






相信很多ORACLE DBA在职业生涯中或多或少都遇到过这样的情况:
下面我通过几个实战案例,给大家介绍几例数据文件异常可采用的非常规恢复方法。
一、数据文件被
实验场景:由于维护人员的误操作,导致
>>>> 故障模拟
10 点59分,误操作删除文件

11 点20分数据库alert日志显示出现ora-01116等错误,根据后台日志显示此时ts_test01.
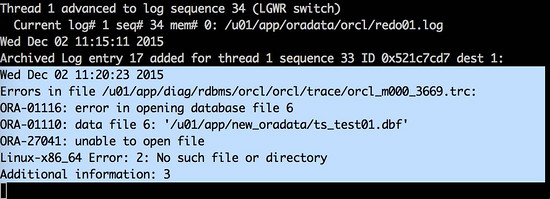
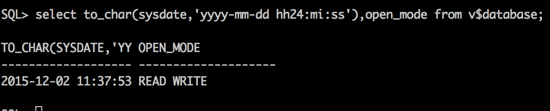
但是数据库没有因此关闭,还处于read write状态。
>>>> 问题分析
数据文件被误删,数据库仍然处于open状态。对于此问题可以通过
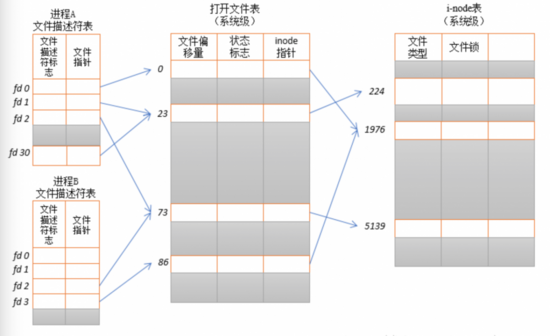
在linux 系统中,数据文件被删除后,其文件句柄还被相关数据库
>>>> 恢复步骤
尝试通过oracle dbwr进程找到被误删除的文件句柄
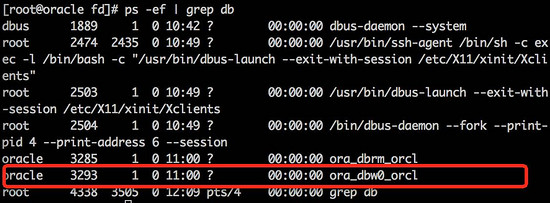
当前的oracle dbwr进程的spid是3293 可以通过该进程找到丢失的ts_test01.dbf 文件句柄

含一些数字命名的

通过copy的方式恢复已删除的数据文件,并设置正确的属组权限。


通过将offline 相关表
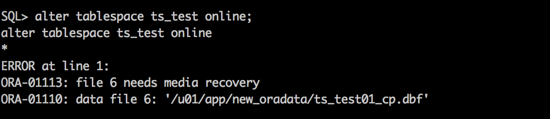
由于前期数据文件无法open的问题,部分已更改的数据无法写入数据文件,导致datafile header 上的checkpoint#和controlfile文件的checkpoint_change#不一致,需要对数据文件进行介质恢复。

