






http协议
从输入URL到页面加载发生了什么?
1、在浏览器中输入URL
2、浏览器通过域名去找到对应的IP

执行步骤 浏览器缓存 –-> 系统缓存 –> 路由缓存(服务商) –> ISP DNS 缓存 –> 递归查找 详细DNS参考
查看本地DNS记录在谷歌中输入:chrome://net-internals/#dns
浏览器缓存 – 浏览器时不时的会缓存DNS记录. 有意思的是, OS并没有明确指明浏览器每条记录的生命周期是多长, 所以浏览器定期的缓存DNS记录(大概2-30分钟不等) chrome://net-internals/#dns.
系统缓存 – 如果缓存中没有,就去调用 gethostbyname 库函数(操作系统不同函数也不同)进行查询。函数在试图进行DNS解析之前首先检查域名是否在本地 Hosts 里,Hosts 的位置 不同的操作系统有所不同.
路由缓存 – 如果 gethostbyname 没有这个域名的缓存记录,也没有在 hosts 里找到,它将会向 DNS 服务器发送一条 DNS 查询请求。DNS 服务器是由网络通信栈提供的,通常是本地路由器或者 ISP 的缓存 DNS 服务器.
ISP DNS 缓存 – 查询本地网络提供商的DNS服务器.递归查找 如下示意图:
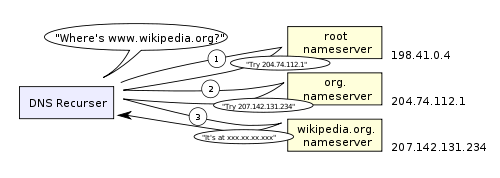
3、浏览器向服务器发送一个HTTP请求
由于facebook的页面是动态的,所以浏览器不会从缓存里读页面的内容,浏览器会向服务器发送HTTP请求。
请求:
GET http://facebook.com/ HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...]
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...]
Accept-Encoding: gzip, deflate
Connection: Keep-Alive
Host: facebook.com
Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]GET: 使用的是get方法,后面显示是请求的URL(HTTP协议中请求方法有Get和Post)
Accept: 自己接受什么样类型的响应
User-Agent: 表明自己是谁
Accept-Encoding: 自己接受什么样类型的响应(压缩类型)
Connection: 告诉服务器不要关闭TCP连接以便为后来请求所重用
Host: 域
Cookie: 是一些键值对,可以用来保持不同页面请求间的状态。因此cookie可以储存登录的用户的名称,服务端为用户分配的唯一密码以及一些用户设置信息等。cookie是存在客户端的,每次客户端向服务器发送请求都会带上cookie。
4、facebook服务器发出重定向响应,类似告诉浏览器你应该访问”http://www.facebook.com/“而不是”http://facebook.com/” 
5、浏览器跟随重定向,向”http://www.facebook.com/“发送请求
6、服务器开始处理请求,服务器开始处理请求并返回响应。
7、服务器返回HTML响应(200成功) 
Content-Encoding header告诉浏览器响应的body是被gzip给压缩过的,将body解压之后,原本的HTML就显示出来了。
除了解压方式之外,headers还会告诉浏览器如何缓存页面等
8、浏览器开始渲染HTML
9、浏览器发送请求去获取HTML中的一些内嵌对象
10、浏览器发送异步的AJAX请求
HTTP协议概述
HTTP是一种能够获取如HTML这样网络资源的协议。它是Web上数据交换的基础,是一种client-server协议,也就是说请求通常是由像浏览器这样的接受方发起的。一个完整的web文档是由不同的子文档重新组合而成的,像是文本、布局描述、图片、视频、脚本等等。
示意图: 
客户端和服务端通过交换各自的消息(与数据流正好相反)来进行交互。通常由像浏览器这样的客户端发出的消息叫做requests,那么被服务端回应的消息就叫做 responses。
HTTP协议的参与者
HTTP是一个client-server协议:请求通过一个实体被发出,实体也就是用户代理。
每一个发送到服务器的请求,都会被服务器处理并且返回一个消息,也就是response。在client与server之间,还有许许多多的被称为proxies的实体,他们的作用与表现各不相同,比如有些是网关,还有些是caches等。
示意图:

客户端: user-agent
严格意义来说,user-agent就是任何能够表现出用户一般行为的工具。但实际上,这个角色通常都是由浏览器来扮演。
