






本文主要介绍Lucene的常用概念,并自定义一个分词器
1 环境介绍
系统:win10
lucene版本:7.3.0 https://lucene.apache.org/
jdk:1.8
2 lucene 简介
lucene是最受欢迎的java开源全文搜索引擎开发工具包,提供了完整的查询引擎和索引引擎,是Apache的子项目。在应用中为数据库中的数据提供全文检索实现
也可以开发独立的搜索引擎服务,系统。
架构图如下:
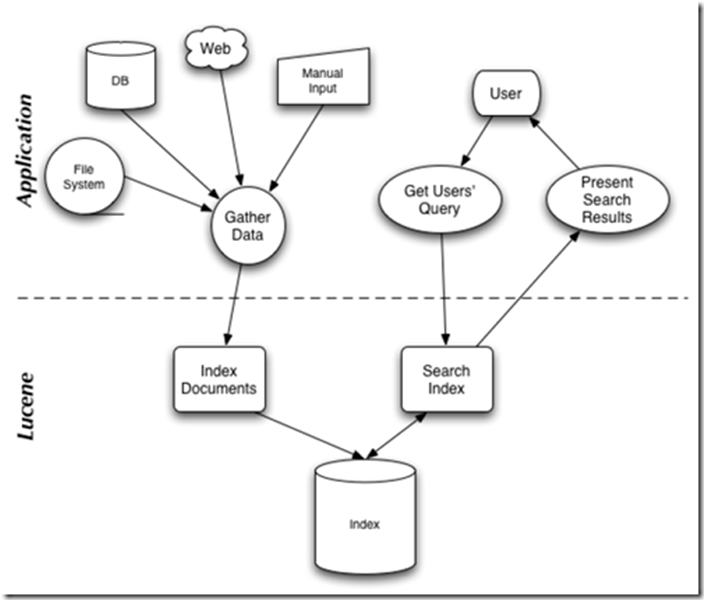
上层application层,左边 为lucene提供数据收集,右边为用户提供搜索的入口
下层lucene,为数据提供索引的存储,索引的查询等功能
3 分词器
分析器(org.apache.lucene.analysis.Analyzer),分词器组件的核心api ,用来构建真正的对文本进行分词处理的TokenStrem (分词处理器),在Analyzer 这个类中我们看到,有唯一的一个可以扩展的抽象方法

我们在扩展自己的analyzer的时候 要重载这个方法,改方法的参数fieldName表示字段名。不同的字段有不同的处理方式,根据字段名来区分。
TokenStreamComponents 是一个内部类,提供了两个构造方法
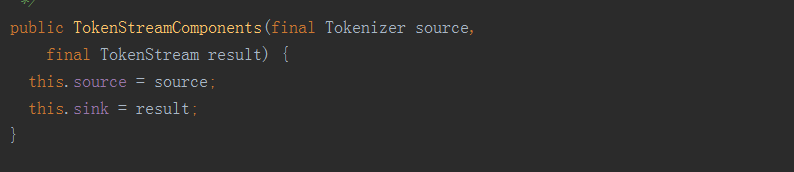

TokenStream
从上面的构造方法的参数中,我们可以看到,我们至少要提供一个Tokenizer 参数。那现在看看Tokenizer 和TokenStream 这两个类。TokenStream,负责对输入的文本进行分词和处理,分词分出的每一项叫token
实际上TokenStream 有两种类型的子类分别用于分词和处理 。 一类是 Tokenizer分词器,完成从输入的reader字符流中分出分项, 还有一类是 TokenFilter,分项过滤器,对分出的分项进行特性处理。
TokenFilter是采用的装饰器模式。如果我们需要对分词进行各种处理,我们只需要按照我们的处理顺序一层层包裹即可。
在TokenStrem中有个抽象方法

