






本文基于 Oracle 11g版本进行演示
或许我们平时有这么一些疑问,当你想统计一个查询的总记录数时,第一时间就想到count(*)来实现,但突然又担心该表数据量大时,担心count(*)性能会很差,于是乎,我们可能会使用count(列)进行统计,那到底这两个有什么区别呢?
一、当表没有建立索引时
1、首先,我们在sqlplus执行下面这个脚本:
-- 如果存在,则删除该表
DROP TABLE TEST_TABLE;
-- 基于DBA_OBJECTS建立一张测试表,这张表是没有任何主键、外键、索引的
CREATE TABLE TEST_TABLE AS (SELECT * FROM DBA_OBJECTS);
复制代码
我们得到一个TEST_TABLE表,用于我们自己测试,该表派生于DBA_OBJECTS表,注意只有sys用户才能使用这张表,请使用sys进行登录。
2、我们执行两遍下面脚本,对比两个相应指标:
SELECT COUNT(*) FROM TEST_TABLE;
第一次:
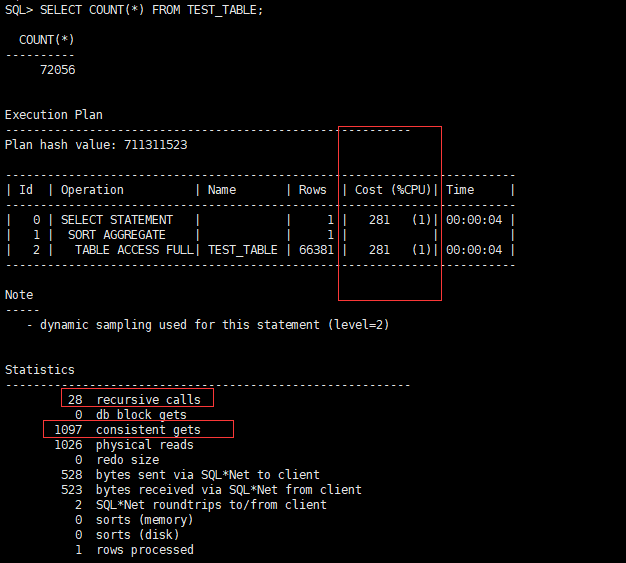
CPU开销:281,递归调用:28,一致性读:1097
第二次:
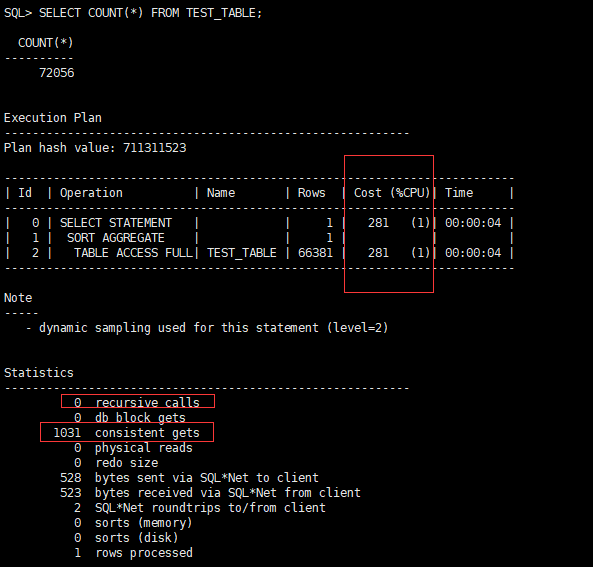
CPU开销:281,递归调用:0,一致性读:1031
这里你会发现,开销一样,但是递归调用居然变成0,一致性读也变少了很多,为什么呢?因为oracle执行完请求之后会将数据缓存到cache中,对应oracle的share pool区域
3、我们执行两遍下面脚本,对比两个相应指标:
SELECT COUNT(OBJECT_ID) FROM TEST_TABLE;
