






此教程仅供参考
注意:此文档目的是为了本人方便以后复习,不适合当教程,以免误导萌新...
1、安装三台Linux
2、在每台机器上安装JDK
3、配置每台机器的免密码登录
(*) 生成每台机器的公钥和私钥
hadoop112: ssh-keygen -t rsa
hadoop113: ssh-keygen -t rsa
hadoop114: ssh-keygen -t rsa
(*) 把hadoop112的公钥给hadoop112,Hadoop113 和hadoop114
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.112
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.113
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.114
(*) 把hadoop113的公钥给hadoop112,Hadoop113 和hadoop114
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.112
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.113
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.114
(*) 把hadoop114的公钥给hadoop112,Hadoop113 和hadoop114
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.112
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.113
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.137.114
4、在主节点(hadoop112)配置Hadoop
(*) 加压: tar -zxvf hadoop-2.4.1.tar.gz -C ~/training/
(*) 设置环境变量方式1
vi ~/.bash_profile
HADOOP_HOME=/opt/hadoop-2.6.4
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
生效
source ~/.bash_profile
设置环境变量方式2
vi /etc/profile
HADOOP_HOME=/opt/hadoop-2.6.4
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
生效ii
source /etc/profile
(*) 修改配置文件
(1)hadoop-env.sh
第25行: export JAVA_HOME=/opt/modules/jdk1.8.0_91

(2) hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
(3) core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.8.101:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.4/tmp</value>
</property>
