






1、select 选项
【all | distinct】
语法:
select 【all | distinact】字段名 from 表名;
说明:
all (默认)在显示结果中包含重复的数据
distinact 在显示结果中去除重复的数据
此处的重复是在显示结果中整行来对比的

注意:
如果加上id字段,任何一行中的数据都不会重复
2、字段别名
在数据查询时,我们可以对查询出来的字段名,在显示时设置一个别名
语法:
select 字段名 【as】别名,字段名【as】别名 from 表名;

3、数据源
所谓的数据源,就是数据的来源
数据源可以分为单表数据源、多表数据源、子查询数据源
单表数据源: 数据的来源,只来源于一个表
多表数据源: 数据的来源,来源于多个表
子查询数据源: from后数据的来源是另一个select语句
①、单表数据源

②、多表数据源
语法:
select * from 表A,表B;
说明:
多表数据源产生的结果是一个迪卡尔积
迪卡尔积的形式是两个表的字段数相加,记录数相乘
查询的结果以表A字段在前,表B字段在后,并且每个表A字段值都对应着所有表B字段值
笛卡尔积,没有实际的意义,但是以后所要讲的连接查询都是以笛卡尔积为基础的

③、子查询数据源
表中的数据是存储在硬盘中的一个文件中,当我们运行select语句时,是在内存中运行的
语法:
select * from (select * from 表名)表别名;
说明:
括号内的运行结果也是一个表,这个表是临时表


4、表别名
在一条select语句引用一个表时,也可以为这个表起个别名,主要应用在连接查询中
语法:
select * from 表 as 表别名;
使用列别名引用字段
语法:
select 表别名.字段名 from 表 表别名;

5、【where 子句】(分组统计之前的筛选)
【where 子句】【group by 子句】【order by 子句】【having 子句】【limit 子句】
这些子句称为五子句,五子句可以随意的组合,但是组合的顺序必须按语法的顺序书写
①、使用
where 子句,根据表达式,在将数据从硬盘中读取到内存时进行第一次筛选
②、原理
将硬盘中的数据一行行读取,放到内存中跟where条件对比,判断表达式是否成立,成立放到结果集中,不成立则丢弃,然后将结果集中的数据返回给客户端
6、【group by 子句】
语法:
select * from 表名 group by 字段1,字段2...;
①、作用
group by 是对 where 子句得到的结果,分组统计

②、原理
说明:
group by是对where返回的结果,按指定字段进行分组,并且只取每个分组的第一条数据,按分组字段的字段值进行升序排序
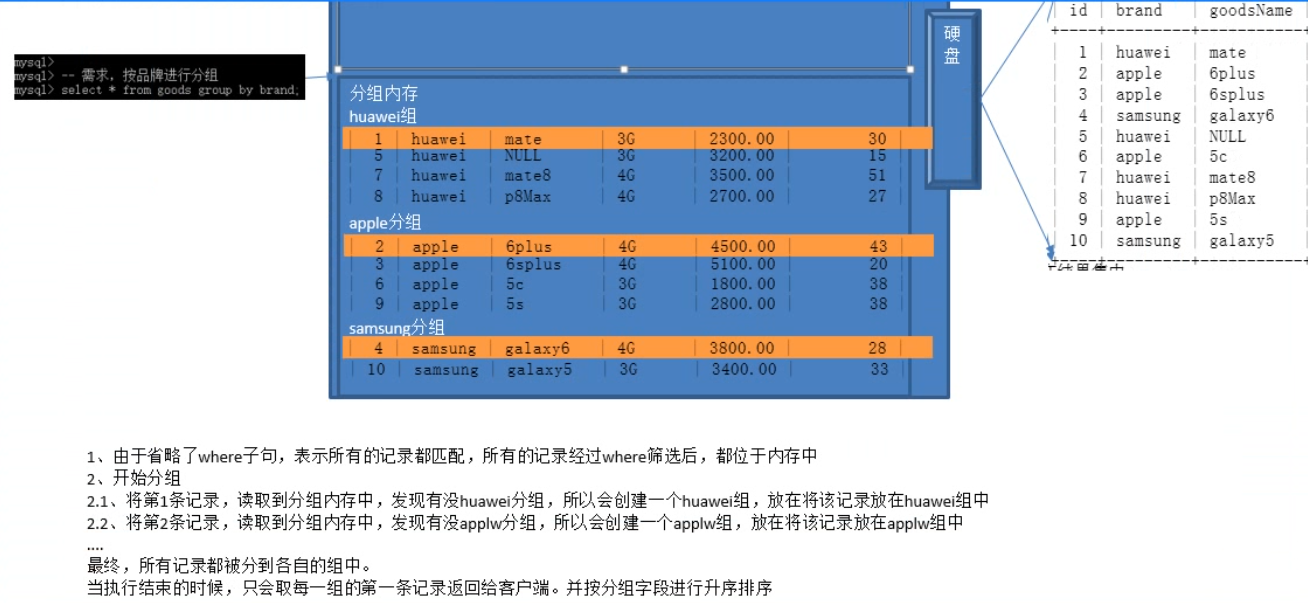
提示:
如果省略group by语句,相当于所有的记录为一个大组,但是要把所有的记录都返回
③、统计函数
group by 重点是在统计上,mysql对分组的数据提供了很多的统计函数
一、count(* | 字段名)
对group by 得到的每一组,求每一组的记录数
语法:
select 字段1,count(字段2) from 表名 group by 字段1;
count(字段名)
按指定的字段进行统计,如果被统计的指定字段的值是null,这条记录不会参与统计
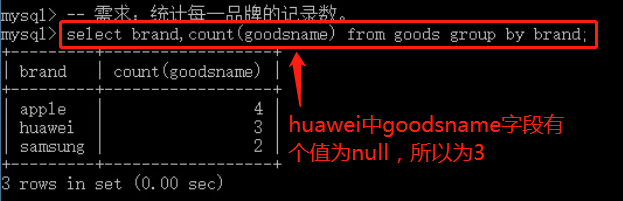
count(*)
统计所有记录数,不受null值的影响

