






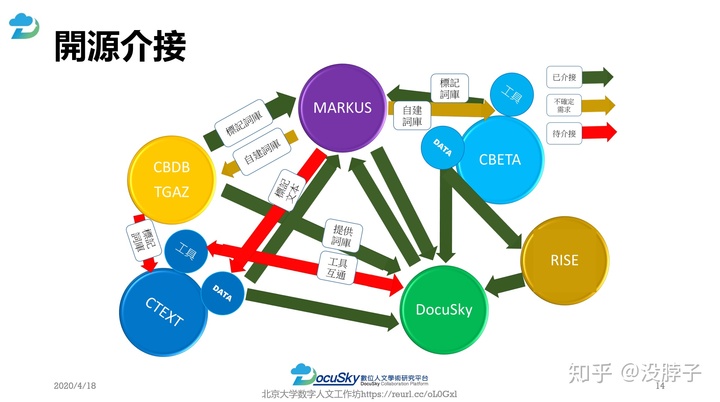
DocuSky是一个个人化的数位人文协作平台,可以为研究者提供一些数位人文研究的服务。并且同马库斯、CBDB、Palladio有着兼容性,可以实现跨平台操作,形成更全面的工作流程和功能。
北京大学工作坊教程视频链接
首先我们可以通过多种方式来获取原始的文本,例如维基百科,网站爬虫,资源下载,或者ocr。在我们得到这些文本之后,如果想对其中涉及的人物、地名、书名、时间等等多种类的词进行分析时,往往需要进行词性标注、替换等。举个简单的例子,《魔道祖师》中的魏无羡,名字叫魏婴,号夷陵老祖,对话中也会被称作魏公子,在我们进行文本分析的时候就要把所有指代一个人的词都换成一个,例如魏无羡,以方便后面的统计词频、趋势变化等工作。那么今天就以人名地名的提取为主要的目的,以国语版《海上花列传》为例,来带大家熟悉一下Docusky强大的建库工作。
首先我们需要对txt或者word格式的文本进行一个结构化的工作,来整理成一个excel表:

