






本章开始介绍图数据结构和相关的算法。一个图有两个部分组成,跟前面介绍的树结构一样,一部分是节点,在图的术语中也称为顶点(vertex),我们将统一称之为顶点;另一部分是顶点的链接,称为边(edge)。顶点和边之间有着紧密的联系,通常图的任意一对顶点之间都允许有一条边。前几章介绍的链表和树都可以看作是结构首先的图,从这个意义上讲,图是最基本的数据结构。
图结构本广泛应用与实际问题的描述和求解,以下几个例子:
1. 地图的坐标点和坐标点之间的连接及距离,求解坐标点之间的最右路径;
2. 交通网络流问题;
3. 通信网络路由算法
…………
本章将给出以上问题的相关抽象模型和问题的求解算法。包括:
术语及描述
.术语及描述
图包括顶点和边,所以一个图可以表示成顶点和边的集合,G=(V, E),其中V表示顶点的集合,E表示变得集合。其中E中每条边都是V集合中某一对顶点的链接。顶点的总数极为|V|,边的总数表示为|E|,通过组合数学知识可以发现,|E|的范围为0到|V|2之间。边数较少的图称为系数图(sparse graph),通常可以用稀疏度来描述系数程度,边数较多的图称为密集图(dense graph)。对系数图和密集图分别有与之相适应的数据结构描述,但在本章中我们不对此进行深入介绍,感兴趣的读者可以参阅图论相关的书籍。
如果边的传递限定为其中一个顶点到另一顶点,即具有方向性限定,则称之为有向图(directed graph)。反之,如果边只表示顶点的连接关系,无方向性限制,则称为无向图(undirected graph)。一条边所连接的两个顶点称为相邻顶点。连接一对相邻顶点u和v的边称为与u和v相关联的边,在无向图中通常记为(u, v)或者(v, u)。在有向图中从u指向v的边记为(u, v),其中u称为源顶点,v称为终顶点。每条边可能附有权值(weight)。边上标有权值的图称为带权图(weighted graph)。在这里我们约定非带权图的权值统一为1,带权图中每条边的权值统一为整数类型。对于非整数的权值可以通过简单的倍数扩展成整数类型。
如果从v1到vn的边均存在,则称顶点序列v1 …vn构成一条长度为n-1的路径(path)。如果路径上的顶点没有重复,则称此路径为简单路径(simple path)。这里的路径长度(length)值得是路径中所包含的边的个数。如果路径中包含重复的顶点,即有顶点连接到它本身,则称此路径为回路,其长度至少为3。如果构成回路的路径为简单路径,其首尾两顶点不同,则称为简单回路。以下为上述不同类型图的图解:
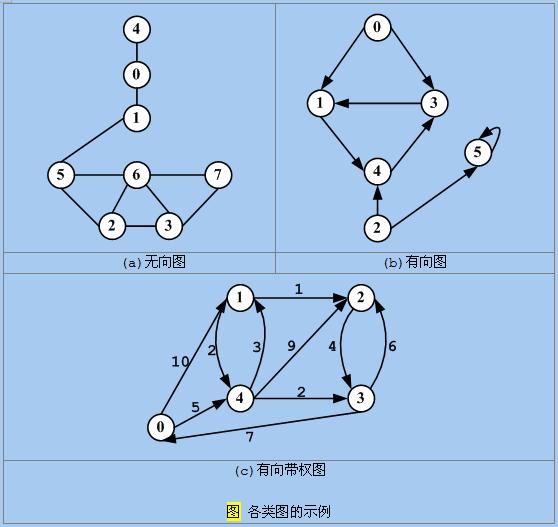
上面我们借助于集合的术语描述了图结构。既然图可以用集合描述,那么图自然存在子图(subgraph)。子图是由图G中顶点集的子集Vs以及与Vs中顶点相关联的一些边所构成的。
如果无向图中任意一个顶点都能通过至少一条路径到达另一个顶点,则称此无向图为联通的(connected)。无向图的最大连通图称为连通分量(connected component)。下图为连通分量的图解:

上图中为一个有向图,其中顶点0,1,2构成一个连通分量,顶点3,4构成第二个连通分量,顶点5单独构成第三个连通分量。
不带回路的图称为无环图(acyclic graph)。不带回路的有向图称为有向无环图(directed acyclic graph 或DAG)。
有两种常见的描述图的数据结构,一种称为相邻矩阵(adjacency matrix)表示法,如图为图中(a)的相邻矩阵。相邻矩阵是一个|V|×|V|的矩阵。对于节点总数为n的图,顶点为v1,…, vn,其相邻矩阵的第i行元素形成的向量Mi·蕴含了顶点vi与其余所有顶点的连接关系。在本书中,我们约定矩阵中值为Integer.MAX_VALUE(无穷大)的元素表示两顶点之间没有边,带权图的顶点vi到vj的边对应着向量Mi·中第j个元素为其边的权值,无权图中顶点vi到vj的边对应着向量Mi·中第j个元素为1。所以,无论两个顶点之间是否有连接,在相邻矩阵中都需要占用一个整数。所以向邻矩阵描述法的空间代价为Θ(|V|2)。

图的另一种常用的表示法为连接表(adjacency list)表示法,如图。连接表是一个以链表为元素的数组。这个数组包含|V|个链表,其中第i链表存储的是顶点vi指向的顶点以及对应边的权值。连接表描述法的空间代价与图的边以及顶点有关。每个顶点都要占用一个数组元素的位置,如果该顶点没有相邻顶点,则该数组位置中链表为空。每条边都包含在链表数组的某个链表中。所以连接表的空间代价为Θ(|V|+|E|)。
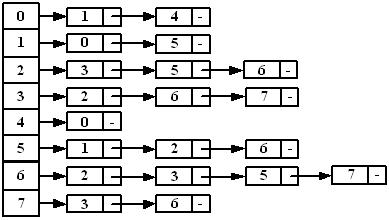
相邻矩阵和邻接表均可用于描述有向图、无向图、带权图和无权图。在无向图中两个顶点之间的连接关系蕴含了顶点u指向顶点v的边和顶点v指向顶点u的边。
这两种描述方法各有优劣,这取决于图中边的个数。连接表中只存储存在的边的信息,而连接矩阵则需要开辟空间用于存储所有顶点之间的连接信息,这样连接表的空间结构比较紧凑。但是连接表中的链表需要指针开销。总的来说,对于稀疏图使用邻接表法比较合适,而稠密图使用相邻矩阵来描述则可获得更高的空间效率。
除了空间开销方面的差别,两种描述方法在某些算法的时间开销上也存在较大的不同。例如,访问顶点vi的某个相邻顶点vj,如果使用连接表,则需要遍历vi所对应的链表中的每个元素项,并判断元素项是否是顶点vj;如果使用相连矩阵,则只需要访问矩阵的Mij项即可。另一方面,如果要访问顶点vi的又有相邻顶点,如果使用连接表,则只需要访问vi所对应的链表中所有元素即可;如果使用相连矩阵,则需要遍历向量Mi·中所有元素。
