






 本文档详细介绍了Apache ShardingSphere元数据中心(MetadataCenter)的设计,包括元数据的定义、类型、加载流程、变更方式以及未来优化方向。通过元数据中心,旨在解决元数据加载性能不高和节点间元数据同步的问题,实现统一管理和数据同步机制。
本文档详细介绍了Apache ShardingSphere元数据中心(MetadataCenter)的设计,包括元数据的定义、类型、加载流程、变更方式以及未来优化方向。通过元数据中心,旨在解决元数据加载性能不高和节点间元数据同步的问题,实现统一管理和数据同步机制。

元数据中心设计(MetadataCenter)
[TOC]
本文档旨在说明Apache ShardingSphere治理模块的元数据中心(MetadataCenter)设计。英文版本:
https://github.com/apache/incubator-shardingsphere/issues/4896github.com1、元数据的定义
本文所指的元数据(Metadata)为Sharding-JDBC/Sharding-Proxy所使用的数据源的metadata。这些元数据是保障ShardingSphere的各个组件正确运行的核心数据对象,目前散落在系统的各个使用部分,需要使用元数据中心的方式统一的组织和管理,并在元数据发生变化时协调变更。
2、元数据的类型
目前的元数据对象模型主要定义在:
org.apache.shardingsphere.sql.parser.binder
├─column
│ ColumnMetaData.java
│ ColumnMetaDataLoader.java
├─index
│ IndexMetaData.java
│ IndexMetaDataLoader.java
├─schema
│ SchemaMetaData.java
│ SchemaMetaDataLoader.java
└─table
TableMetaData.java
TableMetaDataLoader.java
关系为schema > table > column+index
同时,scaling模块也有一套模型和loader,需要合并(杨翊正在处理)。
一个需要讨论的问题是:
问题1: sharding-rule等,要不要也统一放到metadata center?
建议本次只处理ds的metadata,rule数据先放在config center不动。后续再看要不要调整。
3、当前的加载流程
加载元数据的统一入口为:
org.apache.shardingsphere.sql.parser.binder.metadata.schema.SchemaMetaDataLoader
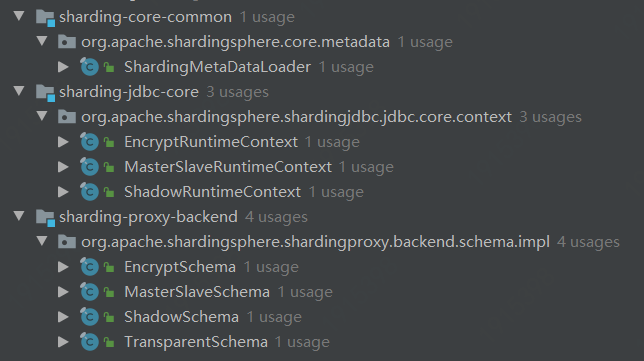
三处会加载元数据:
1、Sharding-JDBC
2、Sharding-Proxy
Bootstrap.startWithRegistryCenter->LogicSchemas.init/initSchemas
-> LogicSchemas.initSchemas(for) ->LogicSchemaFactory.newInstance
->XXSchema->XXSchema.createMetaData/loadSchemaMetaData
->SchemaMetaDataLoader.load(dataSource, maxConnectionsSizePerQuery)
各个XXSchema实现了guava的@Subscribe的renew方法,可以在接收到event时执行刷新对应的rule,Sharding和MasterSlave可以额外支持disable实践,禁用掉数据源。(这一块有大量重复代码,可以优化)
分表的元数据加载:
org.apache.shardingsphere.core.metadata.ShardingMetaDataLoader
分开加载logic部分和default部分。
然后调用SchemaMetaDataLoader,按照层级加载。
3、Sharding-scaling
自定义了一套TableMetaDataLoader和ColumnMetaDataLoader,用来加载TableMetaData和ColumnMetaData。
4、现有的使用场景(todo)
**路由模块**
- 如果是SelectStatementContext,存在where条件,会参与到获取ShadingConditions
- 如果是DDLStatement,DCLStatement,会从中,获取表的数据.