当然,这些字段也可以根据需要进行替换。但是要注意的是,Filename这一字段一定要有,并且值唯一,不能有重复项。并且由于识别排序的问题,应该使用001、0001的计数方式,否则顺序就会发生错误(血的教训)。具体前面几个0应该根据数据总条数调整,例如一共有1200个数据,那么编号就应该是0001-1200。
接下来,让我们进入Docusky进行建库工作。
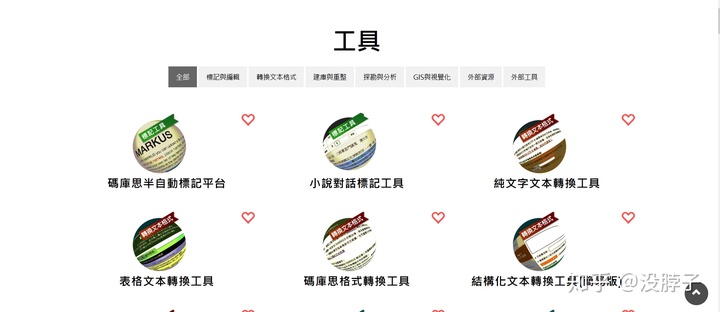
工具界面分成了7大种类,可以根据需求进行选择。因为建库需要.xml文件,所以我们需要将我们的excel转换成.xml文件。使用转换文本格式标签下的表格文本转换工具。

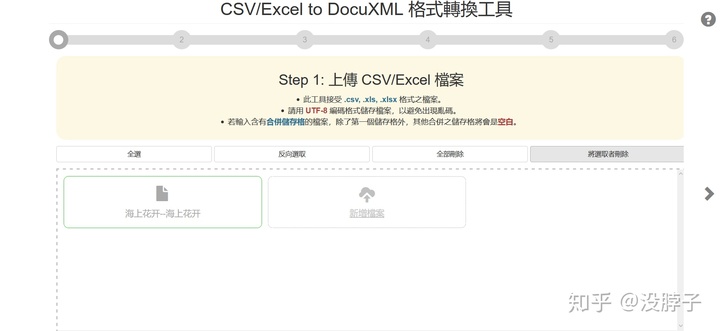
传入刚才的表格,点全选,再下一步。
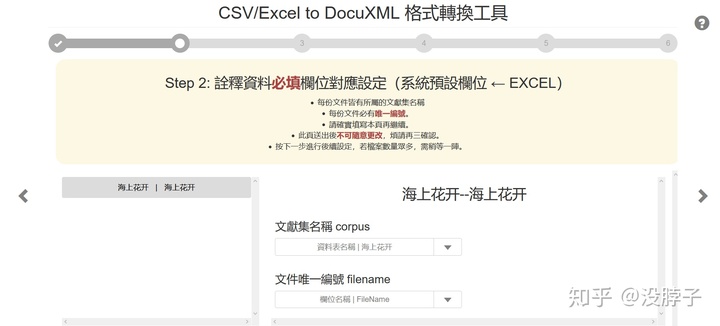
文献集名称选择资料表名称就可以,唯一编号就选filename
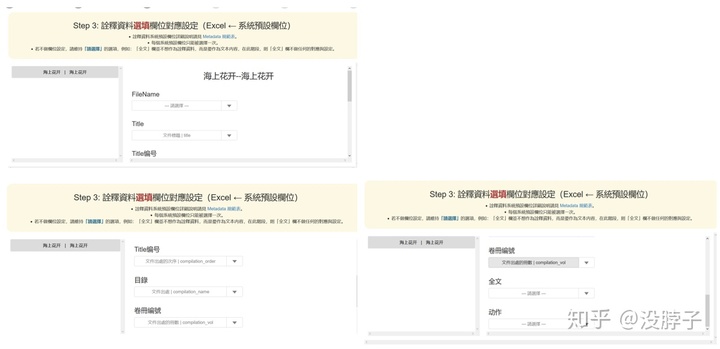
第一个和最后两个不用填。这里可以将excel表里的每一列对应到数据库中并在特定标签下显示。