进行介质恢复之后,表空间可以正常online,故障处理也算完成。
>>>>
作为系统维护人员rm,mv均属于高危操作,在执行之前一定要反复思考,确定影响,做到“宁停3分,不抢1秒”。当遇到数据库问题时,应维持故障现状,在没有清楚的了解问题原因以及解决方案之前,草率的行动将使问题复杂化,造成不可估量的损失。对于此案例,如果贸然的关闭数据库,只能使用rman备份进行恢复,如果备份失效,数据丢失将不可避免。总之做到,临危不乱!三思而行!
二、使用bbed跳过归档文件的完全恢复
实验场景:存储损坏导致部分数据文件损坏,需要使用备份进行还原,在数据库恢复阶段发现缺失部分归档,导致数据库无法恢复,正常启动。
>>>> 实验环境准备
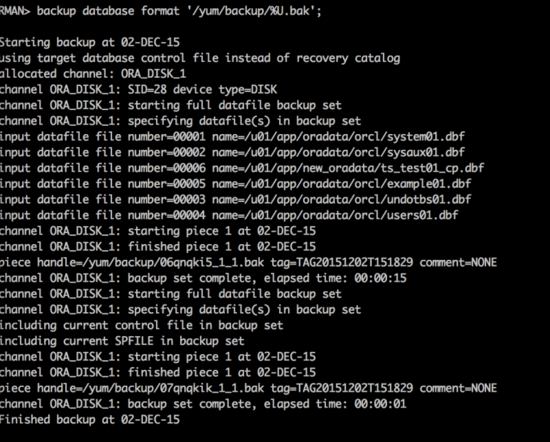
使用rman 为数据库做一个全备
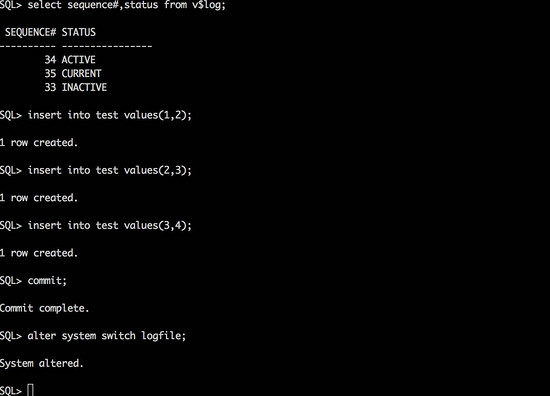
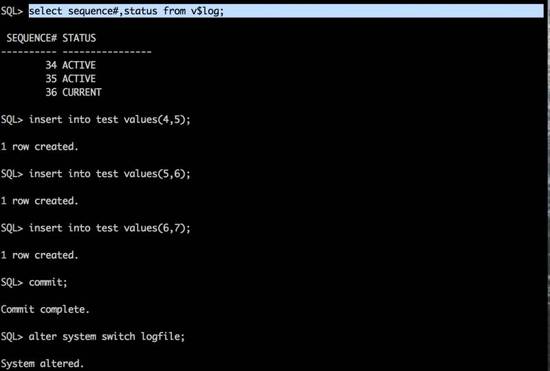
对test表执行insert操作,每三次insert后执行一次switch logfile,保证生成的34,35,36三个归档各包含3条insert的操作日志。
>>>> 故障模拟
通过abort方式停库后,删除ts_test01.dbf 文件模拟存储故障。
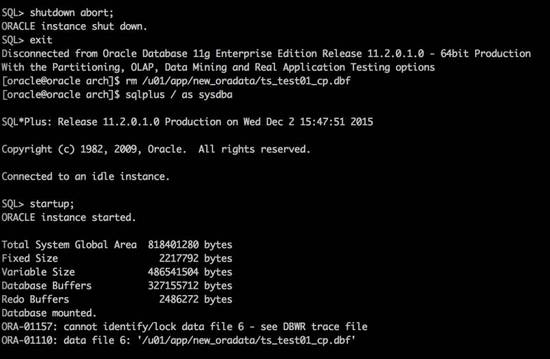
人为删除sequence 35的归档日志。至此,故障已经重现。