总的来说,两种描述方法各有优劣,这取决于图的具体结构。在本书章节中我们讨论的算法大都基于第二种描述方法,一方面考虑到算法描述的统一性;另一方面从算法效率上考虑,算法通常需要频繁地访问顶点所有相邻顶点。
.2 图的接口设计
基于上述图的两种描述方法,我们将首先讨论图的抽象Graph类和边Edge类的抽象类。
以下是图的抽象数据类型设计,我们约定图中各顶点都有标号,从0开始,到n-1。在迭代访问某顶点的全部相邻顶点时,按照相邻顶点标号由小到大的顺序进行访问。

/**
*
* 图的接口定义,
* 包括对图以及边的各种操作
* Graph.java
*/
public interface Graph {
// 获取顶点个数
public int get_nv();
// 获取边的条数
public int get_ne();
// 获取顶点v的第一条边
public Edge firstEdge( int v);
// 获取边w的下一条同源点的边
public Edge nextEdge(Edge w);
// 判断w是否是图上的边,是返回true
public boolean isEdge(Edge w);
// 判断顶点i和j之间是否是边
public boolean isEdge( int i, int j);
// 返回边w的源点
public int edge_v1(Edge w);
// 返回边w的终点
public int edge_v2(Edge w);
// 设定顶点i,j之间边的权重
public void setEdgeWt( int i, int j, int wt);
// 设定边w的权重
public void setEdgeWt(Edge w, int wt);
// 获取顶点i,j之间边上的权重
public int getEdgeWt( int i, int j);
// 获取边w上权重
public int getEdgeWt(Edge w);
// 删除顶点i,j之间的边
public void delEdge( int i, int j);
// 删除边w
public void delEdge(Edge w);
// 设定顶点v的标记
public void setMark( int v, int val);
// 读取顶点v的标记
public int getMark( int v);
}
Graph接口具有返回顶点数和边数的函数(get_nv和get_ne),顶点树和边数树图结构最基本的成员变量。
函数firstEdge返回与形参顶点关联的第一条边。nextEdge函数的形参为边,返回与形参边具有相同起点的下一条边,其顺序由各节点的序号大小决定。
函数isEdge函数判断边在图中是否存在。
利用firstEdge,nextEdge和isEdge这三个函数可以遍历与对某个顶点v相邻的所有顶点。这可以通过简单的for循环实现。
函数edge_v1和edge_v2分别返回某条边的源点和终点。
对于带权图,接口中设计了访问和设置权值的函数,分别为getEdgeWt和setEdgeWt。这两个函数都有两种形式,第一种返回或者设定给定边的权,其形参为边;第二中返回或设定给定起点和终点的边的权,其形参为边的源点和终点如果这样的边不存在则返回Integer.MAX_VALUE。setEdgeWt函数在执行时,如果待重设的边存在则直接修改边的权值,否则,创建这条边并将这条边的权值设定为待修改的权值。
顶点删除函数也包括两种实现,一种用边的两个相邻顶点表示待删除的边,另一种直接指定待删除的边。
最后两个函数,setMark和getMark分别对顶点进行着色和获取顶点的着色。这在图的遍历算法等算法中将起重要作用。
在图的ADT中Edge表示的是边的数据结构,边的信息应该是完全包含在图的信息中。其主要涉及边的两个顶点,而对于带权图,其权值不作为边的信息,而是包含在图结构中,即getEdgeWt(Edge )接口函数。
边的接口设计如下:
/**
* 图数据结构中边的接口定义
* Edge.java
*/
public interface Edge {
// 获取边的源点
public int get_v1();
// 获取边的终点
public int get_v2();
}
以上图和边的ADT设计不涉及具体的实现,下面我们将讨论基于相邻矩阵法和连接表法对上述两个接口的具体实现。在具体实现时我们还将引入一些辅助函数。
.3 图的实现
.3.1 相邻矩阵描述法
基于相邻矩阵描述法的图实现中边的实现如下:
/**
* @author Wei LU
*
* 图结构用连接矩阵法表示时边的描述,
* EdgeMMtrx.java
*/
public class EdgeMtrx implements Edge{
// 私有成员变量,边的两个顶点
private int vert1, vert2;
/**
* 构造函数
* @param _v1 边的源点
* @param _v2 边的终点
*/
public EdgeMtrx( int _v1, int _v2){
vert1 = _v1;
vert2 = _v2;
}
// 获取边的源点
public int get_v1() {
return vert1;
}
// 获取边的终点
public int get_v2() {
return vert2;
}
}
基于相邻矩阵法实现的图数据结构如下:
/**
* @author Wei LU
*
* 图的连接矩阵法,
* GraphMtrx.java
*/
public class GraphMtrx implements Graph{
// 私有成员变量
// 连接矩阵,二维数组