简单来说user-agent就是来者何人,留下姓名的意思。
对于发起请求来说,浏览器总是作为发起一个请求的实体,而永远不是服务器(虽然一些机制已经能够模拟服务器发起请求的消息了)。
要渲染出一个网页,浏览器首先要发送第一个请求来获取这个页面的HTML文档,再解析它并根据文档中的资源信息发送其他的请求来获取脚本信息,或者CSS来进行页面布局渲染,还有一些其它的页面资源(如图片和视频等)。然后,它把这些资源结合到一起,展现出来一个完整的文档,也就是网页。打开一个网页后,浏览器还可以根据脚本内容来获取更多的资源来更新网页。
一个网页就是一个超文本文档,也就是说有一部分显示的文本可能是链接,启动它(通常是鼠标的点击)就可以获取一个新的网页。网页使得用户可以控制它的user-agent来导航Web。浏览器来负责翻译HTTP请求的命令,并翻译HTTP的返回消息让用户能明白返回消息的内容。浏览器发起请求–>服务器给出响应–>浏览器进行解析渲染
Web服务端
通信过程的另一端,就是一个Web Server来服务并提供客户端请求的文档。Server只是虚拟意义上:它可以是许多共同分担负载(负载平衡)的一组服务器组成的计算机群,也可以是一种复杂的软件,通过向其他计算机发起请求来获取部分或全部资源的软件。
Server不再只是一个单独的机器,它可以是在同一个机器上装载的许多服务之一。在HTTP/1.1和Host头部中,它们甚至可以共享同一个IP地址。
Proxies
在浏览器和服务器之间,有许多计算机和其他设备转发了HTTP的消息。因为Web栈层次结构的原因,它们大多数都出现在传输层、网络层和物理层上,对于HTTP的应用层来说就是透明的(虽然它们可能会对应用层的性能有重要影响)。而还有一部分表现在应用层上的,就叫做proxies了。Proxies既可以表现得透明,又可以不透明(看请求是否通过它们),主要表现在这几个功能上:
缓存(可以是公开的或是私有的,像浏览器的缓存)
过滤(像反病毒扫描,家长监护)
负载均衡,让多个服务器服务不同的请求
对不同资源的权限控制
登陆,允许存储历史信息HTTP 的基本性质
HTTP 是简单的
HTTP 是可扩展的
HTTP 是无状态,有会话的(而HTTP的核心是无状态的,cookies的使用可以创建有状态的会话。)
HTTP 和连接(一个连接是由传输层来控制的,基本不属于HTTP的范围内。然而HTTP并不需要下面传输层的协议是面向连接的,它只需要它是可靠的,就是说不能丢失消息(至少没有错误)。在因特网两个最常用的传输层协议中,TCP是可靠的,而UDP不是。因此,HTTP依赖于TCP进行消息传递)HTTP 能控制什么
缓存(由服务端能告诉代理和客户端什么需要被缓存,缓存多久,而客户端能够命令中间缓存代理来忽略存储的文档。)
开放同源限制(HTTP可以通过修改头部来开放这样的限制,因此web文档可以是由不同域下的信息拼接成的(在某些情况下,这样做还有安全因素考虑在里面)。)
认证(一些页面能够被保护起来,仅让特定的用户进行访问。)
代理(服务端和客户端通常都处在内部网上,彼此的真实地址都是不可见隐藏的。HTTP请求就要通过代理穿过网络障碍。)
会话(Cookies用一个服务端的状态连接起了每一个请求。这就创建了会话)
HTTP 流
当客户端想要和服务端进行信息交互时(服务端是指作为最终的服务器,或者是作为中间代理),过程表现为下面的几步:
打开一个TCP连接(或者重用之前的一个)
发送一个HTTP报文
读取服务端返回的报文
关闭连接或者为以后的请求重用连接。HTTP 报文
有两种HTTP报文的类型,请求与响应,每种都有其特定的格式。
请求
示意图: 
请求由下面的元素组成:
一个HTTP的method,经常是由一个动词像GET, POST 或者一个名词像OPTIONS,HEAD来定义客户端的动作行为的。通常客户端的操作都是获取资源(用GET方法)或者发送一个HTML form表单的值(用POST方法),虽然在一些情况下也会有其他的操作。
要获取的资源的路径,通常是上下文中就很明显的元素资源的URL,它没有protocol (http://),domain(developer.mozilla.org),或是TCP的port(HTTP是80端口)。
HTTP协议的版本号。
为服务端表达其他信息的可选择性的headers。
对于一些像POST这样的方法,报文的body就包含了发送的资源,这个body与回应报文的body类似。响应
示意图: 
响应报文包含了下面的元素
HTTP的版本号。
一个状态码(status code),来告知对应的请求发送成功或失败,以及失败的原因。
一个状态信息,这个信息是非权威的状态码描述信息,也就是说可以由服务端自行设定的。