当再次使用s
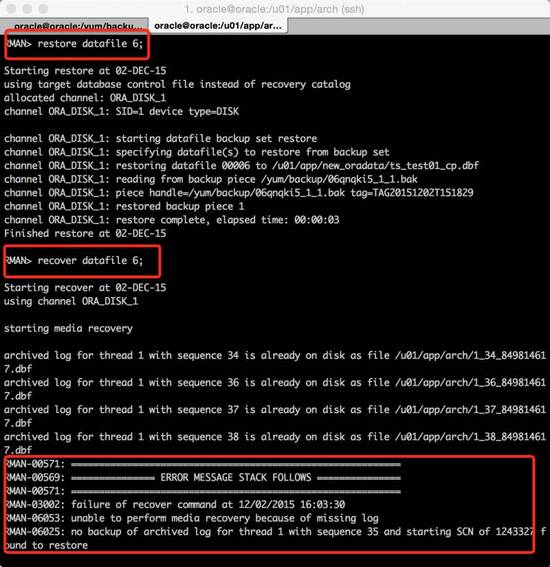
通过rman 的方式进行数据文件还原。在介质恢复阶段rman报错:no backup of archived log for thread 1 with sequence 35 and startingscn of…….。正是因为缺失了35号归档导致还原无法完成(35号归档已经被人为删除)。
归档日志按
在此情况下使用常规手段显然无法正常open数据库。需要通过bbed跳过缺失的归档使其继续完成介质恢复。
>>>> 恢复步骤
通过rman的crosscheck archivelog all命令校验归档日志发现,缺少35号归档。
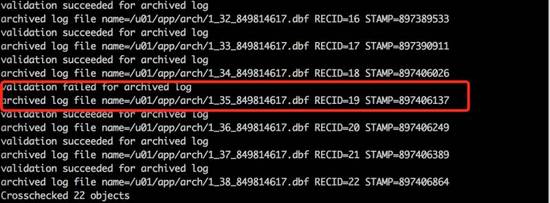
跳过缺失的归档需要将6号文件的scn向前推进至少大于等于36号归档的first change#1243371
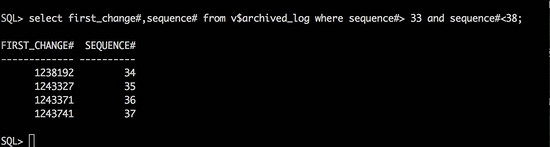
数据文件的scn被记录在文件1号block偏移量484字节开始的四个字节中。当前6号文件的scn经过大小端转换之后十进制的数值为1243327(dump的原值为bff81200经大小端转换后的十六进制为0012f8bf)。该值正好是35号归档的first change#
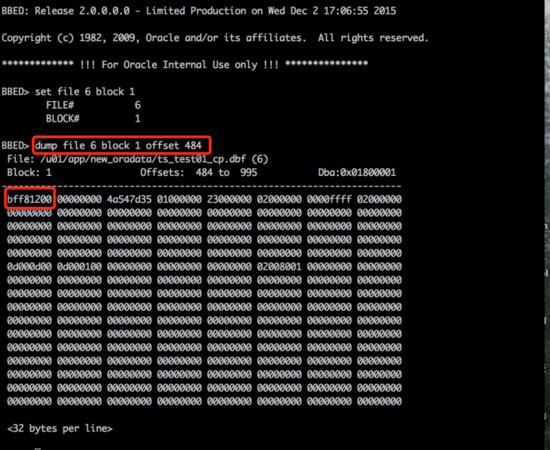
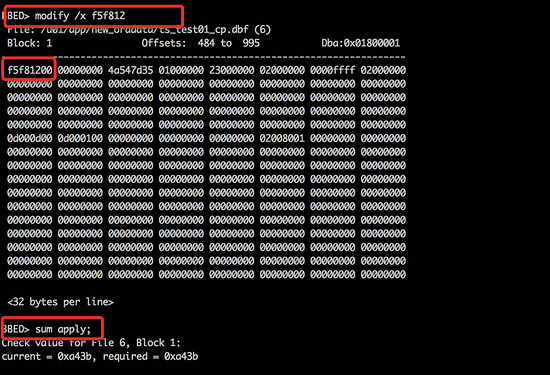
使用bbed更改数据文件头的scn号,使其变为1243381(注意更改的scn需要大于36号归档的first change#,在这次实验中使用36号归档的first change#10作为新的scn号,经过十六进制以及大小端转换后数据为f5f812), 并使用sum apply 命令重新计算校验和。
要想跳过归档还需要数据文件头块的rba。它由seq#、log block#、偏移量(固定为16)组成,决定了数据文件从哪个归档日志的哪个位置开始应用归档。Rba位于数据文件头块偏移量500处开始连续的12个字节(如图从23开始到0000ffff结束,前4个字节是日志的序列号,中间4个字节是日志块号,最后4个字节是偏移量)。
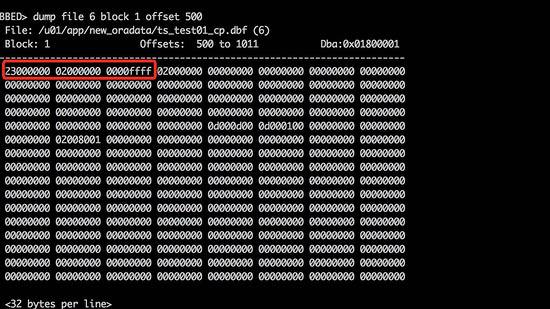
将rba修改为接下去的归档日志.log block#.offset#(这次试验rba被修改为24000000.02000000.10000000即36.2.16)

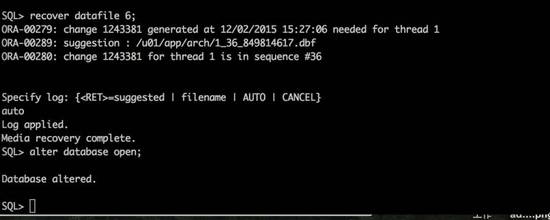
再次执行数据文件6的介质恢复后数据库可以正常打开。由于跳过了部分日志,免不了存在数据丢失或者不一致的问题。对于采用此方法恢复的数据库建议在合适的时候停机重建。
>>>> 总结感悟
备份作为保障数据















 1329
1329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