private int[][] mtrx;
// 边的个数
private int numEdge;
// 顶点的个数
private int numVertex;
// 标记矩阵
private int[] mark;
/**
* 构造函数,根据顶点个数初始化各个成员变量
* @param n 顶点个数
*/
public GraphMtrx( int n){
mtrx = new int[n][n];
for( int i = 0; i < n; i++)
for( int j = 0; j < n; j++)
mtrx[i][j] = Integer.MAX_VALUE;
numVertex = n;
numEdge = 0;
mark = new int[n];
}
// 获取图中顶点个数
public int get_nv() {
return numVertex;
}
// 获取图中边个数
public int get_ne() {
return numEdge;
}
/**
* 获取给定顶点为源点的第一条边(其终点的标号最小);
* @param v 给定顶点
*/
public Edge firstEdge( int v) {
// 遍历每个顶点,返回与v相连的第一条边
for( int i = 0; i < numVertex; i++)
if(isEdge(v, i))
return new EdgeMtrx(v, i);
return null;
}
/**
* 获取与给定边有相同源点的下一条边,其终点的标号大于
* 给定边的终点标号,但又是最小的;
* @param w 给定的边
* @return 与给定边同源点的下一条边
*/
public Edge nextEdge(Edge w) {
if(w == null) return null;
/* 从顶点标号为w的终点标号+1开始寻找第一个与w源点
* 相连的边,并返回这条边 */
for( int i = w.get_v2() + 1; i < numEdge; i++)
if(isEdge(w.get_v1(), i))
return new EdgeMtrx(w.get_v1(), i);
return null;
}
/**
* 判断给定边是否为图中一条边;
* @param w 给定的边
* @return 如果是一条边,返回true;否则返回false
*/
public boolean isEdge(Edge w) {
if(w == null)
return false;
// 判断矩阵中对应元素是否为无穷大
else{
int v1 = w.get_v1(), v2 = w.get_v2();
return mtrx[v1][v2] != Integer.MAX_VALUE;
}
}
/**
* 判断给定顶点对对应的边是否为图中一条边;
* @param i, j 顶点对对应的标号;
* @return 如果是一条边则返回true;否则false
*/
public boolean isEdge( int i, int j) {
if(i < 0 || j < 0)
return false;
// 判断矩阵中对应元素是否为无穷大
return mtrx[i][j] != Integer.MAX_VALUE;
}
/**
* 获取给定边的源点;
* @param w 给定边
* @return 返回w的源点
*/
public int edge_v1(Edge w) {
if(w == null) return -1;
return w.get_v1();
}
/**
* 获取给定边的终点
* @param w 给定边
* @return 返回w的终点
*/
public int edge_v2(Edge w) {
if(w == null) return -1;
return w.get_v2();
}
/**
* 设定以顶点i和顶点j组成的边的权重,如果这条边在图中
* 并不存在,则创建这条边,并且其权值为wt
* @param i,j 两个顶点的标号
* @param wt 待设定的权重大小
*/
public void setEdgeWt( int i, int j, int wt) {
if(i < 0 || j < 0) return;
// 如果边不存在则更新节点个数
if(!isEdge(i, j))
numEdge++;
// 重设边的权重
mtrx[i][j] = wt;
}
/**
* 设置边w的权值,本函数调用setEdgeWt(int, int, int)
* @param w 待重设的边
* @param wt 待重设的权值
*/
public void setEdgeWt(Edge w, int wt) {
// 调用上一函数
if(w == null) return;
setEdgeWt(w.get_v1(), w.get_v2(), wt);
}
/**
* 获取顶点i和顶点j组成的边的权重
* @param i, j 待获取权重的边的源点、终点
* @return 顶点i和顶点j组成的边的权重
*/
public int getEdgeWt( int i, int j) {
// 未连接或入参不合法,返回无穷大
if(i < 0 || j < 0 ||
!isEdge(i, j))
return Integer.MAX_VALUE;
return mtrx[i][j];
}
/**
* 获取给定边的权重,调用函数getEdgeWt(i, j)
* @param w 给定的边
* @return w的权重
*/
