






 点击关注 不迷路
点击关注 不迷路

学习爬虫的优势及必要性

Python爬虫是模拟浏览器打开网页,获取网页中需要的部分数据。
学习Python爬虫不仅充满趣味性,并垫基Python编程语言功底。可以说是入门IT行业的一条捷径,达到娱乐、学习二合一。喜欢看小说,搞笑图片?找工作还在一条一条筛选企业需求!做运营,做数据分析没有参考数据!业余时间想接个爬虫小需求挣个“零花钱”,爬虫帮你快速搞定。
Python爬虫被公认为是易学习、易上手、充满趣味性,其中本系列文章会包含理论知识+示图代码、案例+内容总结,如果大家对其中哪些知识点想要加深了解可以在评论区留言。
学习Python爬虫必须得用Python软件,anaconda自己带有python的编译器,其中集成了很多Python库。配置和安装很方便。非常适合入门学习。
01
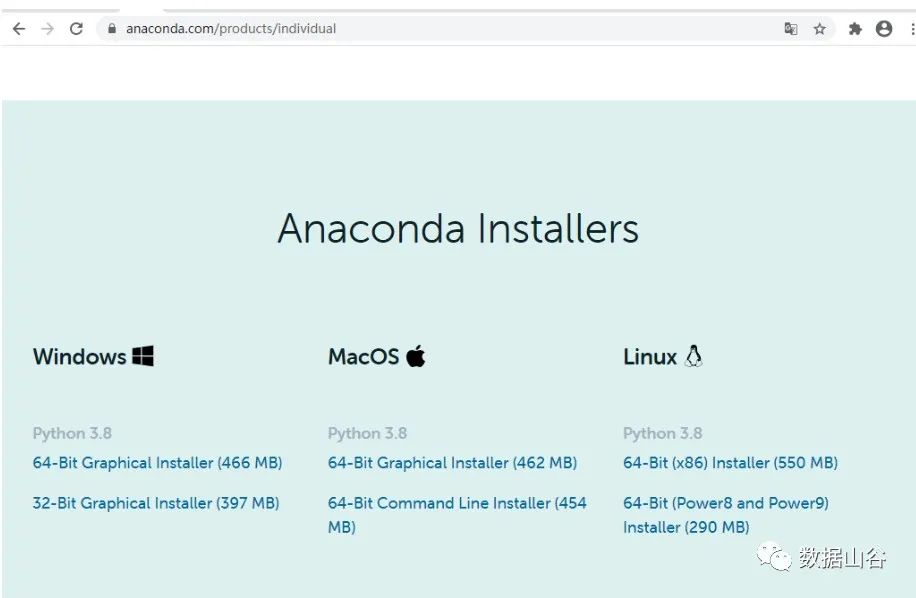
anaconda软件下载及安装
anaconda软件安装官网地址:https://www.anaconda.com/products/individual
Python基础知识和anaconda软件安装教程可参考本公众号安装配置文章,链接如下。
anaconda安装
大斌哥,公众号:数据山谷Python之Anaconda安装
02
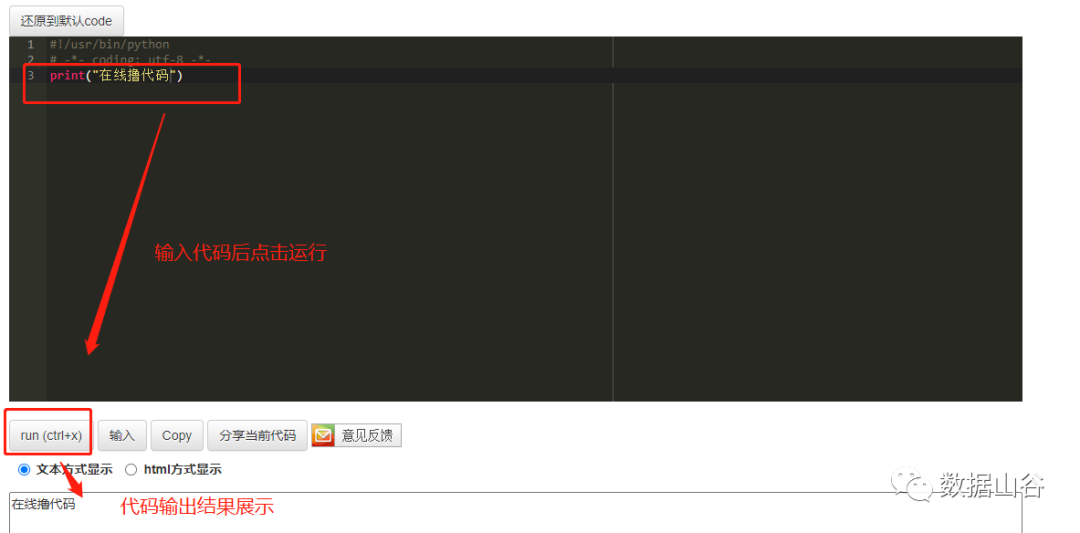
Python在线编译器推荐