(4) mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5) yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.8.101</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(6) slaves 从节点
192.168.8.101
192.168.8.102
192.168.8.103
(*) 进行格式化
hdfs namenode -format
出现日志:说明格式化成功
Storage directory /root/training/hadoop-2.4.1/tmp/dfs/name has been successfully formatted.
(*) 把配置好的Hadoop(112机器上),拷贝到101,102,103上
scp -r /opt/hadoop-2.6.4/ root@192.168.80.101:/opt
scp -r hadoop-2.4.1/ root@192.168.80.102:/root/training
scp -r hadoop-2.4.1/ root@192.168.80.103:/root/training
5、 修改101,102和103的环境变量
vi ~/.bash_profile
HADOOP_HOME=/root/training/hadoop-2.4.1
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
生效
source ~/.bash_profile
环境变量配置方式2也可以
6、在主节点上(hadoop100)启动hadoop集群
start-dfs.sh

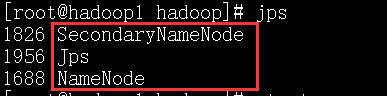
start-yarn.sh
只能在主节点上启动yarn,否则会报错!
上面的图是主节点的截图.
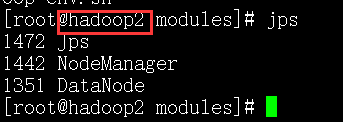
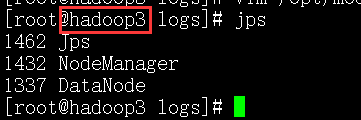
下面的是从节点的截图.
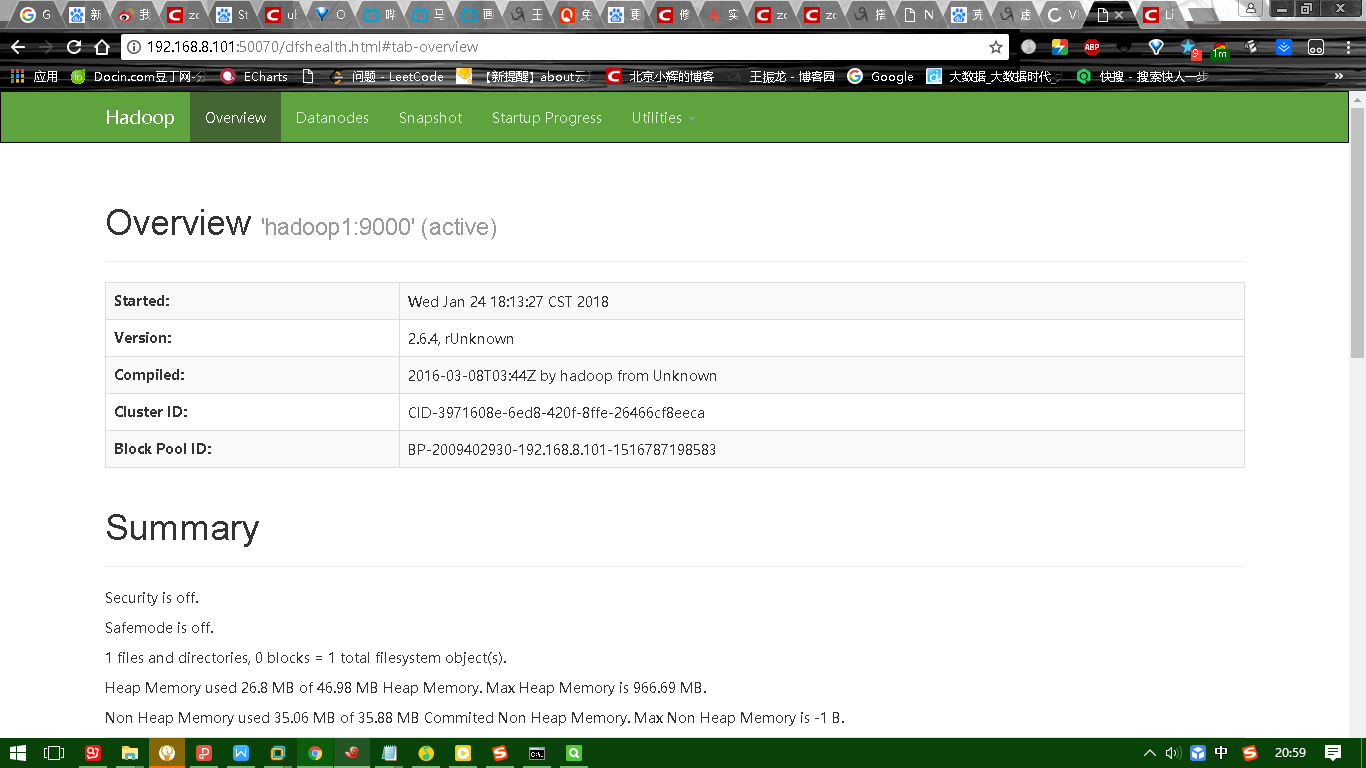
下图是HDFS的UI界面:
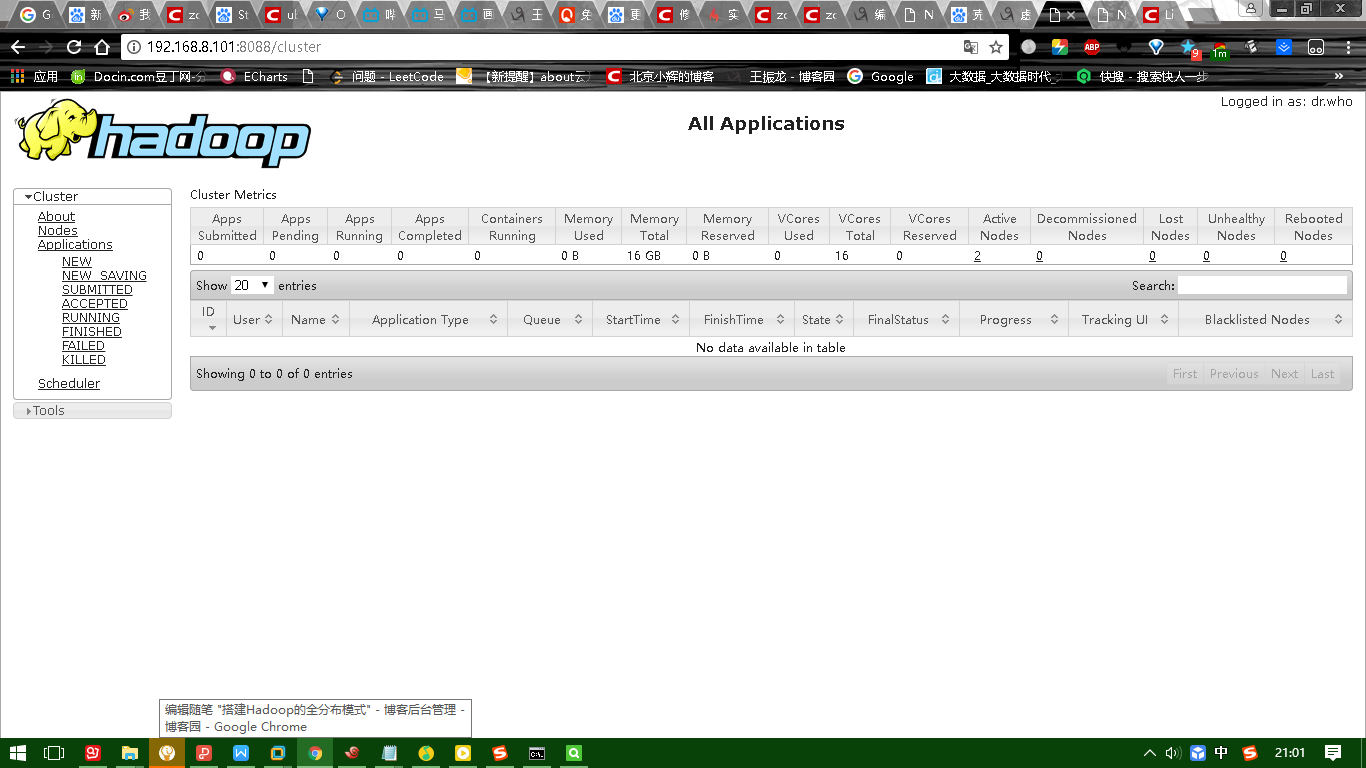
下图是yarn的UI界面:
7、日志:
Starting namenodes on [192.168.137.112]
192.168.137.112: starting namenode
192.168.137.113: starting datanode
192.168.137.114: starting datanode
starting resourcemanager
192.168.137.113: starting nodemanager
192.168.137.114: starting nodemanager
8、进程信息:
主节点: hadoop111
19589 ResourceManager
19458 SecondaryNameNode
19288 NameNode
从节点1:hadoop113
19220 NodeManager
19121 DataNode
从节点2:hadoop114
14159 NodeManager
13739 DataNode
9、错误:
org.apache.hadoop.hdfs.server.protocol.DisallowedDatanodeException: Datanode denied communication with namenode because hostname cannot be resolved