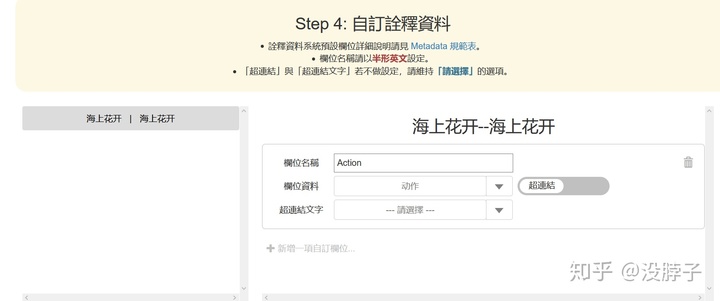
这一步可以增加自定的栏位。可以满足个性化的需求。之前在建excel的时候为每个事件都填写了属于什么类型的动作,所以这里可以增加动作栏位。
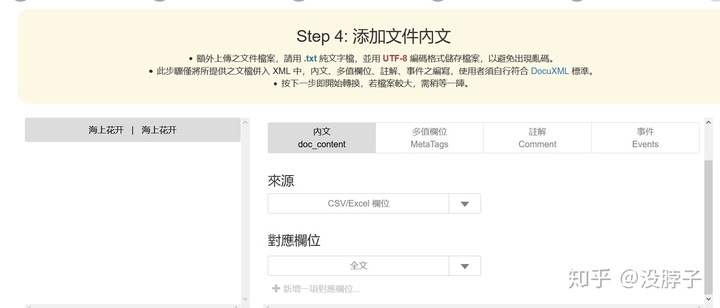
在这里可以设置刚才没有设置的正文部分。
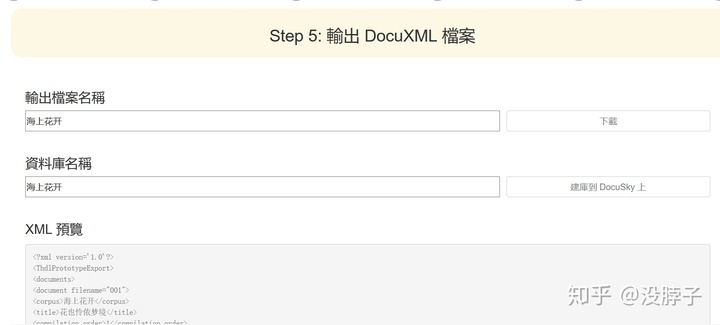
到这里建库基本结束,命名之后最好下载一份,并且点击建库到DocuSky上。在下面可以预览,如果发现错误的话可以返回修改。
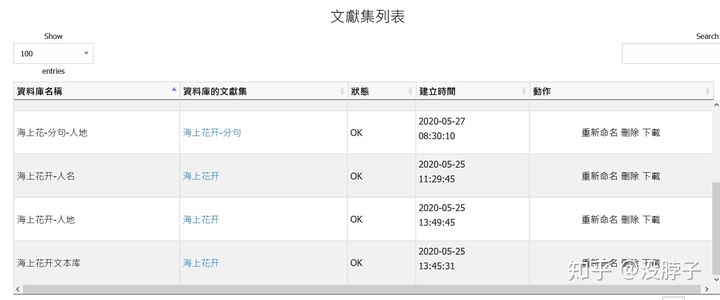
建库需要一些时间。等待状态为OK时说明建库成功了。
虽然说建完了库,但是我们的最终目标还没达到。人名地名还没标注。我们自己做了人名地名字典,需要按照格式再准备一个excel表:tagVal内填所有属于人/地名的词,Term填权威词,即将前面的词全部替换为一个词。最后一项可以附上该人物在CBDB的链接,建库之后可以点击进入该人物库中查看。这里暂且不填。
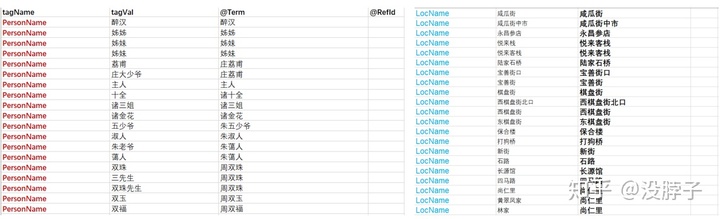