在我们实现自己的分词器的时候要实现这个方法,来告诉我们自己的分词规则和处理规则。返回值为false的时候表示分词结束。
AttributeSource
TokenStream 继承AttributeSource. 该方法用来存放Attribute 并且提供了对应的设置和取值方法。那Attribute是用来干什么的呢?
在我们用Tokenizer 和TokenStream 对分词进行了分项,并且对每个分项进行了了处理了之后,每个分项都会产生相应的信息,比如这个分项的文本是什么,位置是多少。这些都是要存储起来的,那这些信息就是
存储在Attribute中的,AttributeFactory是用来创建attribute的工厂方法。不需要我们去创建。
TokenStream的使用步骤:
1 从tokenStream获得你想要的分项属性对象(attribute)用来存放分项信息。
2 调用tokenStream的reset方法,进行重置,因为tokenStream是重复利用的。
3 循环调用tokenStream的increamentToken方法,一个个分项,知道返回false
4 在循环中取出你每个分项想要的属性
5 调用tokenStream的end方法,接受处理。
5 调用tokenStream的close方法,释放资源。
4 实现自己的分词器
4.1定义自己的分词属性
**
* 每个分词的属性
*/
public interface MyCharAttribute extends Attribute {
/**
* 赋值
* @param buffer 要被复制的数组
* @param length 复制的长度
*/
void setChars(char[] buffer, int length);
/**
* 获取分词数组
* @return
*/
char[] getChars();
/**
* 获取分词长度
* @return
*/
int getLength();
/**
* 获取分词的字符串
* @return
*/
String getString();
}
4.2 实现上面抽象方法
主要命名规则必须是 xxxImpl,lucence内部是以字符串拼接的形式去实现的
**
* 命名规则必须是 xxxImpl
*/
public class MyCharAttributeImpl extends AttributeImpl implements MyCharAttribute {
//单根分词的字符数组
private char[] chatTerm = new char[255];
//单根分词的数组长度
private int length = 0;
@Override
public void setChars(char[] buffer, int length) {
this.length = length;
if (length > 0) {
System.arraycopy(buffer, 0, chatTerm, 0, length);
}
}
@Override
public char[] getChars() {
return chatTerm;
}
@Override
public int getLength() {
return length;
}
@Override
public String getString() {
if (this.length > 0) {
return new String(this.chatTerm, 0, length);
}
return null;
}
@Override
public void clear() {
length = 0;
}
@Override
public void reflectWith(AttributeReflector attributeReflector) {
}
@Override
public void copyTo(AttributeImpl attribute) {
}
}
4.3 实现自己的分词器
/**
* 定义如何分词
*/
public class MyTokenizer extends Tokenizer {
//里面是通过工厂方法 得到实例
MyCharAttribute attribute = this.addAttribute(MyCharAttribute.class);
char[] buffer = new char[255];
int length = 0;
int c;
/**
* 判断是否有需要分词的项 每次读取一个单词
* 如果有 会把这个分出来的词 设置到MyCharAttribute中
*/
@Override
public boolean incrementToken() throws IOException {
// 清除所有的词项属性
clearAttributes();
length = 0;
while (true) {
//这个input 就是要解析的文本流
c = input.read();
//是否到末尾
if (c == -1) {
if (length > 0) {
// 复制到charAttr
attribute.setChars(buffer, length);
return true;
} else {
return false;
}
}
//是否是空格 英文单词之间通过空格区分
if (Character.isWhitespace(c)) {
if (length > 0) {
// 复制到charAttr
attribute.setChars(buffer, length);
return true;
}
}
buffer[length++] = (char) c;
}
}
}
4.4 定义分词处理器
**
* 分词处理器 这里是全部转小写
*/
public class MyTokenFilter extends TokenFilter {
protected MyTokenFilter(TokenStream input) {
super(input);
}
MyCharAttribute charAttr = this.addAttribute(MyCharAttribute.class);
@Override
public boolean incrementToken() throws IOException {
boolean res = input.incrementToken();
if (res){
char[] chars = charAttr.getChars();
int length = charAttr.getLength();
if (length > 0) {
for (int i = 0; i < length; i++) {
chars[i] = Character.toLowerCase(chars[i]);
}
}
}
return res;
}
}
4.5 使用自定义分词器
public class MyAnalyzer extends Analyzer{
@Override
protected TokenStreamComponents createComponents(String s) {
Tokenizer source = new MyTokenizer();
//拦截连1 转小写
TokenStream filter1 = new MyTokenFilter(source);
return new TokenStreamComponents(source,filter1);
}
public static void main(String[] args) {
String text = "An AttributeSource contains a list of different AttributeImpls, and methods to add and get them. ";
try (Analyzer ana = new MyAnalyzer(); TokenStream ts = ana.tokenStream("aa", text);) {
//得到属性对象 每个属性对象是通过工厂创建 单例
MyCharAttribute ca = ts.getAttribute(MyCharAttribute.class);
ts.reset();
while (ts.incrementToken()) {
System.out.print(ca.getString() + "|");
}
ts.end();
System.out.println();
} catch (IOException e) {
e.printStackTrace();
}
}
}
4.6 运行结果
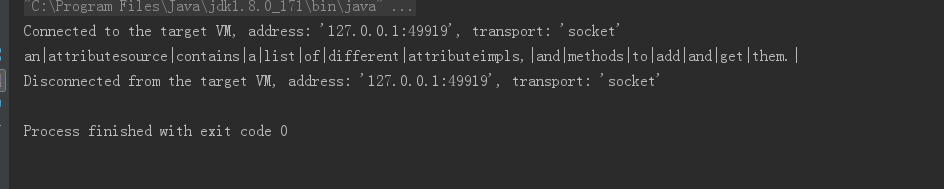















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









