



【00】时代变了
移动互联网时代的Hello World(参见Xamarin 使用极光推送 详细教程 ),安装某一套开发工具包(IDE)就够了,AI时代就明显要的就多了。
依然直奔主题,无废话,直接上实操步骤。微调基础LLM,使之支持普通话翻译为粤语。
【01】名词解释

【02】无中生GPU
AI时代没有GPU寸步难行,如何薅到GPU呢?
https://www.kaggle.com/ 自行注册,通过手机号验证之后,每周可以薅30H的GPU资源。
【03】环境初始化
新建Notebook,就当是VS的项目对待了。
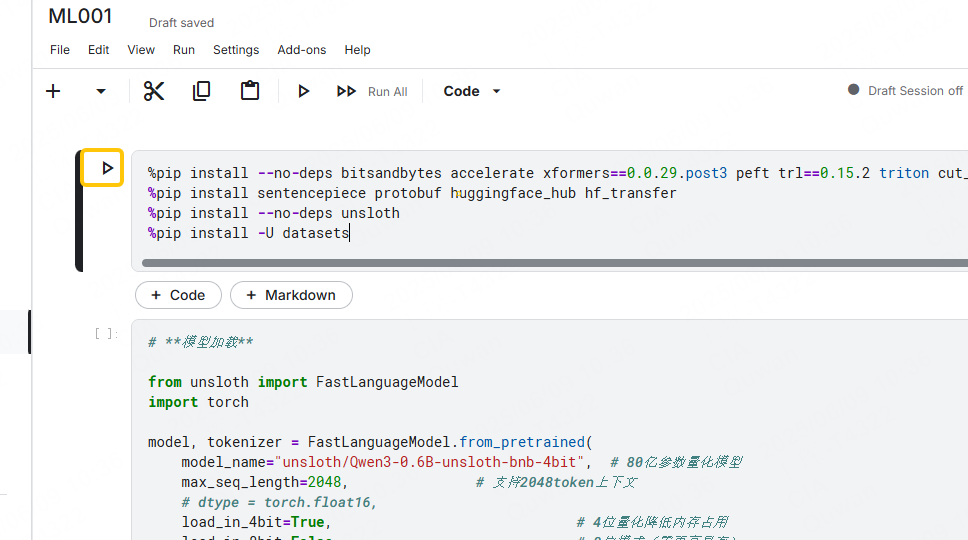
初始化基础环境,依赖的python库。

%pip install --no-deps bitsandbytes accelerate xformers==0.0.29.post3 peft trl==0.15.2 triton cut_cross_entropy unsloth_zoo %pip install sentencepiece protobuf huggingface_hub hf_transfer %pip install --no-deps unsloth %pip install -U datasets

脚本或代码,都可以点击右边的 运行 按钮执行,并且在环境未重启之前,都可以保存上下文变量数据。
【04】加载基础模型
基础模型选择:unsloth/Qwen3-0.6B-unsloth-bnb-4bit,模型1G多比较适合用来写HelloWorld,本身也不支持粤语翻译。

from unsloth import FastLanguageModel import torch model, tokenizer = FastLanguageModel.from_pretrained( model_name="unsloth/Qwen3-0.6B-unsloth-bnb-4bit", # 6亿参数量化模型 max_seq_length=2048, # 支持2048token上下文 # dtype = torch.float16, load_in_4bit=True, # 4位量化降低内存占用 load_in_8bit=False, # 8位模式(需更高显存) full_finetuning=False, # 启用参数高效微调(PEFT) # token="<YOUR_HF_TOKEN>", # 访问权限模型需提供令牌 ) model = FastLanguageModel.get_peft_model( model, r=32, # LoRA矩阵秩,值越大精度越高 target_modules=[ # 需适配的模型层 "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj" ], lora_alpha=64, # 缩放因子,通常设为r的2倍 lora_dropout=0, # 关闭 dropout bias="none", # 不微调偏置项 use_gradient_checkpointing="unsloth", # 支持长上下文 random_state=3433, # 随机种子确保可复现 )

【05】微调数据集加载
数据采用以下两个,简单的粤语、普通话对照记录。
https://huggingface.co/datasets/agentlans/cantonese-chinese
https://huggingface.co/datasets/botisan-ai/cantonese-mandarin-translations