public int getEdgeWt(Edge w) {
// 调用上一函数
if(w == null)
return Integer.MAX_VALUE;
return getEdgeWt(w.get_v1(), w.get_v2());
}
/**
* 删除顶点i和顶点j组成的边
*/
public void delEdge( int i, int j) {
if(i < 0 || j < 0) return;
// 如果边存在则将矩阵对应位置取值为无穷大
if(isEdge(i, j)){
mtrx[i][j] = Integer.MAX_VALUE;
numEdge--;
}
}
/**
* 删除边,调用delEdge(int, int)
*/
public void delEdge(Edge w) {
// 调用上一函数
if(w == null) return;
delEdge(w.get_v1(), w.get_v2());
}
/**
* 重设顶点的标记值,这在图的遍历算法中将起作用
*/
public void setMark( int v, int val) {
if(v < 0) return;
mark[v] = val;
}
/**
* 获取顶点v的标记值
*/
public int getMark( int v) {
// 正确的标记的取值为0,1,...
if(v < 0) return -1;
return mark[v];
}
/**
* 显示相邻矩阵
*/
public void showMtrx(){
for( int i = 0; i < get_nv(); i++){
for( int j = 0; j < get_nv(); j++){
if(isEdge(i, j))
System.out.print(mtrx[i][j] + "\t");
else {
System.out.print("oo" + "\t");
}
}
System.out.println();
}
}
}
相邻矩阵实现方式中包含了相邻矩阵mtrx,这是一个二维数组。其中mtrx[i][j]的大小即为边(i, j)的权值,如果该权值为无穷大(Integer.MAX_VALUE)则表示这条边不存在。
下面将重点分析其中几个重要的函数。对于给定的某个顶点标号v,firstEdge函数返回以v为源点的第一条边。在这里,以v为起点的所有边之间的先后顺序由各条边的终点的标号决定。例如,图(a)中,以顶点0为源点的边有两条,(0, 1), (0, 4),由于1小于4,所以(0, 1)是第一条边,而(0, 4)是第二条边。在具体实现时,从(v, 0)开始顺序遍历矩阵的第v行,直至第一次遇到与v相连的顶点或到达行尾为止。如果直到行尾都未找到相邻顶点,则返回空指针。
nextEdge函数返回与给定边w有相同源点的下一条边。在具体实现时,从终点为w的终点+1的顶点开始遍历矩阵的 第v行,直至第一次遇到与v相连的顶点或到达行尾为止。如果直到行尾都未找到相邻顶点,则返回空指针。
上述两个函数中都直接调用了函数isEdge来判断一条边的存在性。isEdge函数在实现时,判断给定边源点v1、终点v2在连接矩阵中的数值大小。如果其值不为无穷大,则返回ture,否则返回false。函数有两种形式,第一种的形参为边的两个顶点,第二种的形参直接为给定的边。
获取、修改给定边的权值的函数为getEdgeWt和setEdgeWt,通过获取和修改相邻矩阵中对应位置的数值便可完成这些功能。在删除图中给定边时,直接将矩阵中对应位置的数值重置为Integer.MAX_VALUE即可。
下面通过示例程序来测试基于相邻矩阵法。首先我们需要实现图的构造方法,在这里我们从文件中读取描述图结构的数据项,每条数据项对应图中的一条边。根据每条数据项创建边,并将边添加到图数据结构中。
以下是与图(a)中图结构对应的文件的内容:
8
0,1,1
0,4,1
1,0,1
1,5,1
2,3,1
2,5,1
2,6,1
5,6,1
……
7,6,1
其中第一行的数值8表示待创建的图一共有8个顶点,其标号为0,1, …, 7。从第二行开始每行由三个数字构成,数字之间以逗号隔开,形式为“u,v,w”。其中u表示源点,v表示终点,w表示权值。文件数据逐行读取,对第一行直接将读取的字符串转为整数;其余每一行字符串根据逗号进行划分,利用划分得到三个整数值创建边,并将边添加到图中。具体函数如下:
* 从文件中读取图结构数据并构造图数据结构
* @param filename 文件名
* @return 基于相邻矩阵法的图结构
*/
public static
GraphMtrx BulidGraphMtrxFromFile(String filename){
// 顶点个数
int N = -1;
// 待返回的图结构
GraphMtrx G = null;
// 文件流
FileInputStream fstream = null;
// 数据流
DataInputStream in = null;
try {
// 读取流文件
fstream = new FileInputStream(filename);
// 将文件流转为数据输入流
in = new DataInputStream(fstream);
// 首先读取第一行,其值为图顶点个数
if(in.available() != 0) {
String line = in.readLine();
N = Integer.parseInt(line);
}
// 构造图结构
G = new GraphMtrx(N);
// 逐行读取文件中数据,并根据每行数据向图中添加边