HTTP headers,与请求的很像。
可选的,但是比在请求报文中更加常见地包含获取资源的body。总结
HTTP是很简单可扩展的一种协议。结合了轻松添加头部信息能力的Client-server结构使得HTTP可以和Web的功能扩充一同发展。
即使HTTP/2为了提高性能把HTTP报文嵌到帧中这一举措增加了复杂度,但是从Web应用的角度来看,报文的基本结构是没有变化的,从HTTP/1.0发布起就是相同的。会话流依旧很简单,用一个简单的 HTTP message monitor就可以查看它和debug。
实战: 使用chrome发者工具
chrome打开itest.info
windows按f12打开chrome开发者工具(mac command+option+i),并选择Network标签
刷新页面
找到itest.info这个请求,并查看结果
结果
General
Request URL:http://www.itest.info/
Request Method:GET
Status Code:200 OK
Remote Address:119.29.203.242:80
Referrer Policy:no-referrer-when-downgradeResponse Headers
Cache-Control:max-age=0, private, must-revalidate
Connection:keep-alive
Content-Encoding:gzip
Content-Type:text/html; charset=utf-8
Date:Sun, 18 Feb 2018 12:25:50 GMT
ETag:W/"cffea4bad3fa3910cb02d02294ff50fd"
Server:nginx/1.10.3 (Ubuntu)
Set-Cookie:_itest5_session=T004czBTMjJSenJQdHhlT3ExK1YreHA4dnh4QVlrUVMrQ1dtOGdMRlZDK0FNaHZaM0dsM012eVJMcUxkV21wU0xhR2JQTWVIcCtwdHZqTjhuK0UwTjFkUnpRV0tzSkZBTTNYQ0ZUNDZmTll0Z2JvSHhYTEhhTVpERS83ZzZiTHFxczZnR0s2UCt6MURzcGtKVHpoU0NRPT0tLWRmRWZFaTZxUWFPdkZLUW9UYUhTeHc9PQ%3D%3D--dfb838c81bb8f70a1ce3a46052ce65f2e261303d; path=/; HttpOnly
Transfer-Encoding:chunked
Vary:Accept-Encoding
X-Content-Type-Options:nosniff
X-Frame-Options:SAMEORIGIN
X-Request-Id:170873e5-69b2-43b3-943f-1ce304eb8bd4
X-Runtime:0.011807
X-XSS-Protection:1; mode=blockResquest Headers
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8
Cache-Control:max-age=0
Connection:keep-alive
Cookie:_itest5_session=Uy9kMVBaWHhzQ241dnVHclFENEwwbUdUVjJwa0JpQWNkN0ZoWEFIQzBjb1ZzZzNpdjFFYWFMZUJKVGliZ2JuaTFyaXFReG1UZURFMFJZOG1TczAzQ0xTWThvZkhBdXhkWFhsZFZIbEJvV2dqVW9LM2NQTFBUZjYwdUdOb293clBYVjB6NjF5TGkzMVBTZ0hSUWFYTElBPT0tLVpORmJ5VTZtVGRQSDgvVVlKSm5EMXc9PQ%3D%3D--6c6125c340dd629da4bf24cf0becac3e4db07aa0; Hm_lvt_906c6961a45234ebc29e93442b414707=1518572575,1518578300,1518675966,1518956108; Hm_lpvt_906c6961a45234ebc29e93442b414707=1518956178
Host:www.itest.info
If-None-Match:W/"b09aa665df826ef2ded50aa4a76dc712"
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36实战yslow前端性能测试