填好之后,我们需要构建一个新的标记人地名称字典的库。
点击标记与编辑标签下的批次标记工具,进入界面需要加载两个文件:一个是xml文件,另一个是刚才的人地名字典excel文件。点击输出,会得到一个CT-开头的文件。

工作还没有全部完成,继续来到建库与重整标签,选择诠释资料管理工具。

选择刚才CT开头的xml文件,
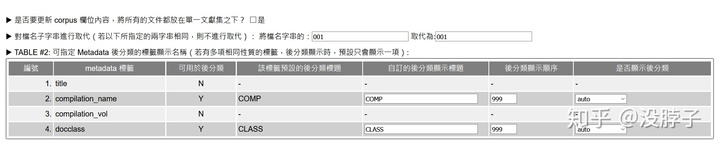
后分类显示顺序可以调整其在自订后分类显示的顺序。比如我们把complication_name调成1,在数据库中目录就会第一个显示。

下拉会出现这一栏,可以在自定展示标题处写上自己比较好分辨的名称。我们可以写成人名和地名。

最后会输出一个以-M结尾的文件。我们点开自己的资料库:
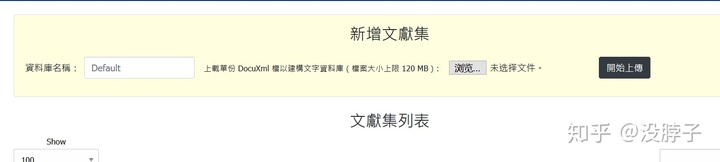
命名后点浏览,上传刚才的xml文件即可。至此所有建库工作全部结束。
接下来可以看一下成果:

人地名都被标记了。还可以点击右上角的Tag,进行词云、筛选等多种操作。在想查看的人物前面打勾,再进行筛选/过滤等等操作,就可以只看他出场的章节。