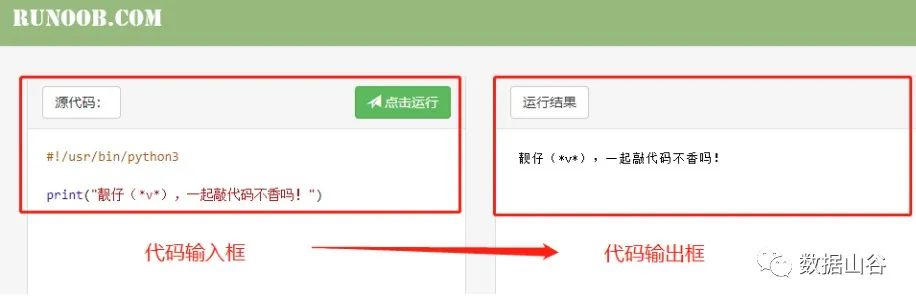
如果可利用空余时间,办公不方便,推荐两个在线撸代码Python3.0浏览器链接。
https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3
http://www.dooccn.com/python3/
03
爬虫基本原理
准备好我们的“利器”工具,现在就要传授“功法秘籍”了,什么是爬虫呢,爬虫是如何爬取数据?爬虫的基本原理是什么?
网络爬虫(Web Spider)是一种按照一定的规则请求网站,自动地抓取数据信息的程序或者脚本。
04
基本原理--requests发起请求
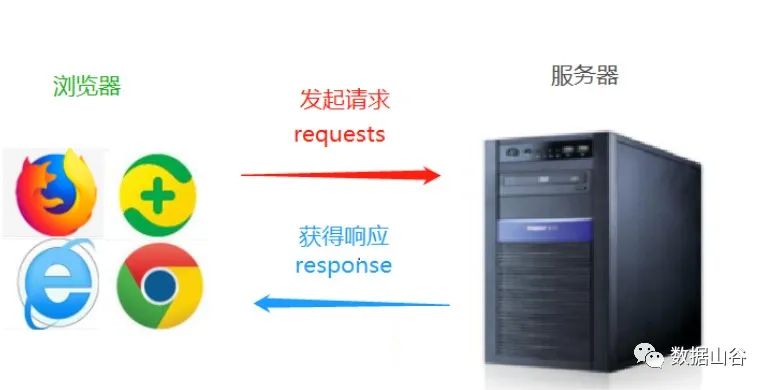
通过HTTP库目标站点发起请求,即发送一个request,请求可以包含额外的headers等信息,等待服务器响应。
我们打开一个网站链接时,过程是从客户端(例如:谷歌、火狐浏览器)发送请求到服务端(例如:你打开百度网站所在的服务器),服务器接收到了请求,处理,返回给客户端(浏览器),然后在浏览器上看到了展示的数据。
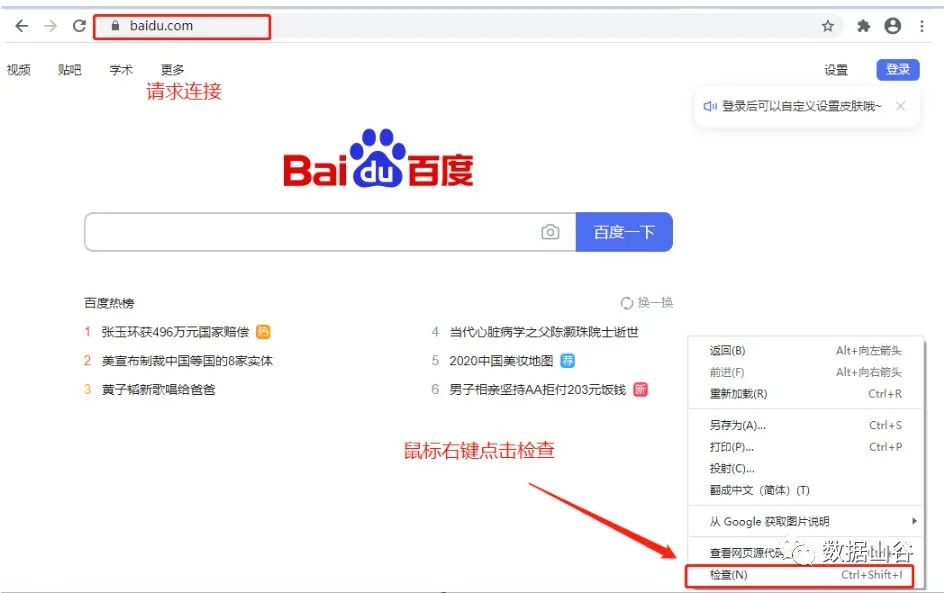
其中Elements为查找网页源代码,实时编辑DOM节点和CSS样式,Network从发起网页页面请求request后,分析HTTP请求得到的各个请求资源信息。Network中的参数值为我们本篇学习的主要内容。
