






什么是爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据
爬虫可以做什么?
你可以爬取小姐姐的图片,爬取自己有兴趣的岛国视频,或者其他任何你想要的东西,前提是,你想要的资源必须可以通过浏览器访问的到。
爬虫的本质是什么?
上面关于爬虫可以做什么,定义了一个前提,是浏览器可以访问到的任何资源,特别是对于知晓web请求生命周期的学者来说,爬虫的本质就更简单了。爬虫的本质就是模拟浏览器打开网页,获取网页中我们想要的那部分数据。
微博热搜榜python爬虫,仅供学习交流
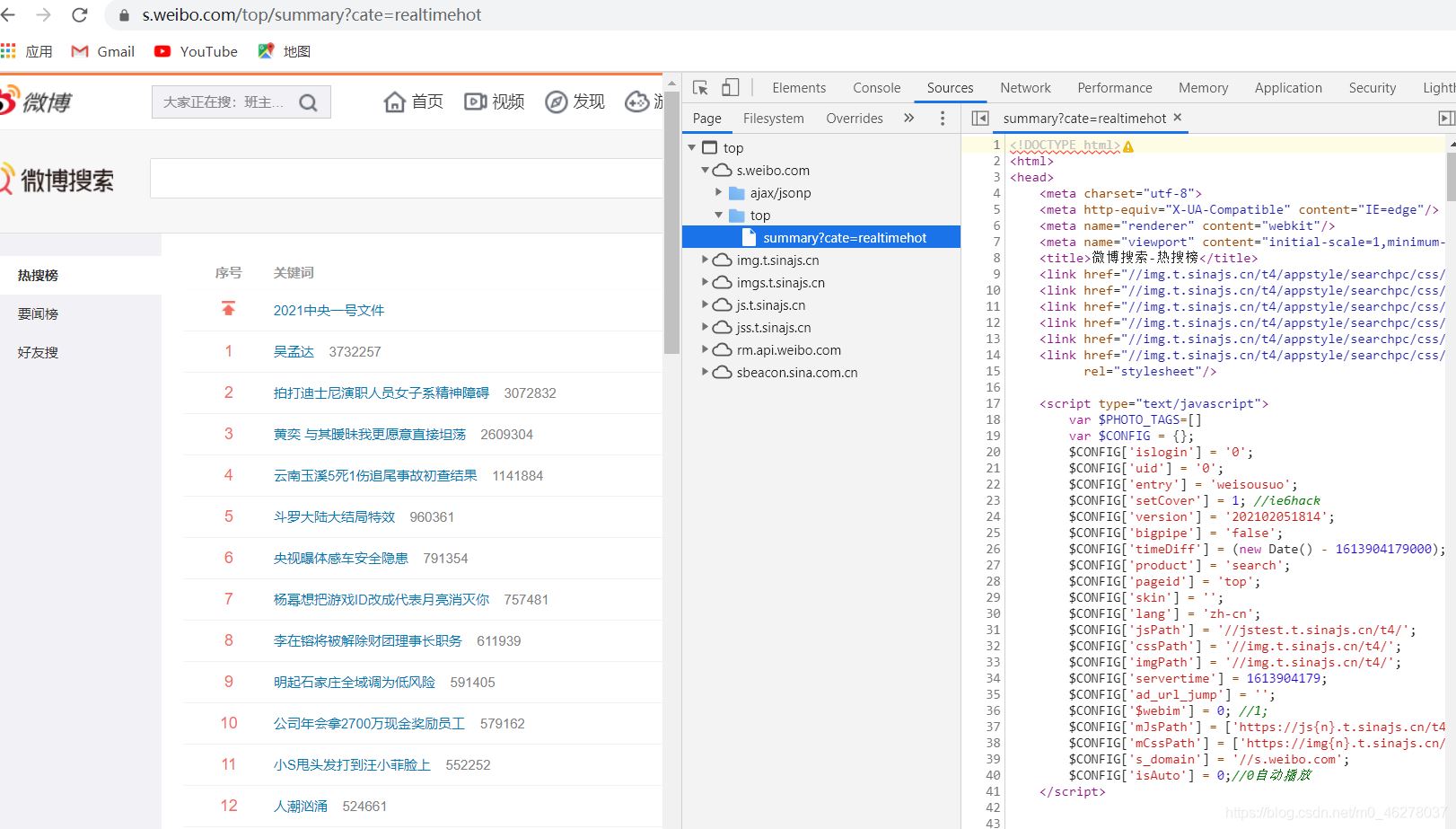
源码及注释:
# -*- coding=UTF-8 -*-
#!usr/bin/env python
import os
import time
import requests
from lxml import etree
url = "https://s.weibo.com/top/summary?cate=realtimehot"
headers={
'Host': 's.weibo.com',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Referer': 'https://weibo.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
}
r = requests.get(url,headers=headers)
print(r.status_code)
html_xpath = etree.HTML(r.text)
data = html_xpath.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td[2]')
num = -1
# # 解决存储路径
# time_path = time.strftime('%Y{y}%m{m}%d{d}',time.localtime()).format(y='年', m='月', d='日')
# time_name = time.strftime('%Y{y}%m{m}%d{d}%H{h}',time.localtime()).format(y='年', m='月', d='日',h='点')
# root = "./" + time_path + "/"
# path = root + time_name + '.md'
# if not os.path.exists(root):
# os.mkdir(root)
# 解决存储路径
time_path = time.strftime('%Y{y}%m{m}%d{d}',time.localtime()).format(y='年', m='月', d='日')