第一次:
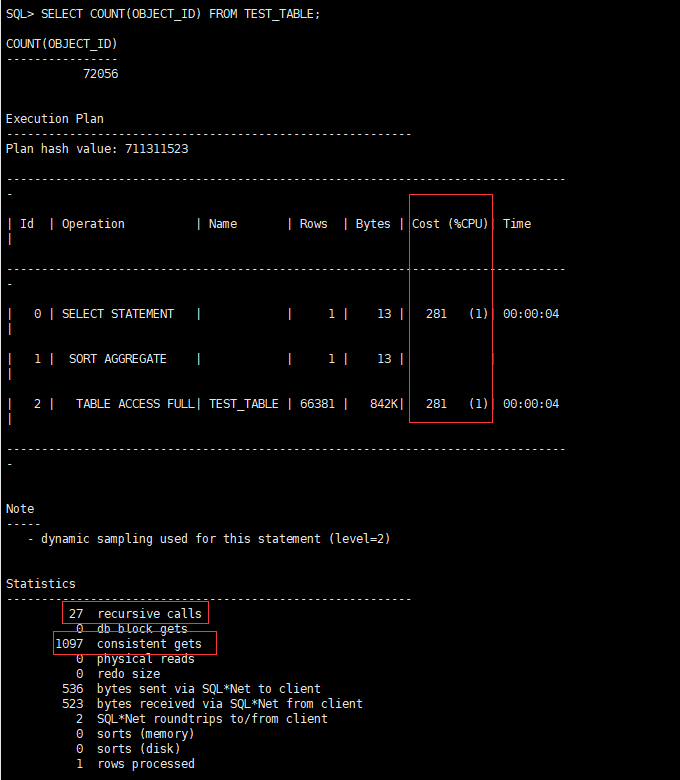
CPU开销:281,递归调用:27,一致性读:1097
第二次:
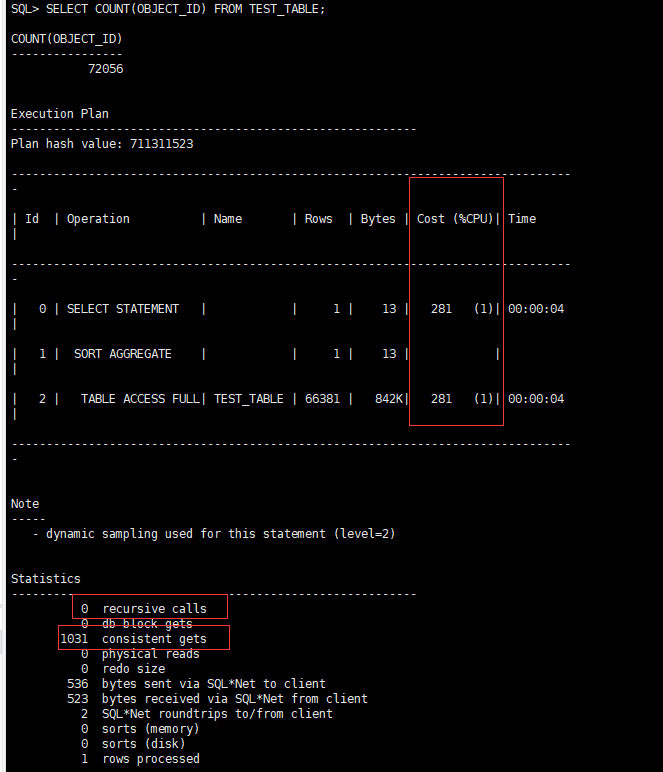
CPU开销:281,递归调用:0,一致性读:1031
你会发现,其实COUNT(*)和COUNT(OBJECT_ID)的效率是一样快的。你可能会不服气,你干嘛选OBJECT_ID作为演示,你干脆换个别的列看看,好的,下面演示别的列:
SELECT COUNT(STATUS) FROM TEST_TABLE;
第一次:
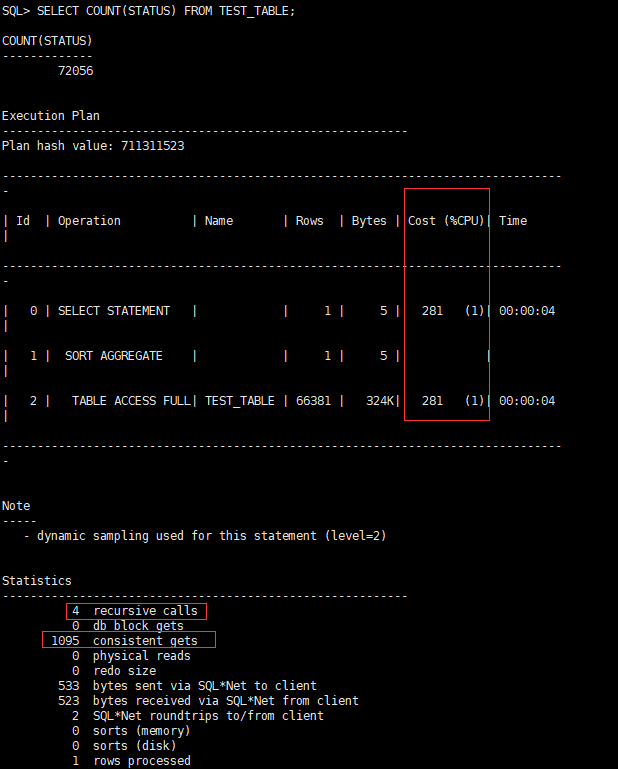
CPU开销:281,递归调用:4,一致性读:1095
第二次:
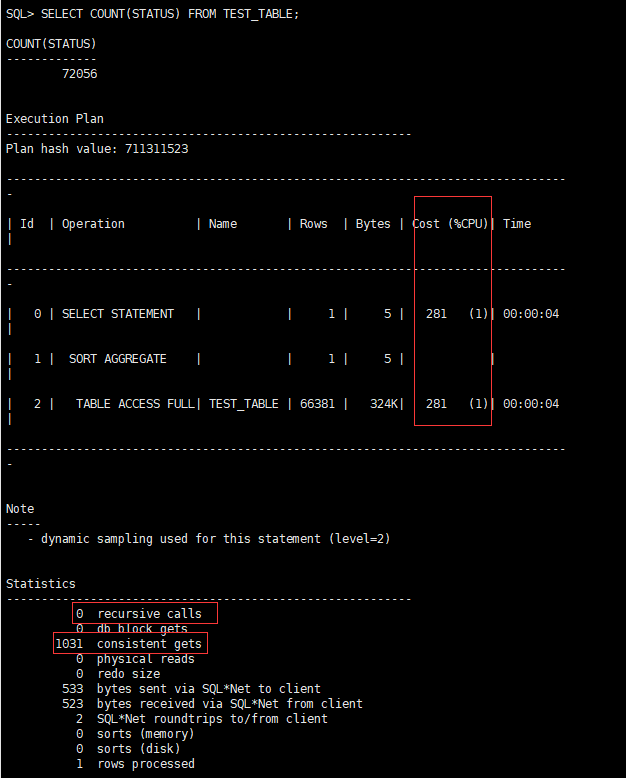
