






章节19
渲染和呈现
配置
这一章,我们开始编写在主循环中调用的drawFrame函数,这一函数调用会在屏幕上绘制一个三角形:
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
}
...
void drawFrame() {
}
同步
我们编写的drawFrame函数用于执行下面的操作:
- 从交换链获取一张图像
- 对帧缓冲附着执行指令缓冲中的渲染指令
- 返回渲染后的图像到交换链进行呈现操作
上面这些操作每一个都是通过一个函数调用设置的,但每个操作的实际执行却是异步进行的。函数调用会在操作实际结束前返回,并且操作的实际执行顺序也是不确定的。而我们需要操作的执行能按照一定的顺序,所以就需要进行同步操作。
有两种用于同步交换链事件的方式:栅栏(fence)和信号量(semaphore)。它们都可以完成同步操作。
栅栏(fence)和信号量(semaphore)的不同之处是,我们可以通过调用vkWaitForFences函数查询栅栏(fence)的状态,但不能查询信号量(semaphore)的状态。通常,我们使用栅栏(fence)来对应用程序本身和渲染操作进行同步。使用信号量(semaphore)来对一个指令队列内的操作或多个不同指令队列的操作进行同步。这里,我们想要通过指令队列中的绘制操作和呈现操作,显然,使用信号量(semaphore)更加合适。
信号量
在这里,我们需要两个信号量,一个信号量发出图像已经被获取,可以开始渲染的信号;一个信号量发出渲染已经结果,可以开始呈现的信号。我们添加了两个信号量对象作为成员变量:
VkSemaphore imageAvailableSemaphore;
VkSemaphore renderFinishedSemaphore;
添加createSemaphores函数用于创建上面这两个信号量对象:
void initVulkan() {
createInstance();
setupDebugCallback();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
createCommandBuffers();
createSemaphores();
}
...
void createSemaphores() {
}
创建信号量,需要填写VkSemaphoreCreateInfo结构体,但对于目前版本的Vulkan来说,这一结构体只有一个sType成员变量需要我们填写:
void createSemaphores() {
VkSemaphoreCreateInfo semaphoreInfo = {};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
}
未来版本的Vulkan或扩展可能会添加新的功能设置到这一结构体的flags和pNext成员变量。
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr,
&imageAvailableSemaphore) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr,
&renderFinishedSemaphore) != VK_SUCCESS) {
throw std::runtime_error("failed to create semaphores!");
}
信号量(semaphore)需要我们在应用程序结束前,所有它所同步的指令执行结束后,对它进行清除:
void cleanup() {
vkDestroySemaphore(device, renderFinishedSemaphore, nullptr);
vkDestroySemaphore(device, imageAvailableSemaphore, nullptr);
从交换链获取图像
之前提到,我们在drawFrame函数中进行的第一个操作是从交换链获取一张图像。这可以通过调用vkAcquireNextImageKHR函数完成,可以看到vkAcquireNextImageKHR函数的函数名带有一个KHR后缀,这是因为交换链是一个扩展特性,所以与它相关的操作都会有KHR这一扩展后缀:
void drawFrame() {
uint32_t imageIndex;
vkAcquireNextImageKHR(device, swapChain, std::numeric_limits<uint64_t>::max(),
imageAvailableSemaphore, VK_NULL_HANDLE, &imageIndex);
}
