






原标题:Linux路径名查找(下)
我们接下来看看path_init函数,
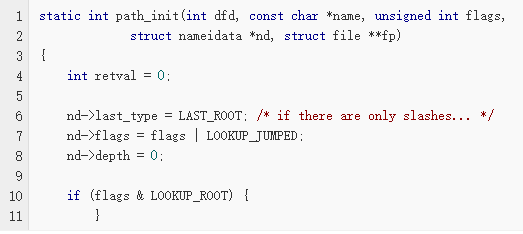
首先将 last_type 设置成 LAST_ROOT,意思就是在路径名中只有“/”。为方便叙述,我们把一个路径名分成三部分:起点(根目录或工作目录)、子路径(以“/”分隔的一系列子字符串)和最终目标(最后一个子路径),Kernel 会一个子路径一个子路径的遍历整个路径。所以 last_type 表示的是当前子路径(不是 dentry 或 inode)的类型。LOOKUP_ROOT标志 可以提供一个路径作为根路径,主要用于两个系统调用 open_by_handle_at 和 sysctl,这里不做分析了。

设置vfsmount域是空,初始化相关文件系统的的顺序锁序号。然后根据给定的path内容,设置其实位置。如果给定的是绝对路径(第一个字符是’/’),就把path指向进程的根目录,如果dfd==AF_FDCWD,表示path是调用进程的当前工作路径,获取current(这个在前面分析do_fork的博文里面解释了这个宏表示当前进程)的当前工作路径,把path执行这个路径。

如果传入的path不是一个绝对路径,而且dfd不是一个特殊的值。根据这个dfd得到对应的fd结构体,然后获取这个dfd所指向文件的dentry结构体,把path指向这个目录。
所以大概来说,path_init函数就是根据传入的不同参数初始化nd的path域。
分析完了path_init函数,我们接下来分析path walk的核心函数——link_path_walk函数。

函数头解释:函数返回一个int值可以判断查找操作是否出错,参数name就是从用户空间复制来的path,nd表示查找过程中用来存储临时数据的nameidata结构体。
首先跳过多个连续的/(内核是有这样的容错的,你可以试试输入一个 ls ///和ls /输出是不是一样的),这样做是为了是的name指针指向一个真正的path中的第一个文件名 判断name是不是空的,空返回。因为如果是/开始的,在path_init函数中nd填充的就是根文件的信息,如果此时name为空表示path就是根目录,那么就不需要pathwalk已经找到了对应的dentry和其他的信息。现在开始一个很大的死循环,可以肯定我们所有的查找操作都是在这个循环里。在查找之前要先检测权限。如果权限检测出错,跳出循环。计算name(系统调用传入的path),填充quick string结构体。初始化name的第一个文件的文件类型,(分为普通文件,.文件和..文件)。

如果第一个分量是普通文件,得到path中的第一个分量的dentry(这个在path_init这个函数在填充nd的path时候填充好了),nd中的last设置为当前的文件,。name[len]访问待查找路径中的下一个分量,判断如果下一个分量的第一个字符是空的,表示当前的文件是带查找路径的最后一个分量。跳过两个分量中间的斜线(这里和开始的时候相似,有可能用户输入了多个斜线),跳过以后再进行一次前面的判断。如果不空,name指针就指向下一个分量的开始位置(注意这里len并不是第一个分量的长度了,应该是前一个分量加上一个或者多个斜线),为下一次循环做准备。这里要注意修改name指针的时候,必须要确定后指针移动后指向的空间是可以访问的,在最高特权级下访问了不该访问的内存是一个不可挽回的错误。
捋一下,刚才的过程大概就是“走过”路径的第一个分量,如果路径以.或者..开头,设置nd的type成员是对应的类型。如果path是以/开始的,跳过前面的不止一个/,访问完第一个分量(访问是指根据该分量的信息填充nd的last和last_type成员),name指针指向下一个分量。
现在我们已经知道了name此时指向的空间存储的是一个中间分量,调用walk_component“走过这个节点”,walk_component定义如下:

在遍历的时候我们看到了,子目录被分成三种情况,.目录或者..目录、普通目录或者一个符号链接。在walk_component函数开始的时候就判断了是不是.目录或者..目录,如果是执行handle_dots,这个函数不展开分析了,大概执行的功能是:如果是.目录就直接返回0,如果是..目录表示要走进父目录,返回的时候,nd结构体已经“站在了”父目录上(nd结构体中填充的是父目录的信息)。
如果当前的目录是一个普通目录,我们前面说了路径行走有两个策略:先在效率高的rcu-walk模式下“行走”,如果失败了就在效率较低的ref-walk模式下“行走。lookshihouup_fast函数应该就是指的两个查找策略,先调用lookup_fast,当返回值大于0的时候,才会调用lookup_slow函数当我们先来分析lookup_fast(rcu-walk模式),这里有必要澄清一下,ref-walk模式并不是一定可以找到的,有可能也会失败。

调用__d_lookup_rcu函数在哈希桶中找到对应的dentry(这是哪个dentry还记得吗?这个是name指向的那个目录分量的dentry),如果找到了就返回dentry,如果没找到就跳转到unlazy标记处(切换到ref-walk模式继续查找)。根据这个dentry得到对应的inode,进行一系列的检查操作,这样是为了确保在读取的时候,并没有其他进程对这些结构进行修改操作(rcu-walk模式并没有加锁),更新的临时变量path,这时候不能直接修改nd变量,因为不能确定这个分量是不是目录,nd记录的信息必须是目录,然后结束。
其中有很多个跳转到unlazy标志的语句,我们前面说了,跳到unlazy标志表示rcu模式查找失败,用ref模式进行查找。ref模式的fast查找还是在内核缓冲区查找相应的dentry,和上述过程类似,这就不深入讲了。下来大概看看lookup_slow函数:

看到这里,大家应该就明白了,为什么这种查找方法很慢呢,因为这种查找是互斥操作,进程可能会阻塞。而且lookup_hash函数还是再会回到dcache中在找一遍,如果没有找到的话就调用文件系统自己的lookup函数从头开始找,所以这种方式比lookup_fast方式比起来慢多了。
看完了这两个lookup函数,我们还是回到walk_component函数,剩下的也不多了。

询问是否需要跟踪符号链接,还记得我们之前说的分类吗?在路径行走的时候,子分量被分为三种:.开头的目录、普通目录和符号链接。如果这个自分量是符号链接,根据这个链接找到指向的目标文件,用目标文件替代该链接文件。如果这个分量不是符号链接,这时候我们可以确定这个分量就是一个普通的目录,根据path的值,填充nameidata,也就是nd变量。此时nd已经“站在”了子分量上,通过这样的递归调用,最终nd回“站在”最后一个目录上。
到此路径名查找就结束了。
责任编辑:














 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