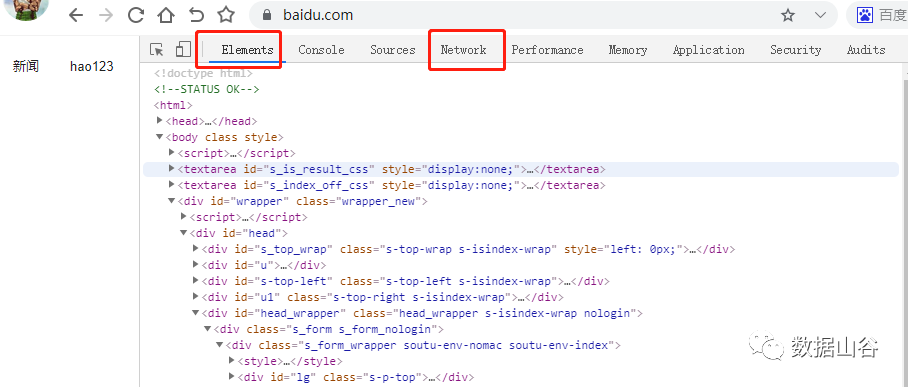
Network相关参数如下:
Header:列出HTTP头信息,包括请求url、HTTP方法、响应状态码【例如:200,,404等】、请求头和响应头及各自的值、请求参数等。
Preview:预览面板,据你所选择的资源类型【JSON、图片、文本】显示相应的预览。
Response:显示HTTP的Response响应信息,包含资源还未进行格式处理的内容。
Cookie:显示资源HTTP的Request和Response过程中的Cookies信息。
Timing:资源请求的详细信息花费时间。
05
基本原理--requests请求方法
request是指请求,在浏览器输入链接地址,点击搜索【或按回车键】,就是发送一个请求。
请求方式主要有Get、Post两种类型,还有Head、Put、Delete、Options等,因为爬虫最常用的为Post和Get方法,其他方法几乎不涉及,所以进行简单介绍。
Get用于数据的读取,请求指定的页面信息。是发送一个请求或者服务器的某种资源,通过一组HTTP请求头和呈现数据(例如:HTML文本、图、视频等)返回给客户端;
Post是向服务器提交数据。目前几乎所有的提交数据操作都是Post请求完成;
Head仅返回HTTP请求头信息给客户端;
