






出于某些原因,想调戏下天猫的反爬虫机制,于是就有了这篇记录
源码已传osgit ,感兴趣可以戳下
正文开始
分析目标(items) 解析路径(xpath)
目标为天猫超市的进口商品区
研究一下待抓取网页中, 需要爬的内容,如下图
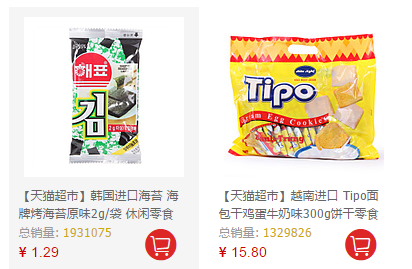
我的目标是 商品名、销量、价格,图当然也是可以爬的,不过本次不爬

新建爬虫【处理items,pipelines,settings,spider】
首先新建一个爬虫,起个喜欢或者任性的名字
scrapy startproject tmail
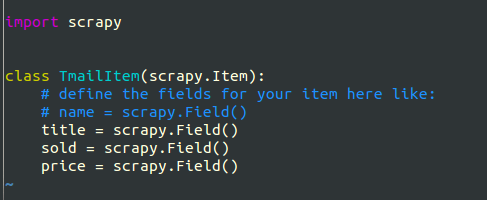
更改下级目录中的 **items.py **
我依据网站上的起名添加了 titile,sold(sum是保留字),price
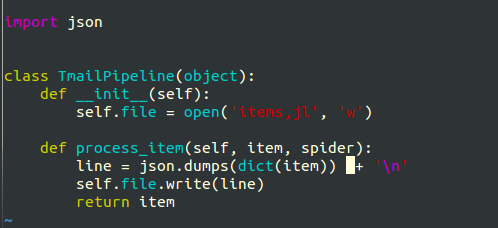
更改pipelines.py和settings.py中的内容(当然也可以先创小蜘蛛啦)
因为爬的都是字符,就直接保存为json文件(下图为初版,后遇到问题有更改)
在setting.py中添加download_delay和 item_pipelines
DOWNLOAD_DELAY = 3
ITEM_PIPELINES = {
'tmail.pipelines.TmailPipeline' : 300,
}
事实上我还加了COOKIES_ENABLED = False,后来证明。。是傻,见后文
接下来就是愉快得整蜘蛛了
在spiders文件夹中新建一个xxx.py (我的是tmailspider.py),打开之
加 name(运行爬虫时用) ,allowed_domains (域名),
start_url(必需吐槽下天猫的后缀在下个菜鸡看不懂,并且用虚拟机开的不一样,不过都能用就是了,我的 在图中隐藏了部分,各位喜欢自己开个就好)
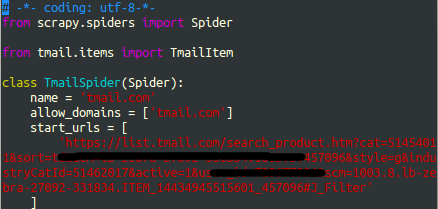
分析目标xpath,加parse方法 下图为最初版
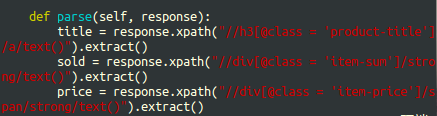
试运行,处理bug【robots.txt,更改useragent(无用),重定向302错误】
嗯 接下来 我就运行了 scrapy crawl tmail.com
结果如图 我被robots.txt文件挡住了
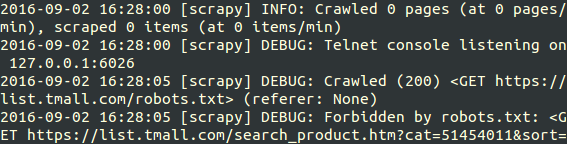
看来不能优雅了,第一次更改 settings.py 中 加/改 ROBOTSTXT_OBEY = False
改完后,来我们看看结果
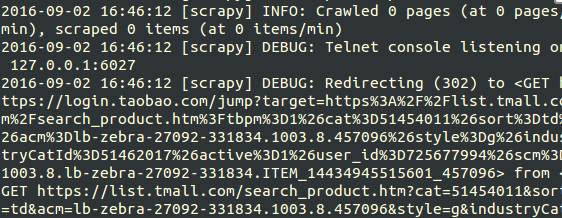
重定向302??这是什么鬼 ?看出我是用爬虫了 ?
没事,前两天才学了改请求头,我加个变化的useragent试试 (这个可以看看我的上一篇博客)
改useragent
然并卵,它报同样!的!错!
好吧,老实上网搜,
分析cookies
网上并没有详细方法,只有几个朋友提供的分析cookies的思路
然而我并不会,于是就找到一篇对我接下来的修改起很大作用的文章 Scrapy用Cookie实现模拟登录
方法如下:
登录了自己的天猫,用ctrl + shift + i 快捷键打开工具,在network下找到需要的cookie(真 好长一串)
拿到cookie后需要处理成``` 'xxx' : 'xxxx',
2. 重载spider内方法start_requests(注意:此时start_urls已废,我保留它仅为了保存原网址)

3. 中间是很长的cookies,因为start_urls没有默认功能了,所以要重新加上调用方法parse

4. (自作孽之)记得把settings.py中的 COOKIES_ENABLED = False 改为
COOKIES_ENABLED = True //默认为True
到此就可以正常爬取了,还有最后一个问题 输出中文乱码
### 解决中文乱码
这个我算是暴力解决了,在 tmailspider.py和pipelines.py 中加入
import sys reload(sys) sys.setdefaultencoding('utf-8')
然后输出变为unicode,于是在pipeline里加了
line.decode('unicode-escape')
### 收尾工作(输出好看点以及实现爬取下一页)
由于单网页有多个item,于是我改写了爬虫的parse函数,可以单个输出,下图为改善版

上面所完成的爬虫只能爬单个网页,那怎么够,于是又去分析网页内地址

可以看出网址很烦,一开始想用正则来表达网址,结果嫌麻烦放弃了,我看中了上图最后一条,下一页的网址,哈哈,用xpath分析获得很容易,于是最终版的parse函数如下
















 1620
1620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