vkAcquireNextImageKHR函数的第一个参数是使用的逻辑设备对象,第二个参数是我们要获取图像的交换链,第三个参数是图像获取的超时时间,我们可以通过使用无符号64位整型所能表示的最大整数来禁用图像获取超时。
接下来的两个函数参数用于指定图像可用后通知的同步对象,可以指定一个信号量对象或栅栏对象,或是同时指定信号量和栅栏对象进行同步操作。在这里,我们指定了一个叫做imageAvailableSemaphore的信号量对象。
vkAcquireNextImageKHR函数的最后一个参数用于输出可用的交换链图像的索引,我们使用这个索引来引用我们的swapChainImages数组中的VkImage对象,并使用这一索引来提交对应的指令缓冲。
提交指令缓冲
我们通过VkSubmitInfo结构体来提交信息给指令队列:
VkSubmitInfo submitInfo = {};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
VkSemaphore waitSemaphores[] = {imageAvailableSemaphore};
VkPipelineStageFlags waitStages[] = {VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT};
submitInfo.waitSemaphoreCount = 1;
submitInfo.pWaitSemaphores = waitSemaphores;
submitInfo.pWaitDstStageMask = waitStages;
VkSubmitInfo结构体的waitSemaphoreCount、pWaitSemaphores和pWaitDstStageMask成员变量用于指定队列开始执行前需要等待的信号量,以及需要等待的管线阶段。这里,我们需要写入颜色数据到图像,所以我们指定等待图像管线到达可以写入颜色附着的管线阶段。waitStages数组中的条目和pWaitSemaphores中相同索引的信号量相对应。
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &commandBuffers[imageIndex];
commandBufferCount和pCommandBuffers成员变量用于指定实际被提交执行的指令缓冲对象。之前提到,我们应该提交和我们刚刚获取的交换链图像相对应的指令缓冲对象。
VkSemaphore signalSemaphores[] = {renderFinishedSemaphore};
submitInfo.signalSemaphoreCount = 1;
submitInfo.pSignalSemaphores = signalSemaphores;
signalSemaphoreCount和pSignalSemaphores成员变量用于指定在指令缓冲执行结束后发出信号的信号量对象。在这里,我们使用renderFinishedSemaphore信号量对象在指令缓冲执行结束后发出信号。
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, VK_NULL_HANDLE) != VK_SUCCESS) {
throw std::runtime_error("failed to submit draw command buffer!");
}
现在我们可以调用vkQueueSubmit函数提交指令缓冲给图形指令队列。vkQueueSubmit函数使用vkQueueSubmit结构体数组作为参数,可以同时大批量提交数据。vkQueueSubmit函数的最后一个参数是一个可选的栅栏对象,可以用它同步提交的指令缓冲执行结束后要进行的操作。在这里,我们使用信号量进行同步,没有使用它,将其设置为VK_NULL_HANDLE。
子流程依赖
渲染流程的子流程会自动进行图像布局变换。这一变换过程由子流程的依赖所决定。子流程的依赖包括子流程之间的内存和执行的依赖关系。虽然我们现在只使用了一个子流程,但子流程执行之前和子流程执行之后的操作也被算作隐含的子流程。
在渲染流程开始和结束时会自动进行图像布局变换,但在渲染流程开始时进行的自动变换的时机和我们的需求不符,变换发生在管线开始时,但那时我们可能还没有获取到交换链图像。有两种方式可以解决这个问题。一个是设置imageAvailableSemaphore信号量的waitStages为VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT,确保渲染流程在我们获取交换链图像之前不会开始。一个是设置渲染流程等待VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT管线阶段。在这里,为了让读者能够了解子流程依赖如何控制图像布局变换,我们使用第二种方式。
