







对于二分类问题, 当训练集中正负样本非常不均衡时, 如何处理数据以更好地训练分类模型?
这里有个问题是:如何判断数据是否平衡呢?w(゚Д゚)w
real world data经常会面临class imbalance问题,即正负样本比例失衡。根据计算公式可以推知,在testing set出现imbalance时ROC曲线能保持不变,而PR则会出现大变化。
- 基于数据的方法
- 基于算法的方法
基于数据的方法
- 对数据进行重采样, 使原本不均衡的样本变得均衡。 首先, 记样本数大的类别为Cmaj, 样本数小的类别为Cmin, 它们对应的样本集分别为Smaj和Smin。 根据题设, 有|Smaj|>>|Smin。最简单的处理不均衡样本集的方法是随机采样。 采样一般分为过采样( Oversampling) 和欠采样( Under-sampling) 。 随机过采样是从少数类样本集Smin中随机重复抽取样本( 有放回) 以得到更多样本; 随机欠采样则相反, 从多数类样本集Smaj中随机选取较少的样本( 有放回或无放回) 。
直接的随机采样虽然可以使样本集变得均衡, 但会带来一些问题, 比如, 过采样对少数类样本进行了多次复制, 扩大了数据规模, 增加了模型训练的复杂度, 同时也容易造成过拟合; 欠采样会丢弃一些样本, 可能会损失部分有用信息, 造成模型只学到了整体模式的一部分。
- 为了解决上述问题, 通常在过采样时并不是简单地复制样本, 而是采用一些方法生成新的样本。 例如, SMOTE算法对少数类样本集Smin中每个样本x, 从它在Smin中的K近邻中随机选一个样本y, 然后在x,y连线上随机选取一点作为新合成的样本( 根据需要的过采样倍率重复上述过程若干次) , 如图8.14所示。 这种合成新样本的过采样方法可以降低过拟合的风险。
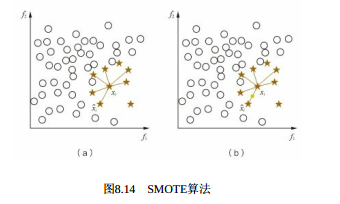
SMOTE算法为每个少数类样本合成相同数量的新样本, 这可能会增大类间重叠度, 并且会生成一些不能提供有益信息的样本。 为此出现Borderline-SMOTE、ADASYN等改进算法。 Borderline-SMOTE只给那些处在分类边界上的少数类样本合成新样本, 而ADASYN则给不同的少数类样本合成不同个数的新样本。 此外,还可以采用一些数据清理方法( 如基于Tomek Links) 来进一步降低合成样本带来的类间重叠, 以得到更加良定义( well-defined) 的类簇, 从而更好地训练分类器。
- 同样地, 对于欠采样, 可以采用Informed Undersampling来解决由于随机欠采样带来的数据丢失问题。 常见的Informed Undersampling算法有:
- Easy Ensemble算法。 每次从多数类Smaj中上随机抽取一个子集E(|E|≈|Smin|),然后用E+Smin训练一个分类器; 重复上述过程若干次,得到多个分类器,最终的分类结果是这多个分类器结果的融合。
- Balance Cascade算法。 级联结构, 在每一级中从多数类Smaj中随机抽取子集E, 用E+Smin训练该级的分类器; 然后将Smaj中能够被当前分类器正确判别的样本剔除掉, 继续下一级的操作, 重复若干次得到级联结构; 最终的输出结果也是各级分类器结果的融合。
- 其他诸如NearMiss(利用K近邻信息挑选具有代表性的样本) 、 Onesided Selection(采用数据清理技术) 等算法。在实际应用中, 具体的采样操作可能并不总是如上述几个算法一样, 但基本思路很多时候还是一致的。 例如, 基于聚类的采样方法, 利用数据的类簇信息来指导过采样/欠采样操作; 经常用到的数据扩充方法也是一种过采样, 对少数类样本进行一些噪声扰动或变换(如图像数据集中对图片进行裁剪、 翻转、 旋转、 加光照等) 以构造出新的样本; 而Hard Negative Mining则是一种欠采样, 把比较难的样本抽出来用于迭代分类器。
基于算法的方法
在样本不均衡时, 也可以通过改变模型训练时的目标函数(如代价敏感学习中不同类别有不同的权重) 来矫正这种不平衡性; 当样本数目极其不均衡时, 也可以将问题转化为单类学习( one-class learning) 、 异常检测( anomaly detection) 。
Abnormal Detection(异常检测)和 Supervised Learning(有监督训练)在异常检测上的应用初探
如何选择
(1)在正负样本都非常少的情况下,应该采用数据合成的方式,例如:SMOTE算法和Borderline-SMOTE算法。
(2)在正负样本都足够多且比例不是特别悬殊的情况下,应该考虑采样的方法或者是加权的方法。
- 1.通过过抽样和欠抽样解决样本不均衡
抽样是解决样本分布不均衡相对简单且常用的方法,包括过抽样和欠抽样两种。
过抽样
过抽样(也叫上采样、over-sampling)方法通过增加分类中少数类样本的数量来实现样本均衡,最直接的方法是简单复制少数类样本形成多条记录,这种方法的缺点是如果样本特征少而可能导致过拟合的问题;经过改进的过抽样方法通过在少数类中加入随机噪声、干扰数据或通过一定规则产生新的合成样本,例如SMOTE算法。
欠抽样
欠抽样(也叫下采样、under-sampling)方法通过减少分类中多数类样本的样本数量来实现样本均衡,最直接的方法是随机地去掉一些多数类样本来减小多数类的规模,缺点是会丢失多数类样本中的一些重要信息。
总体上,过抽样和欠抽样更适合大数据分布不均衡的情况,尤其是第一种(过抽样)方法应用更加广泛。
- 2.通过组合/集成方法解决样本不均衡
组合/集成方法指的是在每次生成训练集时使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,这样反复多次会得到很多训练集和训练模型。最后在应用时,使用组合方法(例如投票、加权投票等)产生分类预测结果。
例如,在数据集中的正、负例的样本分别为100和10000条,比例为1:100。此时可以将负例样本(类别中的大量样本集)随机分为100份(当然也可以分更多),每份100条数据;然后每次形成训练集时使用所有的正样本(100条)和随机抽取的负样本(100条)形成新的数据集。如此反复可以得到100个训练集和对应的训练模型。
这种解决问题的思路类似于随机森林。在随机森林中,虽然每个小决策树的分类能力很弱,但是通过大量的“小树”组合形成的“森林”具有良好的模型预测能力。
如果计算资源充足,并且对于模型的时效性要求不高的话,这种方法比较合适。
3.通过特征选择解决样本不均衡
上述几种方法都是基于数据行的操作,通过多种途径来使得不同类别的样本数据行记录均衡。除此以外,还可以考虑使用或辅助于基于列的特征选择方法。
一般情况下,样本不均衡也会导致特征分布不均衡,但如果小类别样本量具有一定的规模,那么意味着其特征值的分布较为均匀,可通过选择具有显著型的特征配合参与解决样本不均衡问题,也能在一定程度上提高模型效果。
参考:














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