while (in.available() != 0) {
// 读取一行字符
String line = in.readLine();
// 将字符分割,分割符为逗号
String e[] = line.split(",");
// 分割得到的字符数组为 {起点,终点,权值}
int i = Integer.parseInt(e[0]);
int j = Integer.parseInt(e[1]);
int w = Integer.parseInt(e[2]);
// 向图中添加边
G.setEdgeWt(i, j, w);
}
in.close();
} catch (Exception e) {
e.printStackTrace();
}
return G;
}
除了BulidGraphMtrxFromFile函数之外,还有不少其它与图相关的辅助函数,我们将这些函数归为一类Utilities,其中的辅助函数都为静态函数。
下面通过BulidGraphMtrxFromFile函数创建相邻矩阵法描述的图对象:
/**
* @author Wei LU
* 相邻矩阵法描述图结构,示例程序
*/
public class GraphMtrxExample {
public static void main(String args[]){
// 构造连接表实现的图
GraphMtrx GM = Utilities.BulidGraphMtrxFromFile("Graph\\graph1.txt");
int v = GM.get_nv();
int e = GM.get_ne();
// 首先打印这个图
for( int i = 0; i < v; i++){
for( int j = 0; j < v; j++){
if(GM.isEdge(i, j)){
String str = i + "-" + j + " " + GM.getEdgeWt(i, j) + ",";
System.out.print(str + "\t");
}
}
System.out.println();
}
// 显示相邻矩阵
GM.showMtrx();
}
}
示例程序首先通过输入文件“graph1.txt”创建图,然后遍历打印图的各条边,并显示其相邻矩阵中各元素。程序结果如下:
0-1 1, 0-4 1,
1-0 1, 1-5 1,
2-3 1, 2-5 1, 2-6 1,
3-2 1, 3-6 1, 3-7 1,
4-0 1,
5-1 1, 5-2 1, 5-6 1,
6-2 1, 6-3 1, 6-5 1, 6-7 1,
7-3 1, 7-6 1,
相邻矩阵:
oo 1 oo oo 1 oo oo oo
1 oo oo oo oo 1 oo oo
oo oo oo 1 oo 1 1 oo
oo oo 1 oo oo oo 1 1
1 oo oo oo oo oo oo oo
oo 1 1 oo oo oo 1 oo
oo oo 1 1 oo 1 oo 1
oo oo oo 1 oo oo 1 oo
相邻矩阵描述法比较容易理解,也很容易实现,适用于小规模问题求解。对大规模问题,尤其是可以抽象成稀疏图的问题,使用连接表法将更有效。
.3.2 连接表法
连接表是一个以链表为元素的数组。这个数组包含|V|个链表,其中第i个链表中每个节点存储的是与顶点vi相邻的顶点的标号以及对应边的权值。
链表采用前面章节中设计的单链表,节点元素项为GraphLLinkNode,如下:
/**
* 用连接表法描述图结构,每个顶点对应一个
* 链表,链表节点包含结束顶点和对应的权值
* GraphLLinkNode.java
*/
public class GraphLLinkNode implements Comparable{
// 私有成员,终点和权重
private int des, weight;
// 构造函数
public GraphLLinkNode( int _des, int _wt){
des = _des;
weight = _wt;
}
// 设置终点标号
public void set_des( int _d){
des = _d;
}
// 设置权值
public void set_wt( int _wt){
weight = _wt;
}
// 获取终点标号
public int get_des(){
return des;
}
// 获取权值
public int get_wt(){
return weight;
}
// 权值的比较
public int compareTo(Object arg0) {
int _wt = ((GraphLLinkNode)(arg0)).get_wt();
if(weight > _wt)
return 1;
else if(weight < _wt)
return -1;
else return 0;
}
}
通过第章中对链表的讨论我们知道,在链表中定位给定元素项的操作需要从链表头部开始对链表进行遍历。如果在连接表图中采用EdgeMtrx来描述边,对某些操作将会导致比较高的复杂度。例如,返回给定边(i, j)的下一条边时,首先需要在第i个链表中遍历,找到边(i, j)对应的链表节点,然后返回链表当前位置的下一个节点对应的边,这种遍历查找操作的复杂度为O(|V|)。
连接表中边的设计可以考虑在边的数据结构中添加一个链表节点指针,该指针指向的节点即为这条边中的信息,如图,这样的设计可以快速定位给定边在链表中的位置。
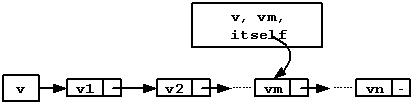
图 连接表中边数据结构
