






linux iconv方法的使用
参考phpinfo的信息,iconv模块也已经正确加载。
google一下。原来才知道,原来在linux版本下iconv这个方法还是有点下下问题的。
csdn上的一个网友给出的解决方案为:
view sourceprint?一种方法是把iconv换成 mb_convert_encoding
另一种方法是修改iconv 的实现,从glibc 改为libiconv
搞了半天,烦躁!
有朋友碰到的话,也可以这么解决了
按照该网友提供的第一个方法,将iconv方法修改为使用mb_convert_encoding,搞定。。
多谢该网友提供的解决方案。
时间: 2011-09-30
不过英文一般不会存在编码问题,只有中文数据才会有这个问题.比如你用Zend Studio或Editplus写程序时,用的是gbk编码,如果数据需要入数据库,而数据库的编码为utf8时,这时就要把数据进行编码转换,不然进到数据库就会变成乱码. mb_convert_encoding的用法见官方: http://cn.php.net/manual/zh/function.mb-convert-encoding.php 做一个GBK To UTF-8 复制代码 代码如下: <?php header(&qu
开始是这样用的$str = iconv('UTF-8', 'GB2312', unescape(isset($_GET['str'])? $_GET['str']:''));上线后报一堆这样的错:iconv() : Detected an illegal character in input string 考虑到GB2312字符集比较小,换个大的吧,于是改成GBK:$str = iconv('UTF-8', 'GBK', unescape(isset($_GET['str'])? $_GET['
终于皇天不负有心人,答案还是让我找到了. 网上的都是这样用的 复制代码 代码如下: $content = iconv("utf-8","gb2312",$content); 这样做其实也对着了,看着确实是把utf-8转化为gb2312了,但是实际运行的话,往往都是以失败告终的,原因呢? 原因实际上也很简单,因为任何的函数都是执行错误的时候,同时很不幸的是iconv();就很终于出现错误.现在给你正确的答案. 真正的答案是这样的 复制代码 代码如下: $content
一份gb2312.txt(184799字节)确实显得太大了点,而且还要经unicode转换. 这份对照表为51965字节,要小的多了. 对于无法使用iconv函数库的场合还是很实用的. <?php //对照表的使用 $filename = "gb2utf8.txt"; $fp = fopen($filename,"r"); while(! feof($fp)) { list($gb,$utf8) = fgetcsv($fp,10); $charset[$gb]
iconv - Convert string to requested character encoding(PHP 4 >= 4.0.5, PHP 5) mb_convert_encoding - Convert character encoding(PHP 4 >= 4.0.6, PHP 5) 用法: string mb_convert_encoding ( string str, string to_encoding [, mixed from_encoding] ) 需要先启用 mbs
iconv( "UTF-8", "gb2312//IGNORE" , $FormValues['a']) ignore的意思是忽略转换时的错误,发现iconv在转换字符"-"到gb2312时会出错,如果没有ignore参数,所有该字符后面的字符串都无法被保存. 另外mb_convert_encoding没有这个bug,所以最好的写法是: mb_convert_encoding($FormValues['a'], "gb2312"
iconv函数库能够完成各种字符集间的转换,是php编程中不可缺少的基础函数库. 1.下载libiconv函数库http://ftp.gnu.org/pub/gnu/libiconv/libiconv-1.9.2.tar.gz: 2.解压缩tar -zxvf libiconv-1.9.2.tar.gz; 3.安装libiconv #configure --prefix=/usr/local/iconv #make #make install 4.重新编译
1.下载libiconv函数库http://ftp.gnu.org/pub/gnu/libiconv/libiconv-1.9.2.tar.gz: 2.解压缩tar -zxvf libiconv-1.9.2.tar.gz; 3.安装libiconv 复制代码 代码如下: #configure --prefix=/usr/local/iconv #make #make install 4.重新编译php 增加编译参数--with-iconv=/usr/local/iconv windows下 最近
string iconv ( string $in_charset , string $out_charset , string $str ) 在使用这个函数进行字符串编码转换时,需要注意,如果将utf-8转换为gb2312时,可能会出现字符串被截断的情况发生. 此时可以使用以下方法解决: 复制代码 代码如下: //author:zhxia $str=iconv('utf-8',"gb2312//TRANSLIT",file_get_contents($filepath)); 即在第二