1、Chrome点击链接添加yslow插件如下图: 
2、运行yslow插件 
3、点击run test 
5条结果低于A
有17个静态组件不在CDN上
有3个静态组件,没有一个很遥远的过期日期。
有一个纯文本组件应该被压缩
有15个组件不是无cookie的
有5张图片被缩小了yslow插件在firefox中不支持36以上版本
加入书签方法报错
HTTP缓存
缓存是指存储指定资源的一份拷贝,并在下次请求该资源时提供该拷贝的技术。当 web 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的拷贝,而不会去源服务器重新下载。这样带来的好处有:缓解服务器端压力,提升性能(获取资源的耗时更短了)。对于网站来说,缓存是达到高性能的重要组成部分。缓存需要合理配置,因为并不是所有资源都是永久不变的:重要的是对一个资源的缓存应截止到其下一次发生改变(即不能缓存过期的资源)。
示意图:

HTTP 缓存不是必须的,但重用缓存的资源通常是必要的。然而常见的 HTTP 缓存只能存储 GET 响应,对于其他类型的响应则无能为力。缓存的关键主要包括request method和目标URI(一般只有GET请求才会被缓存)。
完全不支持缓存:缓存中不得存储任何关于客户端请求和服务端响应的内容,每次由客户端发起的请求都会下载完整的响应内容
不缓存内容:在释放缓存内容前像服务端源地址发送请求以验证缓存是否有效
公共缓存public:响应可以被任何请求来源缓存。针对需要进行http身份验证的页面或者一些不能被顺利缓存的响应码,通过定义public以支持缓存。
私有缓存private:响应的内容只能被唯一的用户缓存,不可以被共享缓存存储。隐私模式下的浏览器会通过这种方式存储缓存。
缓存过期:判断缓存是否过期是一个最常使用的标志是max-age.,它是距离请求发起的时间的秒数,针对一些不会发生改变的文件,可以手动设置一定的时长保证缓存有效
缓存验证:must-revalidate:在使用一些老的资源前强制验证状态判断其是否过期
缓存有效性:定期移除一部分缓存文件,叫做缓存抛弃.
缓存验证:缓存的响应头信息里含有"cache-control:must-revalidate",则在浏览的过程中会触发缓存验证HTTP请求(request)
点击了解更多
HTTP消息是服务器和客户端之间交换数据的方式。有两种类型的消息︰
请求--由客户端发送用来触发一个服务器上的动作;
响应--来自服务器的应答。HTTP消息由采用ASCII编码的多行文本构成。在HTTP/1.1及早期版本中,这些消息通过连接公开地发送。在HTTP/2中,为了优化和性能方面的改进,曾经可人工阅读的消息被分到多个HTTP帧中。
Web 开发人员或网站管理员,很少自己手工创建这些原始的HTTP消息︰ 由软件、浏览器、 代理或 服务器完成。他们通过配置文件(用于代理服务器或服务器),API (用于浏览器)或其他接口提供HTTP消息。
HTTP请求是由客户端发出的消息,用来使服务器执行动作。起始行 (start-line) 包含三个元素:
一个 HTTP 方法,一个动词 (像 GET, PUT 或者 POST) 或者一个名词 (像 HEAD 或者 OPTIONS), 描述要执行的动作. 例如, GET 表示要获取资源,POST 表示向服务器推送数据 (创建或修改资源, 或者产生要返回的临时文件)。
请求目标 (request target),通常是一个 URL,或者是协议、端口和域名的绝对路径,通常以请求的环境为特征。请求的格式因不同的 HTTP 方法而异。
HTTP 版本 (HTTP version),定义了剩余报文的结构,作为对期望的响应版本的指示符Headers
有许多请求头可用,它们可以分为几组:
General headers,例如 Via,适用于整个报文。
Request headers,例如 User-Agent,Accept-Type,通过进一步的定义(例如 Accept-Language),或者给定上下文(例如 Referer),或者进行有条件的限制 (例如 If-None) 来修改请求。
Entity headers,例如 Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。示意图: 
Body
请求的最后一部分是它的 body。不是所有的请求都有一个 body:例如获取资源的请求,GET,HEAD,DELETE 和 OPTIONS,通常它们不需要 body。
Body 大致可分为两类:
Single-resource bodies,由一个单文件组成。该类型 body 由两个 header 定义: Content-Type 和 Content-Length.
