网页内容,也就是“查看源代码”的内容
def rollFunc(blocknum, blocksize, totalsize):
percent=100.0*blocknum*blocksize/totalsize#计算下载的百分比
if percent>100:#精度处理
percent=100
print "%.2f%%"%percent
def downPic(html,count,path):
reg=re.compile(r'src="(.+?\.jpg)" pic_ext="(.+?)"')#字符串的匹配,找到带有src="*.jpg"的项,也就是网页上的图片
piclist=re.findall(reg,html)#找到所有符合我们匹配条件的项,返回值是个list(啊啊啊太好用了会上瘾的)
for pic in piclist:
fmt=pic[-1][-3]+pic[-1][-2]+pic[-1][-1]
if fmt=='peg':
fmt='j'+fmt
count+=1
print 'downloading '+pic[0]
urllib.urlretrieve(pic[0],path+'%s.'%count+fmt,rollFunc)#调用retrieve保存图片,其实别的格式也是可以的,这里只是抓jpg
#使用格式urllib.urlretrieve(url,path路径,回调函数)
print 'DONE!'
count=0
url='http://tieba.baidu.com/p/2460150866'
path=raw_input('PATH:')
html=getHtml(url)
downPic(html,count,path)运行结果截图:
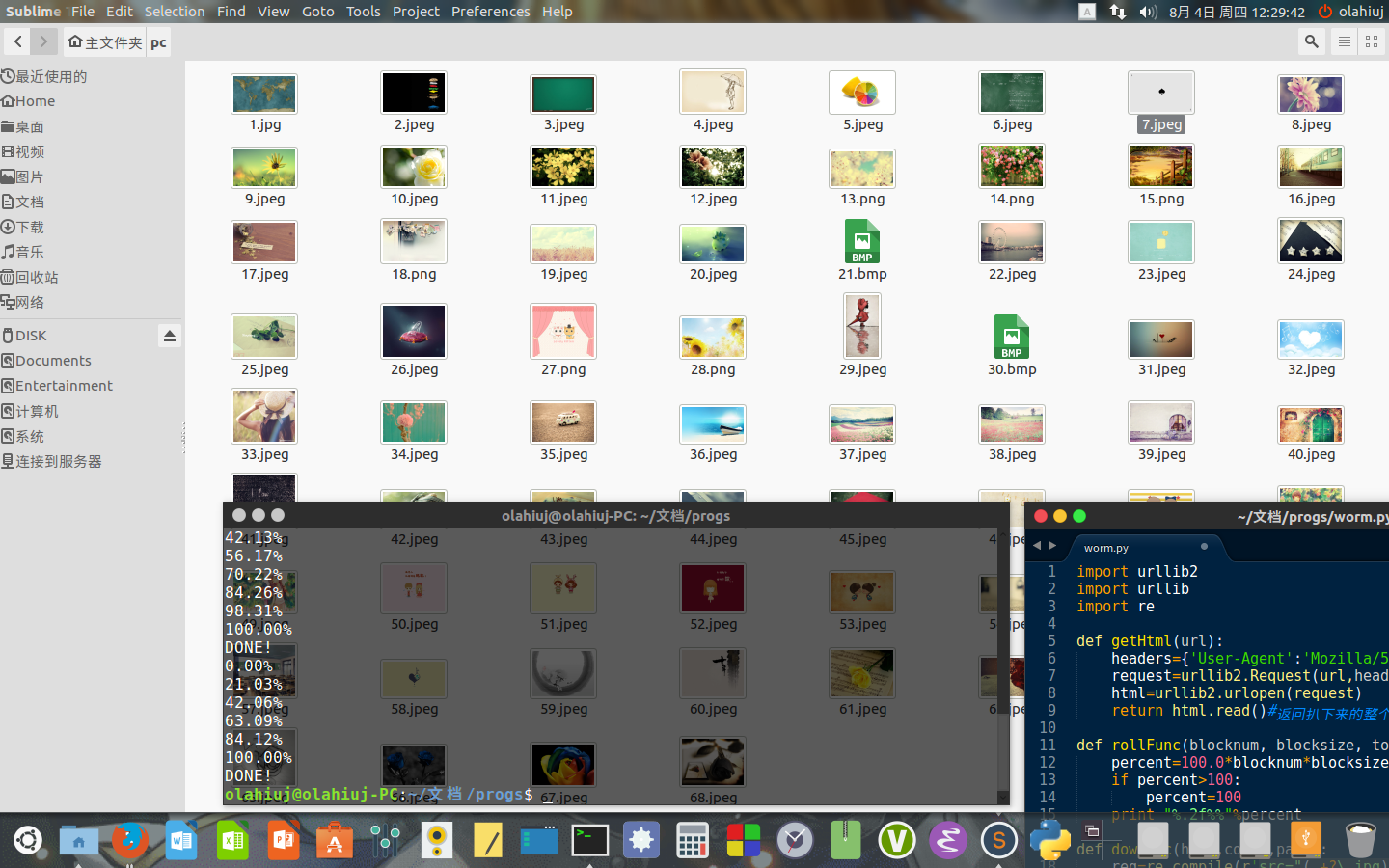
然而图片格式的问题仍然没有解决(如果不是处女座就TM不是问题),先放着吧
最后说一句















 76万+
76万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