上图中边(v, vm),其中链表节点中包含了重点vm和这条边的权值wtm。这条边的数据结构中包含了原点v,终点vm以及链表节点的指针itself。在下面的设计中可以看出在连接表中使用这样的方式描述边的优势。连接表法中边的实现如下:
import List.SingleNode;
/**
* @author Wei Lu
*
* 为实现连接表描述法设计的边数据结构
* EdgeLnk.java
*/
public class EdgeLnk implements Edge{
// 私有成员变量
// 边的源顶点和终节点
private int vert1, vert2;
// 边信息在源点对应链表中的节点指针
private SingleNode itself;
/**
* 构造函数
* @param _v1, _v2 边的源点和终点
* @param _it 边在_v1对应链表中的节点指针
*/
public EdgeLnk( int _v1, int _v2,
SingleNode _it){
vert1 = _v1;
vert2 = _v2;
itself = _it;
}
// 获取源点
public int get_v1() {
return vert1;
}
// 获取终点
public int get_v2() {
return vert2;
}
// 获取边信息在源点对应链表中的节点指针
public SingleNode get_lk(){
return itself;
}
}
在讨论连接表法实现图数据结构之前,首先讨论图中链表的数据结构,这里我们对单链表进行扩展,添加对链表当前位置(当前节点指针)的获取和重置:
import List.SingleLink2;
import List.SingleNode;
/**
* 继承单链表的图节点链表
* GraphNodeLList.java
*/
public class GraphNodeLList extends SingleLink2{
public SingleNode currNode(){
return curr;
}
public void setCurr(SingleNode nd){
curr = nd;
}
}
连接表法实现图数据结构如下:
import Element.ElemItem;
/**
* 连接表实现图算法,
* GraphLnk.java
*/
public class GraphLnk implements Graph{
// 私有成员变量
// 顶点链表数组,数组的每个元素对应于
// 与顶点相连的所有顶点形成的链表
private GraphNodeLList[] vertexList;
// 边的个数和顶点的个数
private int num_Edge, num_Vertex;
// 节点标记数组
private int[] mark;
/**
* 构造函数,创建给定顶点个数的链表数组;
* 链表数组为继承了单向链表的图顶点链表类。
* @param n 顶点个数
*/
public GraphLnk( int n){
vertexList = new GraphNodeLList[n];
for( int i = 0; i < n; i++){
vertexList[i] = new GraphNodeLList();
}
num_Edge = 0;
num_Vertex = n;
mark = new int[n];
}
// 获取图中顶点个数
public int get_nv() {
return num_Vertex;
}
// 获取图中边的个数
public int get_ne() {
return num_Edge;
}
/**
* 获取给定顶点为源点的第一条边(其终点的标号最小);
* @param v 给定顶点
*/
public Edge firstEdge( int v) {
// 第v个链表当前指针移至头部
vertexList[v].goFirst();
// 如果链表中无元素项则直接返回空
if(vertexList[v].getCurrVal() == null)
return null;
// 否则返回由链表当前元素项对应的终点及权重所形成的边
return new EdgeLnk(v,
((GraphLLinkNode)(vertexList[v].
getCurrVal().elem)).get_des(),
vertexList[v].currNode());
}
/**
* 获取与给定边有相同源点的下一条边,其终点的标号大于
* 给定边的终点标号,但又是最小的;
* @param w 给定的边
* @return 与给定边同源点的下一条边
*/
public Edge nextEdge(Edge w) {
// 给定边为空,返回空
if(w == null)
return null;
// 获取w的源点
int v = w.get_v1();
/* 将v对应的链表的当前节点设定为w中保存的w所对应的
* 链表节点的指针 */
vertexList[v].setCurr(((EdgeLnk)w).get_lk());
// 将链表指针后移,指向下一条边
vertexList[v].next();
// 如果链表当前节点为空,则返回空
if(vertexList[v].getCurrVal() == null)
return null;
/* 否则返回顶点v为源点、链表当前顶点对应的边的终点为终点、
* 链表当前节点的指针 为成员的边 */
return new EdgeLnk(v,
((GraphLLinkNode)(vertexList[v].