CPU开销:281,递归调用:0,一致性读:1031
结果还是1031个一致性读,一样快啊~我还是不信,你选择有很多空值的列SUBOBJECT_NAME这个列进行演示吧!好,看下面脚本:
SELECT COUNT(SUBOBJECT_NAME) FROM TEST_TABLE;
第一次:
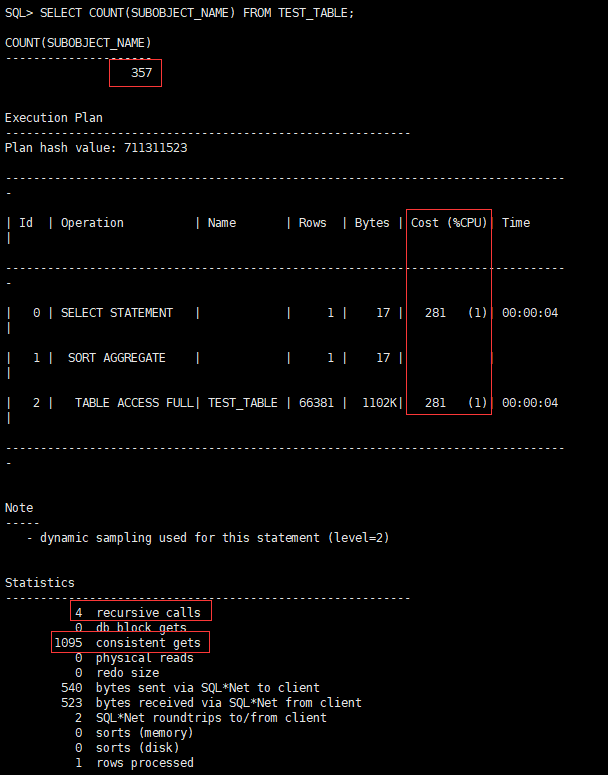
CPU开销:281,递归调用:4,一致性读:1095
第二次:
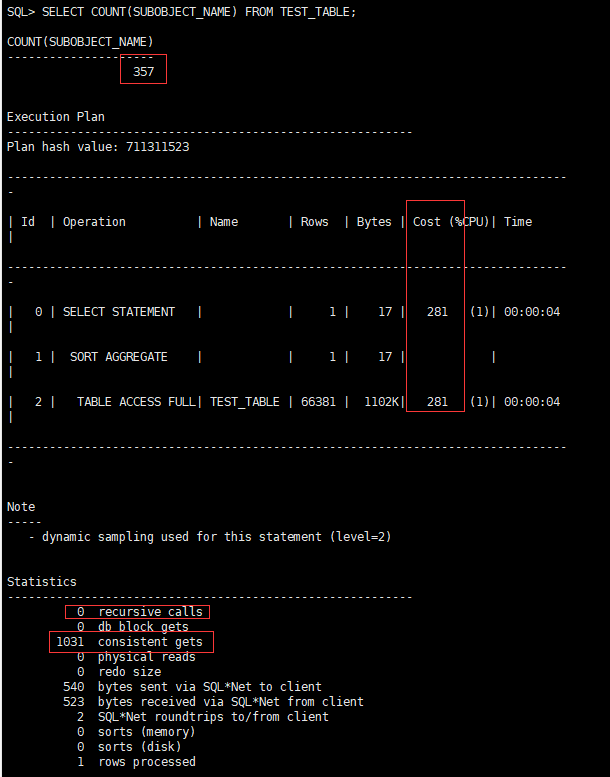
CPU开销:281,递归调用:0,一致性读:1031
是吧!还是一样,一致性读都是1031,效率是没有差别的。但是,你发现没有,最后两张图我格外圈了个小圈圈,总条数怎么变成357了呢?不应该是72056行吗?