Multiple-resource bodies,由多部分 body 组成,每一部分包含不同的信息位。通常是和 HTML Forms 连系在一起。
HTTP响应(response)
状态行
HTTP 响应的起始行被称作 状态行 (status line),包含以下信息:
协议版本,通常为 HTTP/1.1。
状态码 (status code),表明请求是成功或失败。常见的状态码是 200,404,或 302。
状态文本 (status text)。一个简短的,纯粹的信息,通过状态码的文本描述,帮助人们理解该 HTTP 消息。
一个典型的状态行看起来像这样:HTTP/1.1 404 Not Found。Headers
响应的 HTTP headers 遵循和任何其它 header 相同的结构:不区分大小写的字符串,紧跟着的冒号 (‘:’) 和一个结构取决于 header 类型的值。 整个 header(包括其值)表现为单行形式。
有许多响应头可用,这些响应头可以分为几组:
General headers,例如 Via,适用于整个报文。
Response headers,例如 Vary 和 Accept-Ranges,提供其它不符合状态行的关于服务器的信息。
Entity headers,例如 Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。
示意图: 
Body
响应的最后一部分是 body。不是所有的响应都有 body:具有状态码 (如 201 或 204) 的响应,通常不会有 body。
Body 大致可分为三类:
Single-resource bodies,由已知长度的单个文件组成。该类型 body 由两个 header 定义:Content-Type 和 Content-Length。
Single-resource bodies,由未知长度的单个文件组成,通过将 Transfer-Encoding 设置为 chunked 来使用 chunks 编码。
Multiple-resource bodies,由多部分 body 组成,每部分包含不同的信息段。但这是比较少见的。
http cookie
HTTP Cookie(也叫Webcookie或者浏览器Cookie)是服务器发送到用户浏览器并保存在浏览器上的一块数据,它会在浏览器下一次发起请求时被携带并发送到服务器上。可以它用来确定两次请求是否来自于同一个浏览器,从而能够确认和保持用户的登录状态。
Cookie主要用在以下三个方面:
会话状态管理(如用户登录状态、购物车)
个性化设置(如用户自定义设置)
浏览器行为跟踪(如跟踪分析用户行为)创建cookie:
当服务器收到HTTP请求时,可以在响应头里面增加一个Set-Cookie头部。浏览器收到响应之后会取出Cookie信息并保存,之后对该服务器每一次请求中都通过Cookie请求头部将Cookie信息发送给服务器。另外,Cookie的过期时间、域、路径、有效期、站点都可以根据需要来指定set-cookie响应头部和cookie请求头部:
服务器使用set-cookie响应头部向用户代理发送cookie信息,服务器告诉客户端要保存cookie信息,响应的数据里面应该包含set-cookie头,浏览器收到之后将cookie保存会话期cookie:
它在浏览器关闭之后会自动删除,仅在会话期间有效持久cookie:
它可以指定一个特定的过期时间或者有效期安全和httponly类型cookie:
只有在使用sll和https协议向服务器发送请求时,才能确保cookie被安全地发送到服务器cookie的作用域:
domain和path定义了cookie的作用域,即需要发送cookie的url集合
domain规定了需要发送cookie的主机名,默认是当前的文档地址上的主机名,如果指定了domain,则一般包含子域名
path表明需要发送cookie的url路径,用%x2F做文件夹分隔符
同站cookie:允许服务器指定在跨站请求时cookie是否会被发送,从而可以阻止跨站请求伪造攻击.同站Cookie:
同站Cookie允许服务器指定在跨站请求时Cookie是否会被发送,从而可以阻止跨站请求伪造攻击(CSRF)。第三方cookie:
cookie的域和页面的域是一样的,则是第一方cookie,如果cookie的域和页面的域不一样,则为第三方cookieSession和Cookie的区别
Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。















 2786
2786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









