






所用库
requestshtml
xpath解析库python
multiprocessing多进程mysql
pymysql数据库操做库git
实战背景
主要是爬取知乎热榜的问题及点赞数比较高的答案,经过requests请求库进行爬取,xpath进行解析,并将结果存储至mysql数据库中github
爬取的url为:https://www.zhihu.com/hotajax
源码保存在个人github上:知乎热榜问题及答案数据获取sql
文章首发于我的网站:大圣的专属空间数据库
代码实现
首先获取问题的标题以及其下属的答案的url地址,代码以下:json
import requests
from lxml import etree
import time
import multiprocessing
import pymysql
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
'cookie': '***********'
}
url = 'https://www.zhihu.com/hot'
def get_question_num(url,headers):
response = requests.get(url,headers=headers)
text = response.text
html = etree.HTML(text)
reslut = html.xpath("//section[@class='HotItem']")
# 获取问题的ID
question_list = []
for question in reslut:
number = question.xpath(".//div[@class='HotItem-index']//text()")[0].strip()
title = question.xpath(".//h2[@class='HotItem-title']/text()")[0].strip()
href = question.xpath(".//div[@class='HotItem-content']/a/@href")[0].strip()
question_num = href.split('/')[-1]
question_list.append([question_num,title])
# print(number,'\n',title,'\n',href)
return question_list
其中,在请求头中加入了user-agent以及本身的cookie,以下图:api
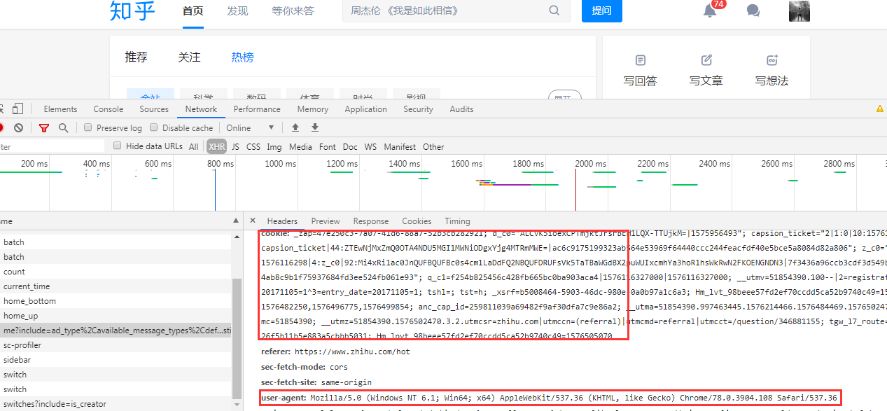
使用xpath进行页面解析,最终函数返回的结果为问题ID(即https://www.zhihu.com/question/359056618中的359056618,后面会将为何是须要返回ID而不是整个url)以及问题的标题
获取到问题的标题以及问题的ID后,咱们接下来须要获取问题下面的答案
进入问题答案详细页面,咱们发现其问题是经过ajax请求进行加载的,以下:
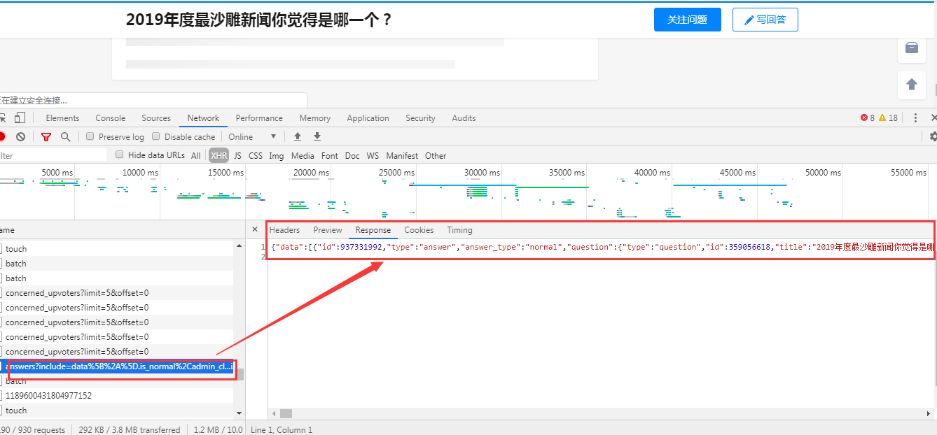 咱们发现其请求json数据的url为:
咱们发现其请求json数据的url为:
https://www.zhihu.com/api/v4/questions/359056618/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset=5&platform=desktop&sort_by=default