getCurrVal().getElem())).get_des(),
vertexList[v].currNode());
}
/**
* 判断给定边是否为图中一条边;
* @param w 给定的边
* @return 如果是一条边,返回true;否则返回false
*/
public boolean isEdge(Edge w) {
// w为空,则返回false
if(w == null)
return false;
// 获取w的源点
int v = w.get_v1();
/* 将v对应的链表的当前节点设定为w中保存的w所对应的
* 链表节点的指针 */
vertexList[v].setCurr(((EdgeLnk)w).get_lk());
/* 调用链表中判断节点是否在链表中的函数,如果链表当前节点
* 不在链表中,则说明w不在图中,返回false */
if(!vertexList[v].inList())
return false;
/* 否则进一步判断,v对应链表当前节点指向的边的终点
* 与w的终点是否相同,相同则返回true,否则false */
return ((GraphLLinkNode)(vertexList[v].
getCurrVal().elem)).get_des() == w.get_v2();
}
/**
* 判断给定顶点对对应的边是否为图中一条边;
* @param i, j 顶点对对应的标号;
* @return 如果是一条边则返回true;否则false
*/
public boolean isEdge( int i, int j) {
/* 从i的第一条边开始进行迭代,直到边的终点的标号
* 不小于j或边为空为止 */
for(vertexList[i].goFirst();
vertexList[i].getCurrVal() != null &&
((GraphLLinkNode)(vertexList[i].getCurrVal().
elem)).get_des() < j;
vertexList[i].next());
// 此时如果边不为空并且终点标号等于j则返回true,否则false
return vertexList[i].getCurrVal() != null &&
((GraphLLinkNode)(vertexList[i].getCurrVal().
elem)).get_des() == j;
}
/**
* 获取给定边的源点;
* @param w 给定边
* @return 返回w的源点
*/
public int edge_v1(Edge w) {
// 如果w为空,则返回-1(无效标号)
if(w == null)
return -1;
// 否则返回w的源点
return w.get_v1();
}
/**
* 获取给定边的终点
* @param w 给定边
* @return 返回w的终点
*/
public int edge_v2(Edge w) {
// 如果w为空,则返回-1(无效标号)
if(w == null)
return -1;
// 否则返回w的终点
return w.get_v2();
}
/**
* 设定以顶点i和顶点j组成的边的权重,如果这条边在图中
* 并不存在,则创建这条边,并且其权值为wt
* @param i,j 两个顶点的标号
* @param wt 待设定的权重大小
*/
public void setEdgeWt( int i, int j, int wt) {
// 入参合法性判断
if(i < 0 || j < 0)
return;
// 创建终点为j、权值为wt的链表节点gln
GraphLLinkNode gln = new GraphLLinkNode(j, wt);
/* 如果顶点i、j对应的边在图中存在,则将链表当前节点重新赋值
* 为gln,在isEdge函数执行完后顶点i对应的链表的当前位置处
* 的顶点即位j */
if(isEdge(i, j))
vertexList[i].setCurrVal(
new ElemItem<GraphLLinkNode>(gln));
else{
// 否则直接将gln插入到顶点i对应的链表中,并更新顶点个数
vertexList[i].insert( new ElemItem<GraphLLinkNode>(gln));
num_Edge++;
}
}
/**
* 设置边w的权值,本函数调用setEdgeWt(int, int, int)
* @param w 待重设的边
* @param wt 待重设的权值
*/
public void setEdgeWt(Edge w, int wt) {
if(w != null)
setEdgeWt(w.get_v1(), w.get_v2(), wt);
}
/**
* 获取顶点i和顶点j组成的边的权重
* @param i, j 待获取权重的边的源点、终点
* @return 顶点i和顶点j组成的边的权重
*/
public int getEdgeWt( int i, int j) {
/* 判断边在图中是否存在,如果存在,函数执行完后
* 顶点I对应的链表的当前位置指向顶点j */
if(isEdge(i, j))
return ((GraphLLinkNode)(vertexList[i].