配置子流程依赖需要使用VkSubpassDependency结构体。让我们在createRenderPass函数添加下面的代码:
VkSubpassDependency dependency = {};
dependency.srcSubpass = VK_SUBPASS_EXTERNAL;
dependency.dstSubpass = 0;
srcSubpass和dstSubpass成员变量用于指定被依赖的子流程的索引和依赖被依赖的子流程的索引。VK_SUBPASS_EXTERNAL用来指定我们之前提到的隐含的子流程,对srcSubpass成员变量使用表示渲染流程开始前的子流程,对dstSubpass成员使用表示渲染流程结束后的子流程。这里使用的索引0是我们之前创建的子流程的索引。为了避免出现循环依赖,我们给dstSubpass设置的值必须始终大于srcSubpass。
dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.srcAccessMask = 0;
srcStageMask和srcAccessMask成员变量用于指定需要等待的管线阶段和子流程将进行的操作类型。我们需要等待交换链结束对图像的读取才能对图像进行访问操作,也就是等待颜色附着输出这一管线阶段。
dependency.dstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.dstAccessMask = VK_ACCESS_COLOR_ATTACHMENT_READ_BIT |
VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT;
dstStageMask和dstAccessMask成员变量用于指定需要等待的管线阶段和子流程将进行的操作类型。在这里,我们的设置为等待颜色附着的输出阶段,子流程将会进行颜色附着的读写操作。这样设置后,图像布局变换直到必要时才会进行:当我们开始写入颜色数据时。
renderPassInfo.dependencyCount = 1;
renderPassInfo.pDependencies = &dependency;
VkRenderPassCreateInfo结构体的dependencyCount和pDependencies成员变量用于指定渲染流程使用的依赖信息。
呈现
渲染操作执行后,我们需要将渲染的图像返回给交换链进行呈现操作。我们在drawFrame函数的尾部通过VkPresentInfoKHR结构体来配置呈现信息:
VkPresentInfoKHR presentInfo = {};
presentInfo.sType = VK_STRUCTURE_TYPE_PRESENT_INFO_KHR;
presentInfo.waitSemaphoreCount = 1;
presentInfo.pWaitSemaphores = signalSemaphores;
waitSemaphoreCount和pWaitSemaphores成员变量用于指定开始呈现操作需要等待的信号量。
VkSwapchainKHR swapChains[] = {swapChain};
presentInfo.swapchainCount = 1;
presentInfo.pSwapchains = swapChains;
presentInfo.pImageIndices = &imageIndex;
接着,我们指定了用于呈现图像的交换链,以及需要呈现的图像在交换链中的索引。
presentInfo.pResults = nullptr; // Optional我们可以通过pResults成员变量获取每个交换链的呈现操作是否成功的信息。在这里,由于我们只使用了一个交换链,可以直接使用呈现函数的返回值来判断呈现操作是否成功,没有必要使用pResults。
vkQueuePresentKHR(presentQueue, &presentInfo);调用vkQueuePresentKHR函数可以请求交换链进行图像呈现操作。在下一章节,我们会对vkAcquireNextImageKHR函数和vkQueuePresentKHR函数添加错误处理的代码,应对调用它们失败后的情况。
现在如果编译运行程序,当我们关闭应用程序窗口时,我们的程序直接就奔溃了。如果开启了校验层,我们可以从控制台窗口看到调试回调函数打印的错误信息。
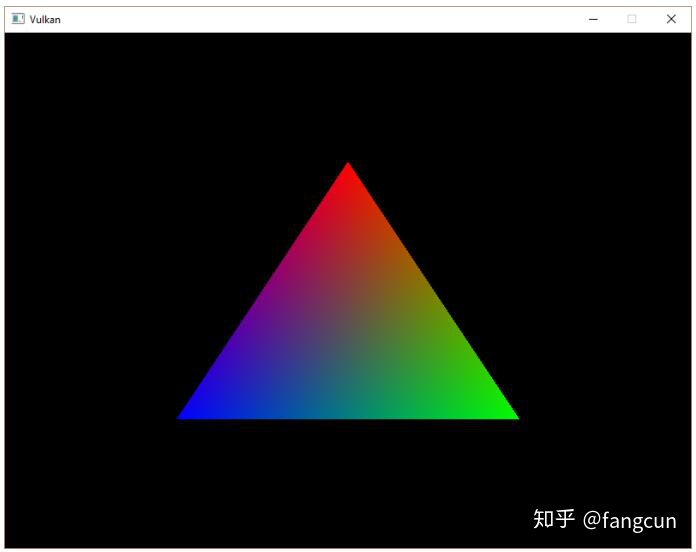

造成这一问题的原因是drawFrame函数中的操作是异步执行的。这意味着我们关闭应用程序窗口跳出主循环时,绘制操作和呈现操作可能仍在继续执行,这与我们紧接着进行的清除操作也是冲突的。
我们应该等待逻辑设备的操作结束执行才能销毁窗口:
void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
vkDeviceWaitIdle(device);
}我们可以使用vkQueueWaitIdle函数等待一个特定指令队列结束执行。现在再次编译运行程序,关闭应用程序窗口就不会造成程序直接崩溃了。
多帧并行渲染
如果读者开启校验层后运行程序,观察应用程序的内存使用情况,可以发现我们的应用程序的内存使用量一直在慢慢增加。这是由于我们的drawFrame函数以很快地速度提交指令,但却没有在下一次指令提交时检查上一次提交的指令是否已经执行结束。也就是说CPU提交指令快过GPU对指令的处理速度,造成GPU需要处理的指令大量堆积。更糟糕的是这种情况下,我们实际上对多个帧同时使用了相同的imageAvailableSemaphore和renderFinishedSemaphore信号量。
最简单的解决上面这一问题的方法是使用vkQueueWaitIdle函数来等待上一次提交的指令结束执行,再提交下一帧的指令:
void drawFrame() {
...
vkQueuePresentKHR(presentQueue, &presentInfo);
vkQueueWaitIdle(presentQueue);
}
但这样做,是对GPU计算资源的大大浪费。图形管线可能大部分时间都处于空闲状态。为了充分利用GPU的计算资源,现在我们扩展我们的应用程序,让它可以同时渲染多帧。
首先,我们在源代码的头部添加一个常量来定义可以同时并行处理的帧数:
const int MAX_FRAMES_IN_FLIGHT = 2;
为了避免同步干扰,我们为每一帧创建属于它们自己的信号量:
std::vector<VkSemaphore> imageAvailableSemaphores;
std::vector<VkSemaphore> renderFinishedSemaphores;
我们需要对createSemaphores函数进行修改来创建每一帧需要的信号量对象:
void createSemaphores() {
imageAvailableSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
renderFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
VkSemaphoreCreateInfo semaphoreInfo = {};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr,
&imageAvailableSemaphores[i]) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr,
&renderFinishedSemaphores[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create semaphores for a frame!");
}
}
}
在应用程序结束前,我们需要清除为每一帧创建的信号量:
void cleanup() {
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vkDestroySemaphore(device, renderFinishedSemaphores[i], nullptr);
vkDestroySemaphore(device, imageAvailableSemaphores[i], nullptr);
}
...
}
我们添加一个叫做currentFrame的变量来追踪当前渲染的是哪一帧。之后,我们通过这一变量来选择当前帧应该使用的信号量:
size_t currentFrame = 0;
修改drawFrame函数,使用正确的信号量对象:
void drawFrame() {
vkAcquireNextImageKHR(device, swapChain, std::numeric_limits<uint64_t>::max(),
imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE,
&imageIndex);
...
VkSemaphore waitSemaphores[] = {imageAvailableSemaphores[currentFrame]};
...
VkSemaphore signalSemaphores[] = {renderFinishedSemaphores[currentFrame]};
...
}
最后,不要忘记更新currentFrame变量:
void drawFrame() {
...