Put和Post极为相似,都是向服务器发送数据,PUT通常指定了资源的存放位置,POST的数据存放位置由服务器自己决定 ;
Delete指删除某一个资源;
Options请求是用于客户端查看服务器的性能;
requests请求示例:
# requests请求时url地址可以直接指定为链接地址requests.get(url='https://www.baidu.com/s?ie=utf-8&wd=秃头少女25')06
基本原理--URL遵循的标准格式
请求的URL【uniform/universal resource identifier】是全称统一资源定位符,URL主要用于两种目的,命名资源和提供资源的路径或位置,此时叫做统一资源定位符,例如一个网页的文档、图片、视频都可以用URL来指定。
其中 HTTP协议:http://或者https://;服务器的链接地址例如:
http//baidu.com浏览器中搜索秃头少女25,URL链接地址发生改变,链接中s?ie=utf-8&wd=秃头少女25是指定【utf-8】编码,【秃头少女25】为你指定搜索的关键字。
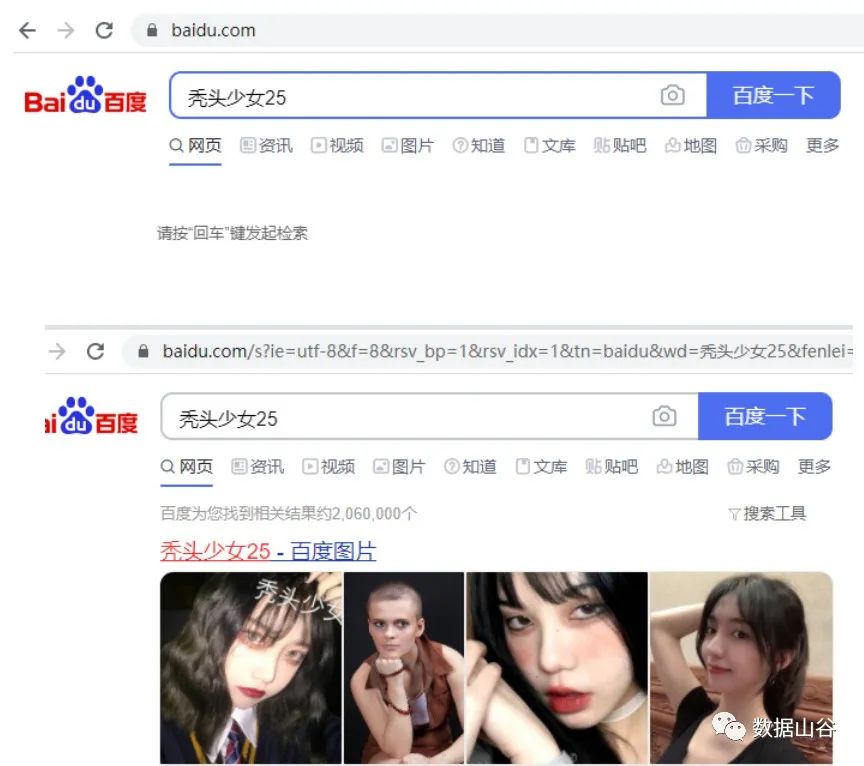
指定URL地址如下:
url = "https://www.baidu.com/s?ie=utf-8&wd=秃头少女25"07
基本原理--requests请求头