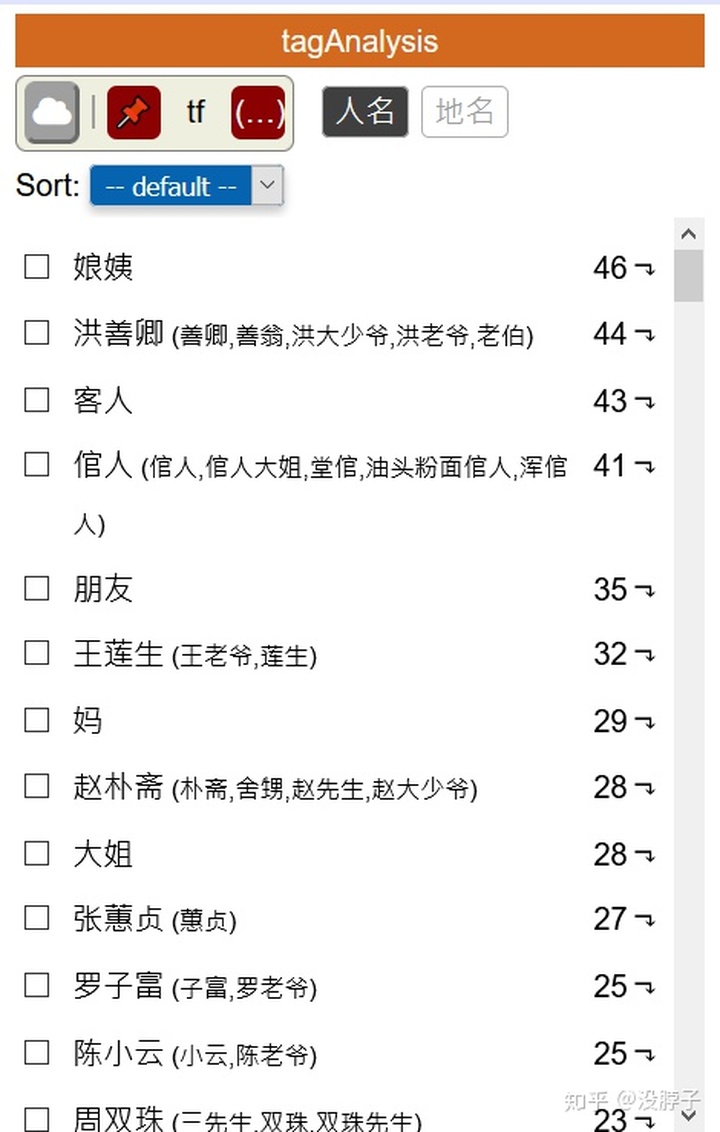
点第一个云的标签,可以用词云的方式显示:

此外还可以用词缀工具查看与特定词相连的词。比如我们想看洪善卿的后两个出现过什么字,我们可以设置如下的检索式:
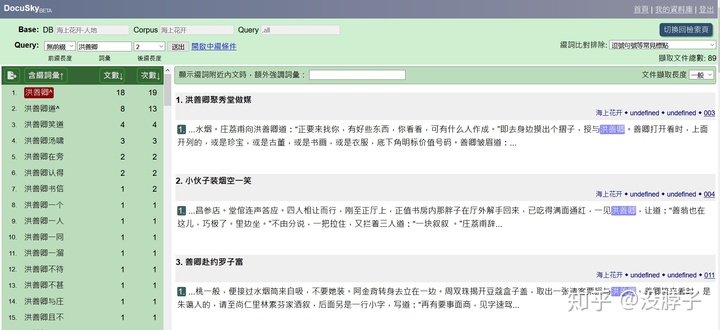
这个功能可以帮我们词与词之间潜在的语义关系。
那么建库完成了,我们从哪获取数据来进行下一就要用到词汇分析工具:到本地开展下一步分析呢?我们再次从首页的探勘与分析标签页下找到标记与词汇分析工具。

我们直接来到corpus,因为是直接从docusky我们自己的库中被标注好的文本进行分析,所以步骤相对简单。当然也可以直接传入一个未被标注的文档和一个希望查看词频的文档进行标记并进行词频统计。步骤是相似的。
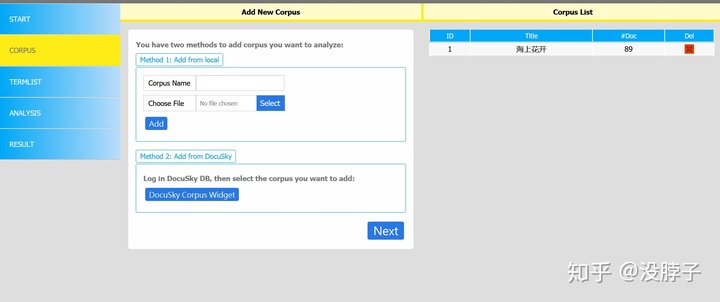
点击method2里面的蓝色按钮传入文件,就直接跳到Analysis一栏,因为我们直接用的库里的文件,所以点击右面的选项卡,把人名地名都勾选上点击run。