这是由于COUNT(列)在统计时,对于该列的值若是为null,则不参加计算,这是说明,其实SELECT COUNT(*) FROM TEST_TABLE和SELECT COUNT(列) FROM TEST_TABLE是不等价的,如果你拿SELECT COUNT(列) FROM XXX去完成一个统计表记录数的需求,那GG。
二、当表建立索引时
上面实验证明了,在没有索引的前提下,COUNT(*)和COUNT(列)是没有差别的。假设我们给OBJECT_ID这个列加上一个索引会怎样,执行下面脚本:
CREATE INDEX OBJECT_ID_INDEX ON TEST_TABLE(OBJECT_ID);
然后我们再执行下面脚本:
SELECT COUNT(*) FROM TEST_TABLE;
第二遍:
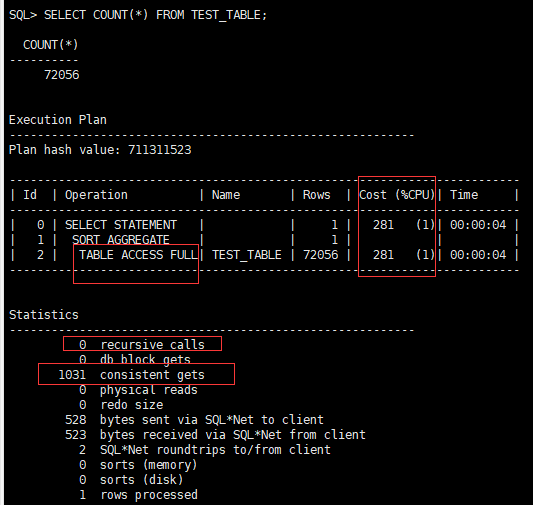
CPU开销:281,递归调用:0,一致性读:1031
从上图可以看出,即使我们建立了索引,COUNT(*)也不会走索引,反而从执行计划可以看出走了全表扫描TABLE ACCESS FULL,关于执行计划的相关内容,可阅读小编另外一篇文章【Oracle性能优化一】执行计划与索引类型分析
那么此时COUNT(OBJECT_ID)效果如何呢?执行下面脚本:
SELECT COUNT(OBJECT_ID) FROM TEST_TABLE;

CPU开销:45,递归调用:0,一致性读:168
第二遍发现CPU开销和一致性读都变少了很多,而且还走了索引扫描INDEX FAST FULL SCAN,性能确实了得。当然了,这是针对索引列的COUNT(索引列),非索引列效果如何呢?执行下面脚本:
SELECT COUNT(SUBOBJECT_NAME) FROM TEST_TABLE;
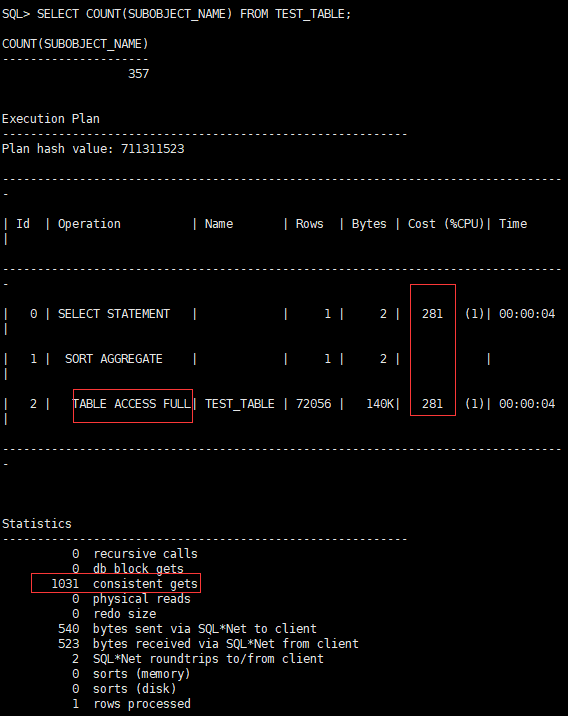
CPU开销:281,递归调用:0,一致性读:1031
发现COUNT(非索引列)没有太大变化。有个小问题,我们那个OBJECT_ID是允许为空的,假设非空会怎样呢?执行下面脚本:
ALTER TABLE TEST_TABLE MODIFY OBJECT_ID NOT NULL;