getCurrVal().getElem())).get_wt();
// 如果这条边不存在,返回无穷大
else return Integer.MAX_VALUE;
}
/**
* 获取给定边的权重,调用函数getEdgeWt(i, j)
* @param w 给定的边
* @return w的权重
*/
public int getEdgeWt(Edge w) {
if(w != null)
return getEdgeWt(w.get_v1(), w.get_v2());
else return Integer.MAX_VALUE;
}
/**
* 删除顶点i和顶点j组成的边
*/
public void delEdge( int i, int j) {
/* 如果边存在,函数执行完后顶点I对应的链表的当前位置
* 指向顶点j,将当前节点删除,同时更新边的个数 */
if(isEdge(i, j)){
vertexList[i].remove();
num_Edge--;
}
}
/**
* 删除边,调用delEdge(int, int)
*/
public void delEdge(Edge w) {
if(w != null)
delEdge(w.get_v1(), w.get_v2());
}
/**
* 重设顶点的标记值,这在图的遍历算法中将起作用
*/
public void setMark( int v, int val) {
if(v >= 0 && v < num_Vertex)
mark[v] = val;
}
/**
* 获取顶点v的标记值
*/
public int getMark( int v) {
if(v >= 0 && v < num_Vertex)
return mark[v];
else
return -1;
}
}
在连接表类的构造函数中,根据节点的个数创建链表数组,每个链表都为空。函数firstEdge返回给定顶点v的第一条边,即链表数组中第v个链表的第一个节点N1对应的边。返回的边中包含源点u,N1中的终点和N1的地址。
函数nextEdge返回给定边w的下一条边w2。在实现时,首先获取w的源点v,并将其对应的链表的当前位置设置为w中包含的节点指针,则链表当前位置的节点中内容即为w。再将链表的当前指针指向下一个节点,如果该节点不为空,则返回该节点对应的边。
函数isEdge判断给定边的存在性。isEdge函数有两种形式,第一种的形参为边的两个顶点,第二种的形参直接为给定的边。这两种形式的实现方法大不相同。形参为边的两个顶点时,需要在源点对应的链表中进行遍历,由于链表中相邻顶点按照标号由小到大顺序排列,所以一旦发现遍历至终点标号不小于j就停止;而形参为给定边时,首先根据边中保存的节点指针在链表中定位到当前边对应的节点,然后在进行相关判断。从时间复杂度上来看,第一种形式的复杂度为O(|V|),第二种复杂度为O(1)。
以上介绍的三个函数通常用于迭代地访问给定的顶点所以相邻顶点,例如:
for(Edge e = G.firstEdge(); G.isEdge(e); e = G.nextEdge(e));
函数getEdgeWt和setEdgeWt分别用于获取和设置给定边的权值,以边的相邻顶点(i, j)作为参数的函数形式中,都调用了isEdge(i, j)函数,如果给定边存在,则函数执行完后第i个链表的当前位置将指向顶点j,然后直接在链表的当前位置进行元素项的返回或者重设;如果给定边不存在,此时链表当前位置处的顶点标号一定小于j,则直接在当前位置添加一条边,其终点为j,权值为给定权值,这样能保证与顶点i相邻的所有顶点的标号在链表中按由小到大的顺序排列。删除边的函数delEdge的实现过程与它们类似。
可以设计与相邻矩阵法类似的方法从文件各种获取图的边信息,并创建图。函数为Utilities. BulidGraphLnkFromFile(String filename),示例函数如下:
/**
* @author Wei LU
* 连接表法实现图数据结构的测试示例程序
*/
public class GraphLnkExample {
public static void main(String args[]){
// 构造连接表实现的图
GraphLnk GL =
Utilities.BulidGraphLnkFromFile("Graph\\graph1.txt");
int v = GL.get_nv();
int e = GL.get_ne();
// 首先打印这个图
System.out.println("图中各条边:");
for( int i = 0; i < v; i++){
for( int j = 0; j < v; j++){
if(GL.isEdge(i, j)){
String str = i + "-" + j + " " +
GL.getEdgeWt(i, j) + ",";
System.out.print(str + "\t");
}
}
System.out.println();
}
// 显示连接表中各个链表
System.out.println("连接表链表:");
for( int i = 0; i < v; i++){
GL.getVertexList(i).printList();
}
}
}
示例程序首先通过输入文件“graph1.txt”创建图,然后遍历打印图的各条边,并显示其连接表中各个链表。程序结果如下:
0-1 1, 0-4 1,
1-0 1, 1-5 1,
2-3 1, 2-5 1, 2-6 1,
3-2 1, 3-6 1, 3-7 1,
4-0 1,
5-1 1, 5-2 1, 5-6 1,
6-2 1, 6-3 1, 6-5 1, 6-7 1,
7-3 1, 7-6 1,
连接表链表:
1, 1), 4, 1).
0, 1), 5, 1).
3, 1), 5, 1), 6, 1).
2, 1), 6, 1), 7, 1).
0, 1).
1, 1), 2, 1), 6, 1).
2, 1), 3, 1), 5, 1), 7, 1).
3, 1), 6, 1).














 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