# 变化量如:question_id:359056618, offset=5,10,15......
其变化的量主要有问题ID以及offset参数,其中offset控制每次加载的数量
所以咱们开始实现获取答案的代码:
def data_json_request(question_id,question_title,headers):
num = 0
i = 1
while True:
json_url = 'https://www.zhihu.com/api/v4/questions/' + question_id + '/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset={}&platform=desktop&sort_by=default'.format(num)
data_json = requests.get(json_url,headers=headers)
all_detail_data = data_json.json()['data']
length_detail_data = len(all_detail_data)
for one_detail_data in all_detail_data:
question_title = question_title
answer_author = one_detail_data['author']['name']
author_introduce = one_detail_data['author']['headline']
author_followers = one_detail_data['author']['follower_count']
answer_vote_num = one_detail_data['voteup_count']
answer_comment_num = one_detail_data['comment_count']
updated_time = one_detail_data['updated_time']
content = one_detail_data['content']
# 保存数据至数据库
db = pymysql.connect(host='localhost',user='root',password='123456',port=3306,db='spider_data')
cursor = db.cursor()
sql = 'INSERT INTO zhihu_hot_question(question_title,author_name,author_introduce,author_followers,answer_vote_num,answer_comment_num,updated_time,content) VALUES(%s,%s,%s,%s,%s,%s,%s,%s)'
try:
if int(answer_vote_num) >= 90:
cursor.execute(sql,(question_title,answer_author,author_introduce,author_followers,answer_vote_num,answer_comment_num,updated_time,content))
db.commit()
print('数据写入成功!!!')
else:
print('点赞数太少,不保存至数据库!!!')
except:
print('数据写入失败!')
db.rollback()
# print(question_title,'\n',answer_author,'\n',author_introduce,'\n',author_followers,'\n',answer_vote_num,'\n',answer_comment_num
# ,'\n',updated_time,'\n',content)
num = i*5
i = i+1
if length_detail_data == 0:
print('answaer_stop!!!!!')
break
其中,咱们设定当其答案所有加载完成后,跳出循环,即:
if lenth_detail_data == 0:
print('answaer_stop!!!!!')
break
同时也将数据写入数据库的程序直接写入到获取答案的函数中,而且对于点赞数过少的不保存在数据库中(这里设置点赞数大于90进行保存)
最后编写main主函数,以下:
def main():
question_id = get_question_num(url,headers)
print(question_id)
print('当前环境CPU核数是:{}核'.format(multiprocessing.cpu_count()))
p = multiprocessing.Pool(4)
for q_id in question_id:
p.apply_async(data_json_request,args=(q_id[0],q_id[1],headers))
p.close()
p.join()
这里使用了多进程的方式进行数据的快速获取,最后运行整个程序,并统计最终耗时,以下:
if __name__ == "__main__":
start = time.time()
main()
print('总耗时:%.5f秒'% float(time.time()-start))
最后发现爬取知乎热榜总共用了552s的时间,最终数据库中的保存数据以下:
这样咱们就实现了知乎热榜问题及答案的数据获取
总结
使用了最简单的requests请求库
添加请求头的相关数据
分析网页是否使用ajax请求
爬取结果的数据保存(python操做mysql数据库)
多进程的数据快速爬取















 1622
1622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









