






distinct的去重复的提前是表中所有列的数据完成相同时,才能把相同的数据只保留一条,并不是 distinct 列名,除去某一列相同的数据,并且 distinct要放在第一个列前面。案例如下:一个学生表如下:第一条记录跟第四条记录完成相同 第一条的性名列跟第二条相同。

现在除掉相同的姓名的数据,只保留一条。代码如下:
SELECT id AS "学号", IFNULL (age,0) AS "年龄", DISTINCT s.`name` AS "姓名", brithday AS "生日", s.`intsert_time` AS "插入时间" FROM stu1 s ;结果报如下错:

既然distinct 只能放在第一列前,哪我把姓名列移动第一列看看代码如下:
SELECT DISTINCT s.`name` AS "姓名", id AS "学号", IFNULL (age,0) AS "年龄", brithday AS "生日", s.`intsert_time` AS "插入时间" FROM stu1 s ;
运行结果却是去掉第四条数据,但是没有去掉第二条数据。说明distinct去重复要求某几条数据完成一样才会去重复。运行结果如下图:

如果想姓名列相同,只保留一条记录,那么可以考虑group by 分组,现在用group by 看看效果,代码如下:
SELECT DISTINCT s.`name` AS "姓名", id AS "学号", IFNULL (age,0) AS "年龄", brithday AS "生日", s.`intsert_time` AS "插入时间" FROM stu1 s GROUP BY s.`name`;
运行结果只保留第一条记录,第2,4条数据都去掉了。

如果我们只需要计算某个字段去重复后的总记录数的话可以用以下代码:
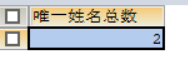
SELECT COUNT(DISTINCT s.name) AS "唯一姓名总数" FROM stu1 s; 结果如下:
总结一下:如果我们需要去掉完全重复的数据可以用distinct放在第一列数据前面,如果我们只需要按照某列相同去掉重复的数据,可以用group by 进行分组。如果我们只需要计算某一个字段去重复后的总记录数可以 用 count(distinct 列名)聚合函数的方式获取。















 1592
1592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