time_name = time.strftime('%Y{y}%m{m}%d{d}%H{h}',time.localtime()).format(y='年', m='月', d='日',h='点')
year_path = time.strftime('%Y{y}',time.localtime()).format(y='年')
month_path = time.strftime('%m{m}',time.localtime()).format(m='月')
day_month = time.strftime('%d{d}',time.localtime()).format(d='日')
all_path = "./" + year_path + '/'+ month_path + '/' + day_month
if not os.path.exists(all_path):
# 创建多层路径
os.makedirs(all_path)
# 最终文件存储位置
root = all_path + "/"
path = root + time_name + '.md'
print(path)
# 文件头部信息
with open(path,'a') as f:
f.write('{} {}\n\n'.format('# ',time_name+'数据'))
f.close()
for tr in (data):
title = tr.xpath('./a/text()')
hot_score = tr.xpath('./span/text()')
num += 1
# 过滤第 0 条
if num == 0:
pass
else:
with open(path,'a') as f:
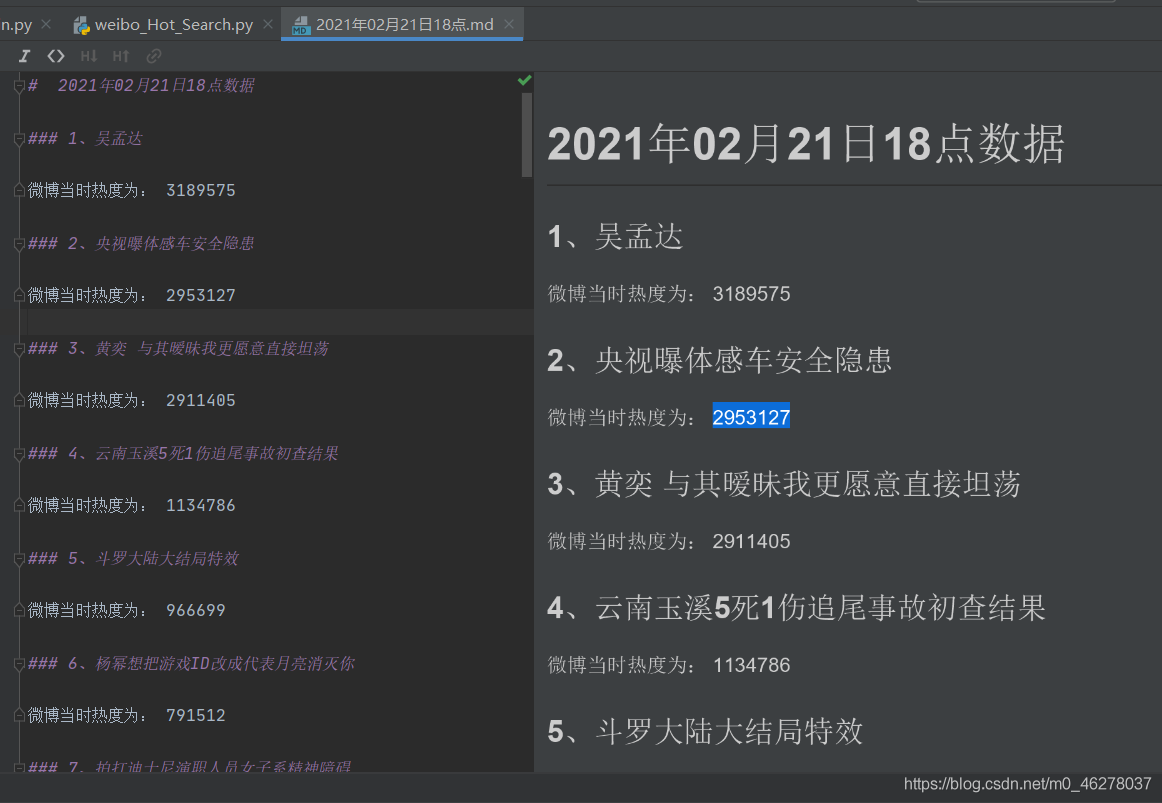
f.write('{} {}、{}\n\n'.format('###',num,title[0]))
f.write('{} {}\n\n'.format('微博当时热度为:',hot_score[0]))
f.close()
print(num,title[0],'微博此时的热度为:',hot_score[0])
运行:
运行结束后会在当前文件夹下生成以时间命名的文件夹,并且会生成以具体小时为单位的具体时间命名的 Markdown 文件,如下:
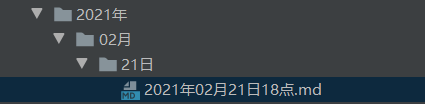
查看:
到此这篇关于Python爬虫爬取微博热搜保存为 Markdown 文件的文章就介绍到这了,更多相关Python爬虫爬取微博热搜保存内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!















 1703
1703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