1. iconv()介绍 iconv函数可以将一种已知的字符集文件转换成另一种已知的字符集文件.例如:从GB2312转换为UTF-8. iconv函数在php5中内置,GB字符集默认打开. 2. iconv()错误 iconv在转换字符"-"到gb2312时会出错,解决方法是在需要转成的编码后加 "//IGNORE",也就是iconv函数第二个参数后.如下: 复制代码 代码如下: iconv("UTF-8", "GB2312//IGNO
大家都知道,在JS中字符串的长度不分中英文字符, 每一个字符都算一个长度,这跟PHP里的strlen()函数就不太一样.PHP里的strlen()函数根据字符集把GBK的中文每个2累加,把UTF-8的中文字符每个按3累加. 有些童鞋可能要问了,为什么要计算实际长度? 主要是为了匹配数据库的长度范围内,比如GBK的数据库某字段是varchar(10),那么就相当于5个汉字长度,一个汉字等于两个字母长度.如果是UTF8的数据库则是每个汉字长度为3. 知道了以上原理以后,我们就可以算出一个字符串的实际
方法一:SELECT CAST('123' AS SIGNED); 方法二:SELECT CONVERT('123',SIGNED); 方法三:SELECT '123'+0; 以上这篇mysql字符串的'123'转换为数字的123的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
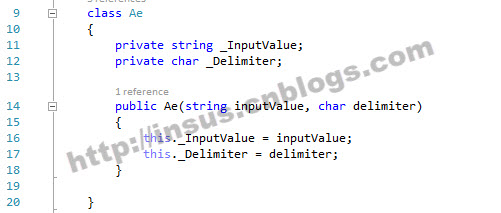
原始数据: string input = "3,7,2,8,1,9,1,34,67,78,22"; 要处理为: string[] stringArray = { "3", "7", "2", "8", "1", "9", "1", "34", "67", "78", "22&qu
一.利用var_export(), eval()方法 /** * 将含有GBK的中文数组转为utf-8 * * @param array $arr 数组 * @param string $in_charset 原字符串编码 * @param string $out_charset 输出的字符串编码 * @return array */ function array_iconv($arr, $in_charset="gbk", $out_charset="utf-8"
PHP转换文件编码是一个比较简单的事情,但是在开发中传递中文参数的时候,有时候不知道是什么编码,结果造成了乱码的现象.这里有个非常方便的解决办法,可以自动识别编码并转换为UTF-8.具体代码如下: 复制代码 代码如下: function characet($data){ if( !empty($data) ){ $fileType = mb_detect_encoding($data , array('UTF-8','GBK','LATIN1','BIG5')) ;
shell 脚本: #!/bin/sh ## ## convert file from GB2312 to UTF-8 ## path="$1" unset opt if [ "$2" = "force" ]; then opt="-c -s" fi if [ -z "$path" ]; then echo "nUsage: $0 n" elif [
1.文件转码:使用脚本 gbk转utf-8的脚本文件: #!/bin/bash FILE_SUFFIX="java xml html vm js" # FILE_SUFFIX="vm" file_names="" for x in $FILE_SUFFIX do file_names=`find . -name "*.$x" | xargs file -I | grep -v utf-8 | awk -F " |:&
问题:在 Golang 的调试过程中出现中文乱码 原因:Golang 默认不支持 UTF-8 以外的字符集 解决:将字符串的编码转换成UTF-8 首先需要 mahonia 这个包 go get github.com/axgle/mahonia 然后新建一个 func src 字符串 srcCode 字符串当前编码 tagCode 要转换的编码 func ConvertToString(src string, srcCode string, tagCode string) string { src
MySQL的默认编码是Latin1,不支持中文,要支持中文需要把数据库的默认编码修改为gbk或者utf8. 1.需要以root用户身份登陆才可以查看数据库编码方式(以root用户身份登陆的命令为:>mysql -u root –p,之后两次输入root用户的密码),查看数据库的编码方式命令为: >show variables like 'character%'; +--------------------------+----------------------------+ | Variab














 2747
2747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









