






测试用例4:100个记录等价类2的成员
测试用例5:999个记录邻接边界值
测试用例6:1000个记录边界值
测试用例7:1001个记录等价类3成员且邻接边界值
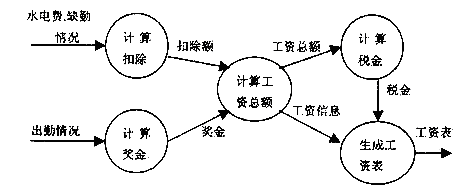
3.工资计算系统中的一个子系统有如下功能:
( 1 )计算扣除部分—由基本工资计算出应扣除(比如水电费、缺勤)的部分;
( 2 )计算奖金部分—根据职工的出勤情况计算出奖励金;
( 3 )计算工资总额部分—根据输入的扣除额及奖金计算出总额;
( 4 )计算税金部分—由工资总额中计算出应扣除各种税金;
( 5 )生成工资表—根据计算总额部分和计算税金部分传递来的有关职工工资的详细信息生成工资表。试根据要求画出该问题的数据流程图。
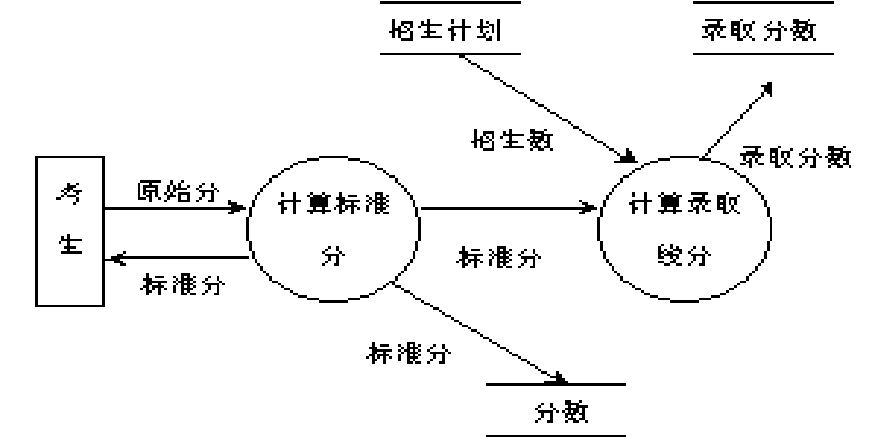
4一个考试录取统计分数子系统有如下功能:
(1) 计算标准分:根据考生原始分计算,得到标准分,存入考生分数文件;
(2) 计算录取线分:根据标准分、招生计划文件中的招生人数,计算录取线,存入录取线文件。
试根据要求画出该系统的数据流程图。
5阅读如下程序,说出该程序属于哪种耦合方式,为什么?并说明可以采用何种方式降藕。
public class Test{
public int calSum(Worker w) //Worker为类名{
int wLevel=w.getLevel();
int wSalary=w.getSalary();
//计算工人奖金收入等}.......}
这段程序存在印记耦合,因为该程序将类声明为了方法的参数类型。可采用接口或者简单参数类型的方法降藕。
6首先说出什么是基本途径测试,然后为以下程序流程图设计基本途径测试的测试用例,并标明路径。
基本途径测试是指覆盖基本途径集合的试验用例将使程序中的每条语句至少执行一次。
测试用例如下:x=3,y=0,z=3(覆盖x>2,y=0,x=3,z>1,通过路径abcde);














 6104
6104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