**重写模块**
- 判断该列是否存在元数据中
- EncryptPredicateParameterRewriter
- EncryptPredicateColumnTokenGenerator
- EncryptPredicateRightValueTokenGenerator
**执行模块**
- 如果是以下几种类型会刷新metaData.
if (sqlStatementContext instanceof CreateTableStatementContext) {
refreshTableMetaData(runtimeContext, ((CreateTableStatementContext) sqlStatementContext).getSqlStatement());
} else if (sqlStatementContext instanceof AlterTableStatementContext) {
refreshTableMetaData(runtimeContext, ((AlterTableStatementContext) sqlStatementContext).getSqlStatement());
} else if (sqlStatementContext instanceof DropTableStatementContext) {
refreshTableMetaData(runtimeContext, ((DropTableStatementContext) sqlStatementContext).getSqlStatement());
} else if (sqlStatementContext instanceof CreateIndexStatementContext) {
refreshTableMetaData(runtimeContext, ((CreateIndexStatementContext) sqlStatementContext).getSqlStatement());
} else if (sqlStatementContext instanceof DropIndexStatementContext) {
refreshTableMetaData(runtimeContext, ((DropIndexStatementContext) sqlStatementContext).getSqlStatement());
}**归并模块**
- 暂时没有用到,直接使用sql返回ResultSet中的MetaData
5、现有的变更方式