currentFrame = (currentFrame + 1) % MAX_FRAMES_IN_FLIGHT;
}
上面代码,我们使用模运算(%)来使currentFrame变量的值在0到MAX_FRAMES_IN_FLIGHT-1之间进行循环。
我们还需要使用栅栏(fence)来进行CPU和GPU之间的同步,来防止有超过MAX_FRAMES_IN_FLIGHT帧的指令同时被提交执行。栅栏(fence)和信号量(semaphore)类似,可以用来发出信号和等待信号。我们为每一帧创建一个VkFence对象:
std::vector<VkSemaphore> imageAvailableSemaphores;
std::vector<VkSemaphore> renderFinishedSemaphores;
std::vector<VkFence> inFlightFences;
size_t currentFrame = 0;
将createSemaphores函数修改为createSyncObjects函数来在一个函数中创建所有同步对象:
void createSyncObjects() {
imageAvailableSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
renderFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
inFlightFences.resize(MAX_FRAMES_IN_FLIGHT);
VkSemaphoreCreateInfo semaphoreInfo = {};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
VkFenceCreateInfo fenceInfo = {};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr,
&imageAvailableSemaphores[i]) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr,
&renderFinishedSemaphores[i]) != VK_SUCCESS ||
vkCreateFence(device, &fenceInfo, nullptr,
&inFlightFences[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create
synchronization objects for a frame!");
}
}
}
在应用程序结束前,清除我们创建的VkFence对象:
void cleanup() {
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vkDestroySemaphore(device, renderFinishedSemaphores[i], nullptr);
vkDestroySemaphore(device, imageAvailableSemaphores[i], nullptr);
vkDestroyFence(device, inFlightFences[i], nullptr);
}
...
}
修改drawFrame函数使用我们创建的栅栏(fence)对象进行同步。vkQueueSubmit函数有一个可选的参数可以用来指定在指令缓冲执行结束后需要发起信号的栅栏(fence)对象。我们通过它来发起一帧结束执行的信号。
void drawFrame() {
...
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFences[currentFrame]) != VK_SUCCESS) {
throw std::runtime_error("failed to submit draw command buffer!");
}
...
}
现在需要我们修改drawFrame函数来等待我们当前帧所使用的指令缓冲结束执行:
void drawFrame() {
vkWaitForFences(device, 1, &inFlightFences[currentFrame], VK_TRUE, std::numeric_limits<uint64_t>::max());
vkResetFences(device, 1, &inFlightFences[currentFrame]);
...
}
vkWaitForFences函数可以用来等待一组栅栏(fence)中的一个或全部栅栏(fence)发出信号。上面代码中我们对它使用的VK_TRUE参数用来指定它等待所有在数组中指定的栅栏(fence)。我们现在只有一个栅栏(fence)需要等待,所以不使用VK_TRUE也是可以的。和vkAcquireNextImageKHR函数一样,vkWaitForFences函数也有一个超时参数。和信号量不同,等待栅栏发出信号后,我们需要调用vkResetFences函数手动将栅栏(fence)重置为未发出信号的状态。
现在编译运行程序,读者可能会感到奇怪。应用程序没有呈现出我们渲染的三角形。启用校验层后运行程序,我们在控制台窗口看到下面这样的信息:

出现这一问题的原因是,默认情况下,栅栏(fence)对象在创建后是未发出信号的状态。这就意味着如果我们没有在vkWaitForFences函数调用之前发出栅栏(fence)信号,vkWaitForFences函数调用将会一直处于等待状态。我们可以在创建栅栏(fence)对象时,设置它的初始状态为已发出信号来解决这一问题:
void createSyncObjects() {
...
VkFenceCreateInfo fenceInfo = {};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
fenceInfo.flags = VK_FENCE_CREATE_SIGNALED_BIT;
...
}
现在可以重新编译运行程序,内存泄漏问题应该已经不见了!我们已经通过同步机制确保不会有超过我们设定数量的帧会被异步执行。对于其它需要同步的地方,比如cleanup函数,使用vkDeviceWaitIdle函数的效果也足够好,不需要使用栅栏或信号量。
总结
到此为止,我们大概编写了900多行代码,终于可以在屏幕上看到自己用代码渲染的三角形。如此繁琐的设置跟Vulkan的一切都需要显式地指定有关。读者可以花点时间重新阅读自己编写的代码,对代码中我们设置的对象建立更加清晰的认知。在之后的章节,我们会在目前的基础上逐步扩展,让大家对Vulkan有更加深刻的认识。
下一章节,我们将对目前的程序进行一些细节上的改进。














 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