10、配置主机名(hadoop112 hadoop113 hadoop114)
vi /etc/hosts
192.168.8.101 Dog
192.168.8.102 Pig
192.168.8.103 Cat
11、web console:
HDFS: http://192.168.137.112:50070
Yarn: http://192.168.137.112:8088/
二、小结:HDFS和MapReducer
(一)什么是大数据?
(*) 天气预报
(*) 商品推荐
(*) 问题:(1)如何存储?如何找到? ----> 分布式的文件系统
(2)如何计算? ----> PageRank ---> MapReduce
(二)数据仓库:就是一个数据库,一般只做查询
(三)OLTP和OLAP
OLTP: online transaction processing
OLAP: online analyse processing
(四)Google的三篇论文
(1) GFS
(2) PageRank
(3) Bigtable ---> HBase
(五)搭建环境
(1) 本地模式:不具备HDFS的功能,只能测试MapReduce程序
(2) 伪分布模式:具备Hadoop的所有功能,在一台机器模拟分布式的环境
(3) 全分布模式:三台机器,具备Hadoop的所有功能
(六)HDFS
(1) 操作:命令行,JAVA API,Web Console(端口:50070)
(2) 上传数据和下载数据过程
(3) NameNode: 接收客户端请求
维护文件的元信息,默认在内存中,保存1000M的元信息
DataNode: 数据节点
SeondaryNameNode: 第二名称节点,元信息的合并(edits和fsimage)
(4) edits文件:日志文件,记录了客户端操作
使用edits viewer查看 hdfs oev *****
(5) fsimage文件:HDFS中文件的元信息文件
使用image viewer查看 hdfs ofv
(6) 高级特性:回收站(时间) ----> Oracle数据库的回收站 drop table---> 闪回 flashback
快照
配额:名称配额,空间配额
权限: 4种方式
安全模式:HDFS只读,检查数据块的副本率(0.999)
(7) RPC和动态代理(包装设计模式,增强方法的功能---> Proxy类)
(七)MapReduce(Yarn)
(1) ResourceManager:分配任务和资源
NodeManager:从DataNode获取数据(就近原则),执行任务
(2)Yarn调度任务的过程
(3) WordCount:(*)数据的流动
(*)Mapper Reducer Job
(4)序列化:WritableComparable,写的顺序和读的顺序一样
(5)排序:按照Key2排序、自然排序(LongWritable.Compartor)
多个列排序
对象排序(WritableComparable)
(6)合并Combiner:谨慎使用,不能改变原来的逻辑,是一种特殊的Reducer
(7)分区Parition
(8)Shuffle过程
(9)案例:(*)数据去重
(*)单表关联(自连接)
(*)多表关联(等值连接)
(*)倒排索引(Combiner不能改变原来的逻辑)















 1197
1197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