二、max(字段名)
统计group by分组之后,每一组中指定字段的最大值(必须为数值型)
语法:
select 字段1,max(字段2) from 表名 group by 字段1;

如果max函数里的参数不限定字段,得到的结果与max(字段)的值不匹配(因为max是取分组里最大值):

三、min(字段名)
统计group by分组之后,每一组中指定字段的最小值(必须为数值型)
语法:
select 字段1,min(字段2) from 表名 group by 字段1;

四、avg(字段名)
统计group by分组之后,每一组中指定字段的平均值(必须为数值型)
语法:
select 字段1,avg(字段2) from 表名 group by 字段1;

五、sum(字段名)
统计group by分组之后,每一组中指定字段的和(必须为数值型)
语法:
select 字段1,sum(字段2) from 表名 group by 字段1;

扩展:
所有的统计函数后面都可以使用一个别名来表示

④、多字段分组
当 group by 后面指定多个字段时,会进行多字段分组
语法:
select * from 表名 group by 字段1,字段2 ...;
说明:
group by 先根据字段1分成若干组,再在字段1的组里根据字段2分成若干组,以此类推
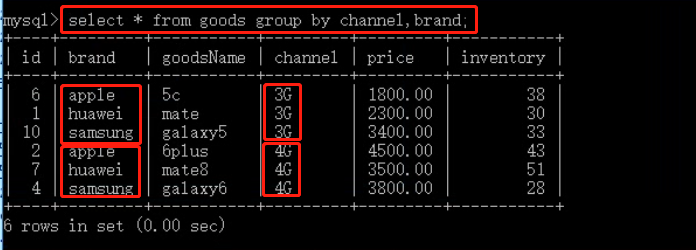
在多字段分组的同时使用统计函数:
示例(count):

分析:
在多字段进行分组时,最终的统计数据,是针对最后一个组统计,如上例中是针对 brand 所划分的组
⑤、回溯统计(with rollup)
多字段进行分组,统计函数默认是应用在最后一个组上面的,如果想对包含最后一个组前面的大组进行同样的统计,那么 with rollup 就可以实现这个需求(总的统计)
语法:
select * from 表名 group by 字段1,字段2 with rollup;

7、【having 子句】(分组统计之后的筛选)
作用:
where 是将硬盘中的数据读取到内存时进行第一次筛选
group by 是针对where子句匹配后的记录进行分组统计
having 是针对group by分组统计得到的结果进行第二次筛选
语法:
select 字段1,统计函数(字段2)别名 from 表名 group by 字段1 having 别名 + 条件;

扩展:
统计函数不能出现在where 子句中
having可以代替where子句,但是不建议这么用
8、【order by 子句】
语法:
select * from 表名 order by 字段1【asc | desc】,字段2【asc | desc】...;
说明:
order by 对where子句、group by子句、having子句得到的结果进行一个显示顺序上的控制
asc 升序
desc 降序
9、【limit 子句】
语法:
select * from 表名 limit【offset】 rows;
说明:
limit 是对where 子句、group by 子句、having 子句、order by 子句得到的结果进行一个显示行数的限制
offset 偏移量,第一条记录偏移量为0,第二条记录偏移量为1,以此类推,如果省略表示0
rows 显示的行数
数据分页:
分页相关参数:
每一页的记录数: num 人为设定
当前页数: page 用户所点击的页数
公式:
select * from 表名 limit(num - 1)* page,page;
说明:
limit 第一个参数为从第几条数据开始显示,第二个参数为显示条数
10、联合查询
使用的是分表存储数据,联合查询
语法:
select * from 表A
union【all | distinct】
select * from 表B;
说明:
分表存储,联合查询;为什么要分表查询,为了解决查询1条记录更快,但是查询单条记录快了,如何解决查询所有呢,所以才出现了联合查询的语法
【all | distinct】 union 选项
all 表示所有
distinct 【默认】去除重复
在联合查询中的两条select语句,所查询出来的字段的个数必须一致,且以表A的字段作为显示字段


联合查询的注意事项:
联合查询还可以解决,对同一个表的不同部分进行不同的操作
如果联合查询的select语句中有order by子句,那么必须配合limit使用
















 7780
7780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