目前,元数据由各个启动的Sharding-JDBC或Proxy节点自行加载和管理。
如果通过一个节点执行了DDL,则会直接调用如下刷新方法,刷新当前节点的元数据。
JDBC:
org.apache.shardingsphere.shardingjdbc.executor.AbstractStatementExecutor.refreshMetaDataIfNeeded
Proxy:
org.apache.shardingsphere.shardingproxy.backend.schema.impl.ShardingSchema.refreshTableMetaData
这两个地方的代码也大量重复。
6、元数据中心设计
通过上面的分析,我们知道存在一些需要改进的地方:
1)如果有多个节点同时启动,会大量重复从DB加载元数据,加载性能不高;
2)某个节点执行了DDL,其他节点并不知道元数据已经发生了改变。
我们希望通过元数据中心设计解决这2个问题。
6.1 定义
元数据中心是通过统一管理所有元数据,实现元数据的统一加载、变更通知和数据同步的机制。
6.2 功能
计划通过梳理现有的元数据加载和使用的场景,统一控制首次加载元数据后,持久化到CenterRepository,后续的节点启动,通过元数据中心获取元数据(改进1)。当某个节点执行了DDL操作,刷新本节点元数据后同步到CenterRepository,并通知到其他所有的节点,从元数据中心同步新数据(改进2)。
6.3 API
在梳理清楚的基础上,重构现有元数据加载逻辑,部分loader代码迁移到元数据中心模块,新增:
sharding-orchestration-center-metadata
以及如下API:
1. MetadataCenter
2. MetadataLoader
3. MetadataNode
4. MetadataListener
5. MetadataChangeEvent
6.4 数据结构
分析元数据内存结构如下:
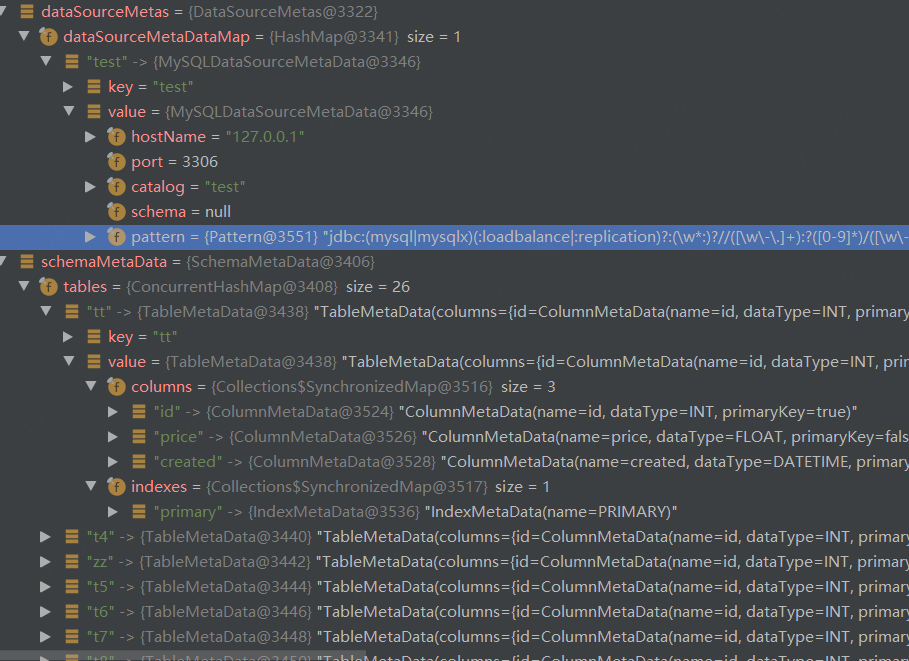
CenterRepository中元数据结构-配置方式1:
>
> ├─orchestration-namespace
> ├─orchestration-name
> │ ├─metadata
> │ │ ├─ip1:port/catalog/schema
> │ │ │ ├─table1
> │ │ │ │ ├─columns
> │ │ │ │ └─indexs
> │ │ │ ├─table2
> │ │ │ │ ├─columns
> │ │ │ │ └─indexs
> │ │ ├─ip2:port/catalog/schema