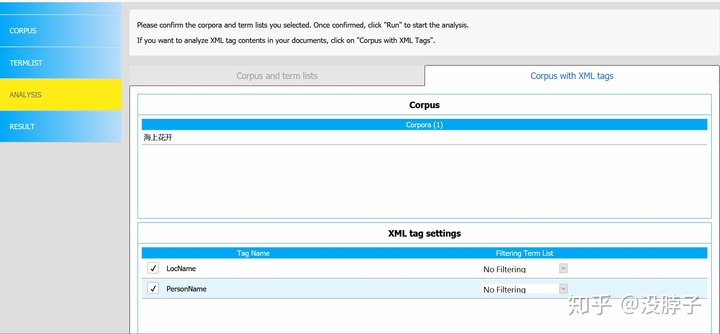
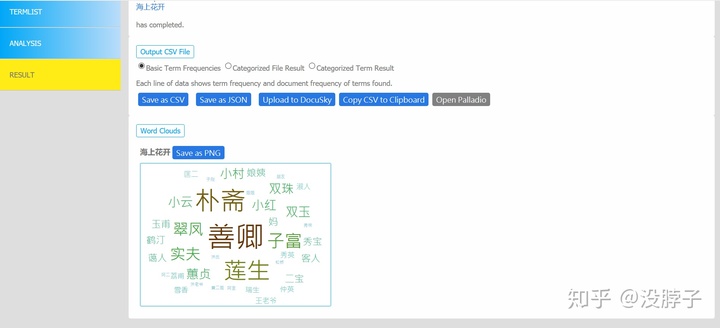
可以看到分析结果导出方式有3种,我们分别来看看:
第一种:基本词频
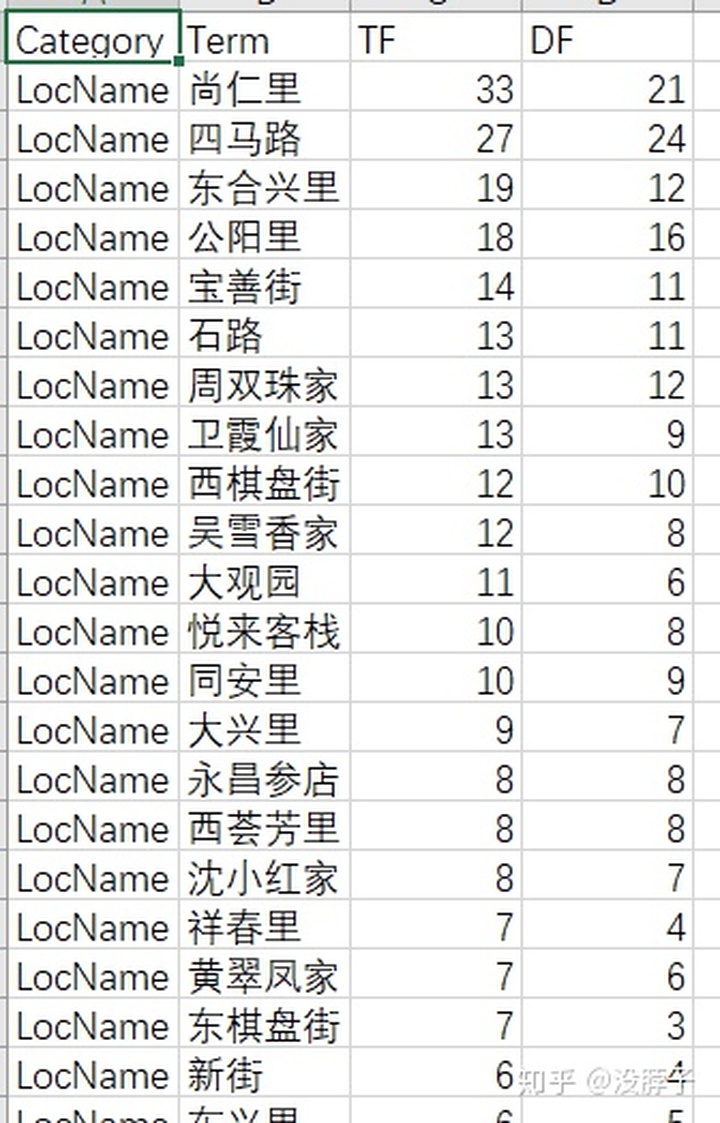
提供了TF(词频)IDF(逆向文件频率),两者乘积可以看这个词在文本中的重要程度。
再来看第二个:
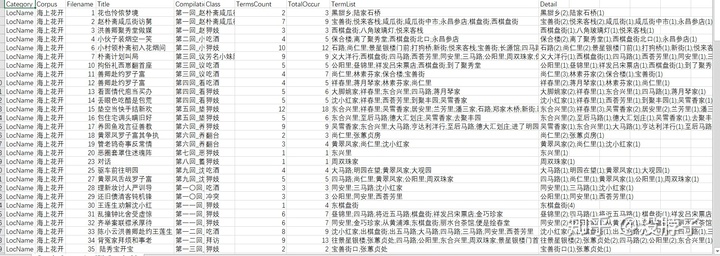
以及第三个:
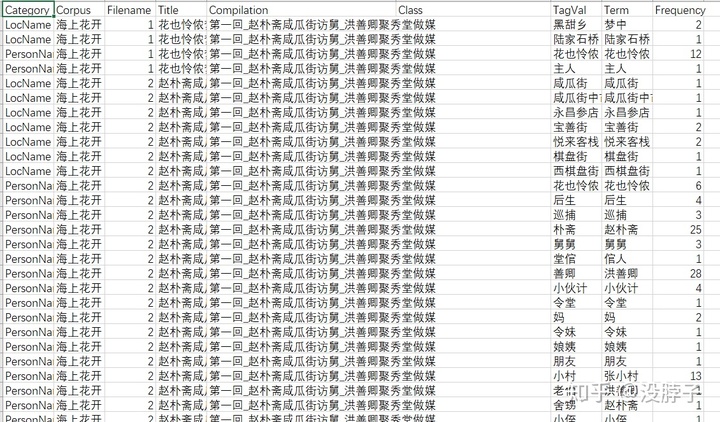
前者是以每个filename做一行,把这句话里面的地名、人名分别提了出来。后者是以每个term做一行,其实就相当于前者的拆分。使用者可以根据需求自行判断。
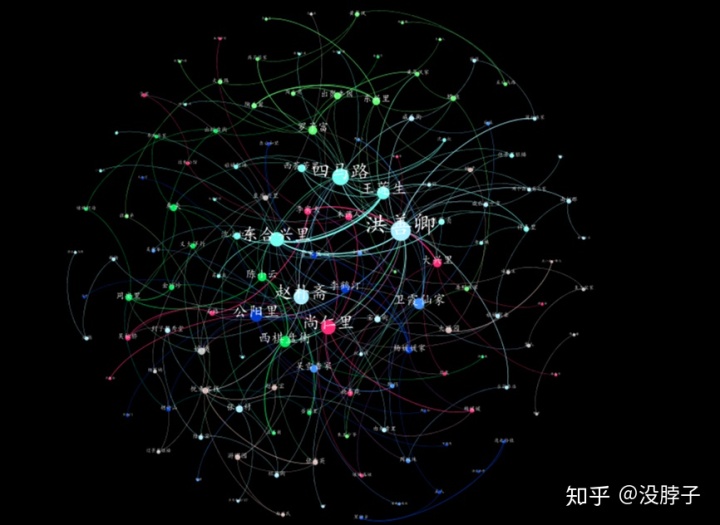
本次的分享就到这里,来看看通过平台实现的结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