请求头是指请求时的头部信息,如User-Agent、host、Cookies等信息。请求体是指请求时额外携带的数据,如表单提交时的表单数据。很多网站在申请访问的时候没有请求头无法访问,或者返回乱码,简单的解决方式就是伪装成浏览器进行访问,如添加一个请求头伪装浏览器行为。
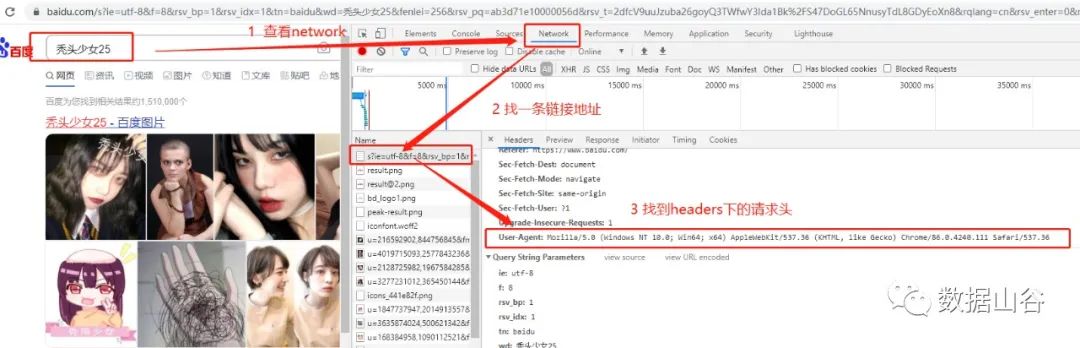
requests请求头示例:
# 定义请求头headers为字典类型headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}08
基本原理--response获取响应内容
如果服务器能够正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能 有HTML,Json字符串,二进制数据(如图片视频)等类型。
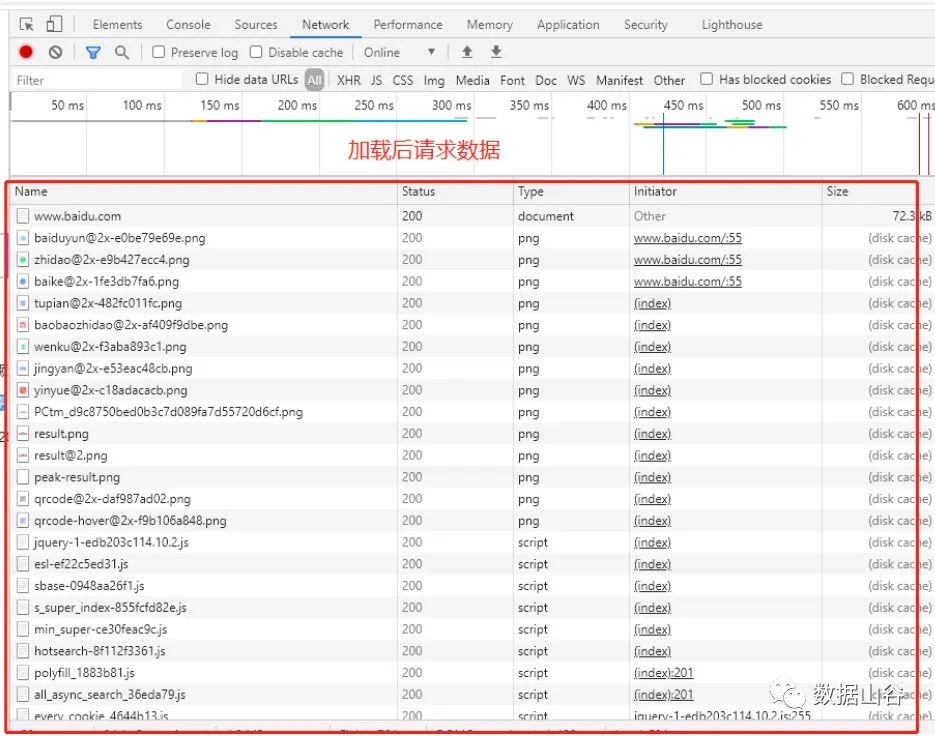
接下来让我们把请求、请求头和返回相结合,完成一个简单的请求响应。
09
基础原理--请求响应示例
首先需要安装导入Python中的网络请求requests模块【该模块需要使用pip install requests在终端中安装】。
找到访问链接中的请求头并定义为字典,使用Get请求方法,传入链接地址和请求头获取响应内容。其中response返回的结果为访问状态如:,response.text返回的是整个文本内容。
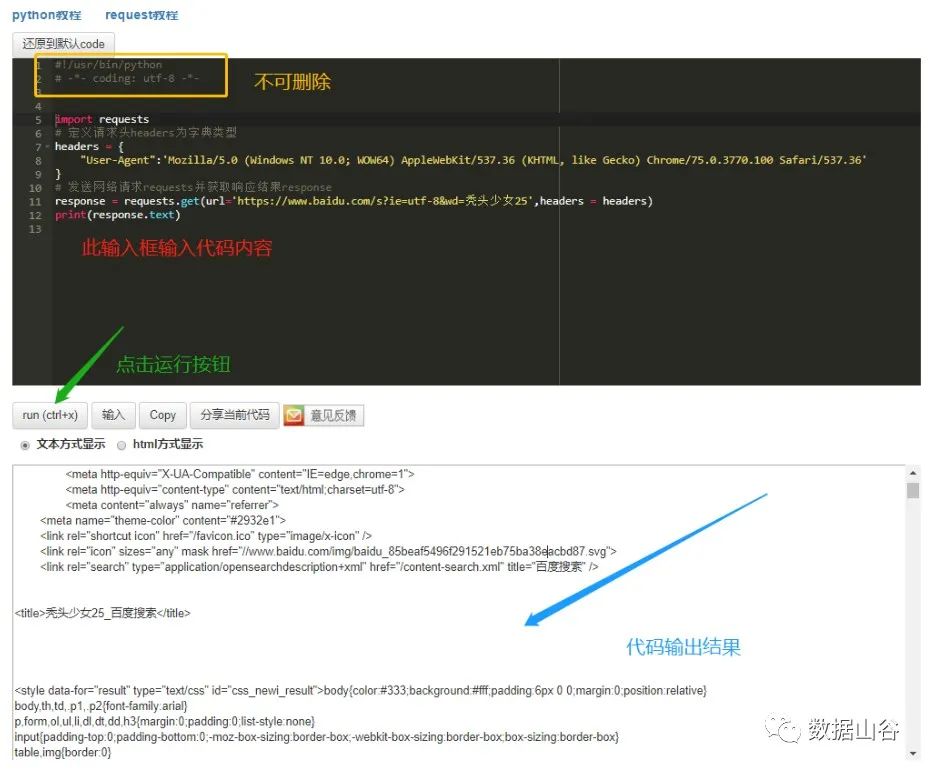
代码示例如下:
import requests# 定义请求头headers为字典类型headers = { "User-Agent":'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}# 发送网络请求requests并获取响应结果responseresponse = requests.get(url='https://www.baidu.com/s?ie=utf-8&wd=秃头少女25',headers = headers)# 打印response会输出返回状态,打印response.text会输出网页文本print(response.text)使用Python在线编辑器操作展示如下:
10
基础原理--知识关键字总结
requests(发起请求)、response(获取响应)、get (数据读取,请求指定的页面信息)、post(是向服务器提交数据)、url(统一资源定位符,指定网页的文档、图片、视频),hearders(请求时的头部信息)。

下一篇讲解【爬虫遵守协议及解析内容、保存数据】。关注微信号,每天练习一点点,学习爬虫不迷路,今天你又学“废” 了吗?
点分享

点收藏

点点赞

点在看





扫码关注我们














 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