再执行COUNT(*)和COUNT(列),结果如下图:
SELECT COUNT(*) FROM TEST_TABLE;
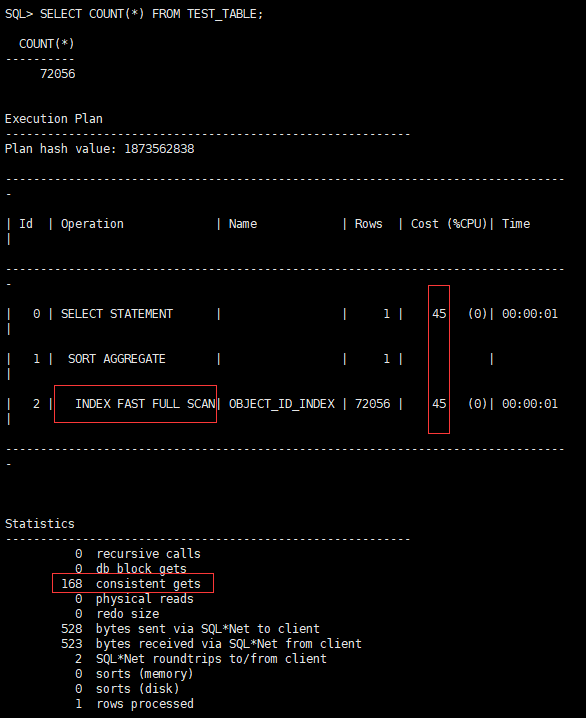
CPU开销:45,递归调用:0,一致性读:168
我们发现COUNT(*)也走索引了,性能也快了很多。
SELECT COUNT(OBJECT_ID) FROM TEST_TABLE;
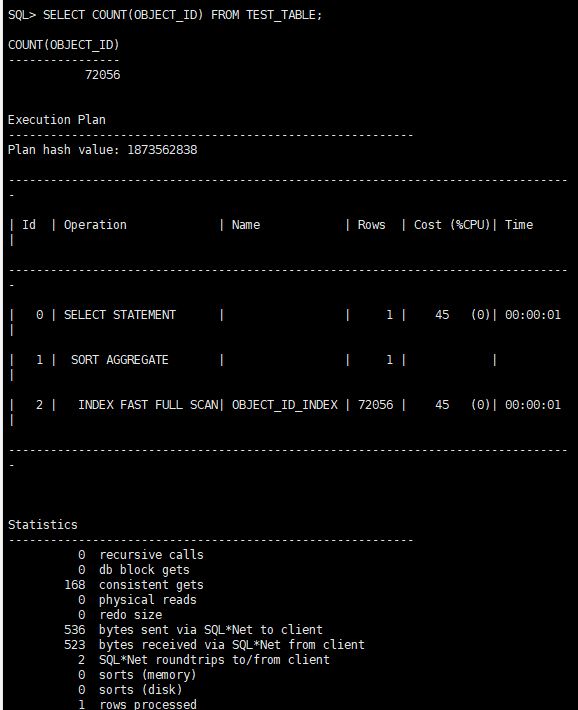
CPU开销:45,递归调用:0,一致性读:168
而COUNT(列)没有太大变化。
三、特性总结
条件
操作
结果
未建索引
COUNT(*)
全表扫描
未建索引
COUNT(列)
全表扫描
建索引(索引列可以为空)
COUNT(*)
全表扫描
建索引(索引列可以为空)
COUNT(索引列)
索引快速扫描
建索引(索引列可以为空)
COUNT(非索引列)
全表扫描
建索引(索引列不能为空)
COUNT(*)
索引快速扫描
建索引(索引列不能为空)
COUNT(索引列)
索引快速扫描
总结一句话就是,COUNT(*)在有索引且索引非空的情况下才会走索引,同时注意COUNT(*)和COUNT(列)本身是不等价的,使用前先分析业务场景。
当表有索引且索引非空时,COUNT(*)和COUNT(1)和SELECT MAX(ROWNUM) FROM XXX效果是一样的。
下面举一个例子,优化时避免回表操作,当id为非索引列,oper_time为索引列时,有如下SQL:
select count(x.id) as countnum
from iodso.A x
where x.oper_time between 1 and 2;
复制代码
上述sql会导致回表操作,由于我们只需要统计条数,此时我们可以使用count(*)反而性能更高,因为直接从索引内存就可以统计条数,不用再TABLE ACCESS BY ROWID了,不要使用Count(非索引列)的方式,所以我们要避免上述错误。














 3449
3449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









