






# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python # For example, here's several helpful packages to load in import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) # Input data files are available in the "../input/" directory. # For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
import os, sys import numpy as np import pandas as pd import matplotlib.pyplot as plt import skimage.io from skimage.transform import resize from imgaug import augmenters as iaa from tqdm import tqdm import PIL from PIL import Image, ImageOps import cv2 from sklearn.utils import class_weight, shuffle from keras.losses import binary_crossentropy from keras.applications.resnet50 import preprocess_input import keras.backend as K import tensorflow as tf from sklearn.metrics import f1_score, fbeta_score from keras.utils import Sequence from keras.utils import to_categorical from sklearn.model_selection import train_test_split
WORKERS = 2 CHANNEL = 3 import warnings warnings.filterwarnings("ignore") IMG_SIZE = 512 NUM_CLASSES = 5 SEED = 77 TRAIN_NUM = 1000 # use 1000 when you just want to explore new idea, use -1 for full train
df_train = pd.read_csv('F:\\kaggleDataSet\\diabeticRetinopathy\\trainLabels19.csv') df_test = pd.read_csv('F:\\kaggleDataSet\\diabeticRetinopathy\\testImages19.csv') x = df_train['id_code'] y = df_train['diagnosis'] x, y = shuffle(x, y, random_state=SEED)
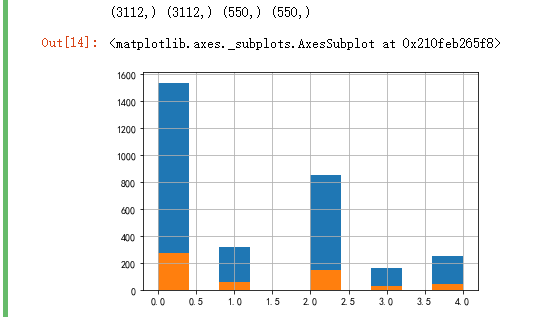
train_x, valid_x, train_y, valid_y = train_test_split(x, y, test_size=0.15,stratify=y, random_state=SEED) print(train_x.shape, train_y.shape, valid_x.shape, valid_y.shape) train_y.hist() valid_y.hist()
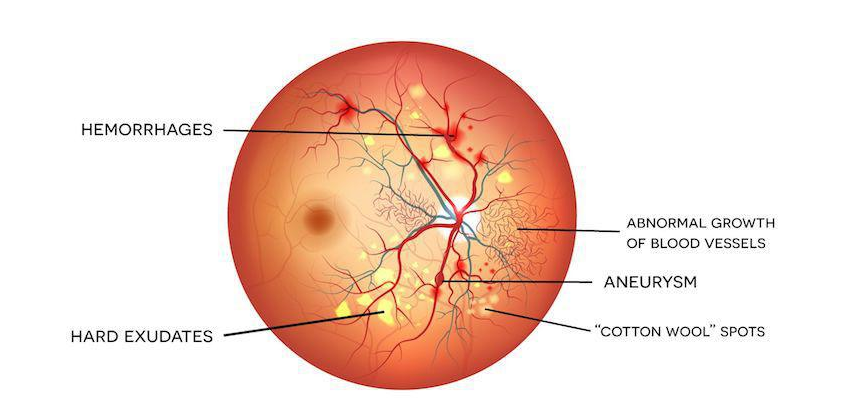







%%time fig = plt.figure(figsize=(25, 16)) # display 10 images from each class for class_id in sorted(train_y.unique()): for i, (idx, row) in enumerate(df_train.loc[df_train['diagnosis'] == class_id].sample(5, random_state=SEED).iterrows()): ax = fig.add_subplot(5, 5, class_id * 5 + i + 1, xticks=[], yticks=[]) path="F:\\kaggleDataSet\\diabeticRetinopathy\\resized train 19\\"+str(row['id_code'])+".jpg" image = cv2.imread(path) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = cv2.resize(image, (IMG_SIZE, IMG_SIZE)) plt.imshow(image) ax.set_title('Label: %d-%d-%s' % (class_id, idx, row['id_code']) )
















 2392
2392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