> │ │ │ ├─table3
> │ │ │ │ ├─columns
> │ │ │ │ └─indexs
> │ │ │ ├─table4
> │ │ │ │ ├─columns
> │ │ │ │ └─indexs
>
元数据结构-配置方式2:
>
> ├─orchestration-namespace
> ├─orchestration-name
> │ ├─metadata
> │ │ ├─ip1:port/catalog/schema
> │ │ │ ├─ [json/yaml text contents]
>
方式1:在于直观和细粒度。
方式2:在于更简单和好控制。(前期建议先用方式2)
一个问题:
问题2:logic table是否要在这里展现?
可以先不展现,只存实际的real tables
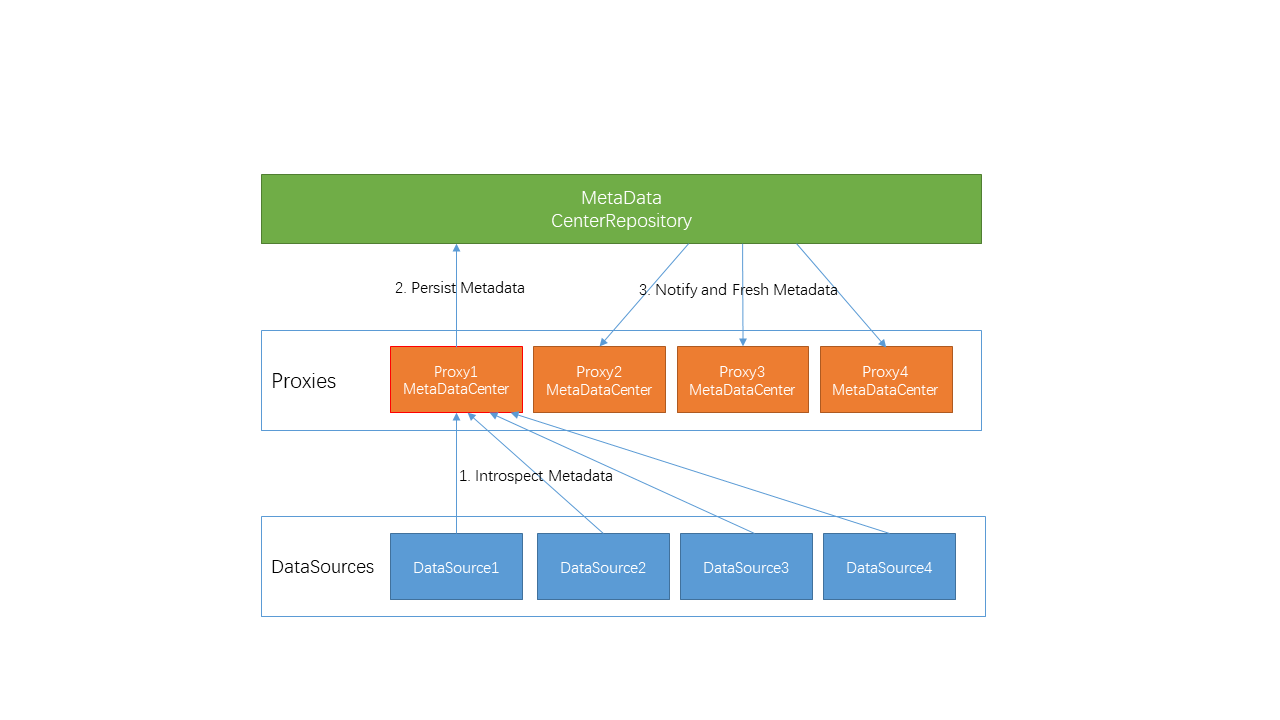
6.5 加载流程
现有流程:
先加载sharding tables,然后加载default tables,按照check.metadata.enable参数是不是check所有表的元数据。
修改为:
加载完元数据,写入到CenterRepository,然后触发全局通知。
问题3:是否在每一个group或者ds加载完,写本步骤的元数据到CenterRepository,还是全部加载完一起写(关系到触发一个或多个事件)。
可以考虑先全量同步,再根据加载速度等效果看,要不要分批持久化和通知。
6.6 同步流程
执行DDL后,通过Event机制刷新本节点的元数据,并同步给CenterRepository,然后触发全局变更通知。
问题4:是否要hold其他节点的加载过程,防止并发。
先不考虑并发, 实现功能,最后再解决这个问题,涉及到分布式锁。
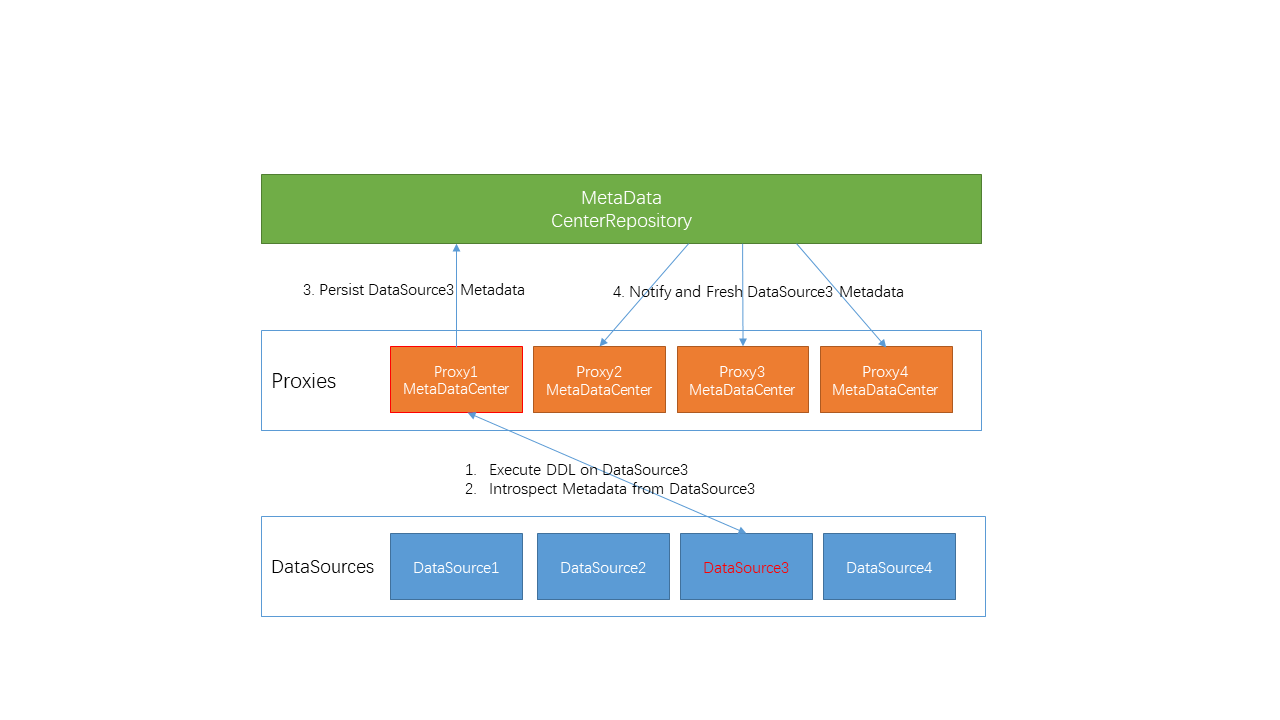
6.7 变更更新流程
通过Event机制,通知其他节点并更和通知。
7、任务列表
7.1 metadata梳理
7.2 metadata重构(代码抽象和清理)
7.3 添加center-metadata相关项目结构
7.4 实现metadata持久化
7.5 移植部分loader代码
7.6 实现事件通知机制
7.7 实现全局同步机制
7.8 优化加载和使用方式
7.9 完善UT
7.10 实现examples
7.11 撰写documents

















 2794
2794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