from datasets import load_dataset,Dataset import pandas as pd # 加载推理与对话数据集 ds01 = load_dataset("agentlans/cantonese-chinese")["train"] print(ds01.column_names) # 查看所有列名 ds02 = load_dataset("botisan-ai/cantonese-mandarin-translations")["train"] print(ds02.column_names) # 查看所有列名 # 标准化推理数据为对话格式 def generate01(examples): problems = examples["zh"] solutions = examples["yue"] return { "messages": [ {"role": "system", "content": "你是一个普通话转为粤语的机器人。"}, {"role": "user", "content": problems}, {"role": "assistant", "content": solutions} ] } def generate02(examples): problems = examples["translation"]["zh"] solutions = examples["translation"]["yue"] return { "messages": [ {"role": "system", "content": "你是一个普通话转为粤语的机器人。"}, {"role": "user", "content": problems}, {"role": "assistant", "content": solutions} ] } dsm01= ds01.map(generate01) dsm02= ds02.map(generate02)
cvs01 = tokenizer.apply_chat_template( dsm01["messages"], tokenize=False )
cvs02 = tokenizer.apply_chat_template( dsm02["messages"], tokenize=False ) # 设定对话比例 chat_percentage = 0.7 data = pd.concat([ pd.Series(cvs01), pd.Series(cvs02), ]) data.name = "text" combined_dataset = Dataset.from_pandas(pd.DataFrame(data)) combined_dataset = combined_dataset.shuffle(seed=3407)

【06】开始微调
使用trl 库,进行微调。

from trl import SFTTrainer, SFTConfig print("开始训练...") trainer = SFTTrainer( model=model, tokenizer=tokenizer, train_dataset=combined_dataset, # 结构化数据集 eval_dataset=None, args=SFTConfig( dataset_text_field="text", # 用于训练的数据集字段 per_device_train_batch_size=2, # 单设备训练批次大小 gradient_accumulation_steps=4, # 梯度累积步数 warmup_steps=5, # 学习率预热步数 max_steps=30, # 总训练步数 learning_rate=2e-4, # 学习率 logging_steps=1, # 日志记录频率 optim="adamw_8bit", # 优化器 weight_decay=0.01, # 权重衰减 lr_scheduler_type="linear", # 学习率衰减策略 seed=3407, report_to="none", # 日志平台(可选wandb) ), ) trainer_stats = trainer.train()

【07】效果检测
进行简单的对话,看是否有效果。

messages = [ {"role": "system", "content": "你是一个普通话转为粤语的机器人。"}, {"role": "user", "content": "有个老婆婆在元朗紫荆东路等小巴"} ] text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, # 生成响应必需 enable_thinking=False, # 禁用思考 ) from transformers import TextStreamer _ = model.generate( **tokenizer(text, return_tensors="pt").to("cuda"), max_new_tokens=256, # 最大生成token数 temperature=0.7, top_p=0.8, top_k=20, streamer=TextStreamer(tokenizer, skip_prompt=True), )

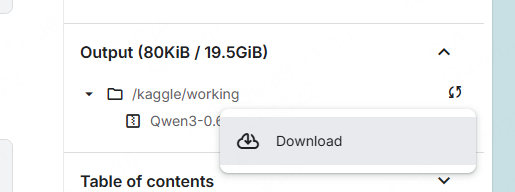
【08】微调后模型保存,并下载
下载时Edge浏览器会先下载完文件之后,才弹出保存对话框。点了Download之后,感觉没有任何反应 需要耐心等待N长时间。

import shutil # 模型保存在目录 my_model="Qwen3-0.6B-cia-cantonese-chinese" model_dir = "/kaggle/working/Models/"+my_model output_zip = my_model+".zip" model.save_pretrained_merged( model_dir, tokenizer, save_method="merged_16bit" ) # 压缩成 .zip 文件 shutil.make_archive(output_zip.replace(".zip", ""), "zip", model_dir) print(f"✅ 模型已压缩为 {output_zip}")

【09】本地加载微调 后的模型
微调之后的模型,不需要太多资源就可以运行。可以本地或者继续在Kaggle上运行,验证。

from transformers import AutoModelForCausalLM, AutoTokenizer class QwenChatbot: def __init__(self, model_name="G:/00LLM/models/Qwen3-0.6B-cia-cantonese-chinese"): # def __init__(self, model_name="G:/00LLM/models/Qwen3-0.6B-cia-finetuned-002"): # def __init__(self, model_name="G:/00LLM/models/Qwen3-0.6B-unsloth-cia-finetuned"): self.tokenizer = AutoTokenizer.from_pretrained(model_name) self.model = AutoModelForCausalLM.from_pretrained(model_name) self.history = [{"role": "system", "content": "你是一个普通话转为粤语的机器人。"}] def generate_response(self, user_input): messages = self.history + [{"role": "user", "content": user_input}] text = self.tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True ) inputs = self.tokenizer(text, return_tensors="pt") response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist() response = self.tokenizer.decode(response_ids, skip_special_tokens=True) # Update history # self.history.append({"role": "user", "content": user_input}) # self.history.append({"role": "assistant", "content": response}) return response # Example Usage if __name__ == "__main__": chatbot = QwenChatbot() print("Welcome to the Qwen Chatbot!") print("You can ask questions, and the bot will respond.") print("Type 'q' to quit the chat.") while True: user_input = input("You: ") if user_input.lower() == 'q': break response = chatbot.generate_response(user_input) print(f"Bot: {response}") print("----------------------")

以上最简单的 LLM微调详细操作步骤。
原创作者: KendoCross 转载于: https://www.cnblogs.com/KendoCross/p/18920456


















 1991
1991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









