






看代码你只是过滤。int(0)代表没匹配到,int(1)是匹配成功。
帮你改一下代码吧,分组捕获不能乱用,正则书写要简洁,还要尽量提高运行效率,还不能存储无谓的变量。要搞懂正则引擎的回溯原理才能明白自己在干什么。
更初级一点的知识,你至少要了解贪婪匹配和非贪婪匹配匹配原理和运行效率的差异。
原:
preg_match('/^(([a-zA-Z0-9]+\-?)+[a-zA-Z0-9]+\.)+[a-zA-Z]+$/i','lo-n.l-on.loh-4va.ccccc5om');
改:
preg_match('/^(?:(?:\w+\.?\w+)-?){4}$/', 'lo-n.l-on.loh-4va.ccccc5om');
我以题主的问题来分析一下。
以题主的第一段代码为例:
preg_match('/^(([a-zA-Z0-9]+\-?)+[a-zA-Z0-9]+\.)+[a-zA-Z]+$/i','lo-n.l-on.loh-4va.ccccc5om')
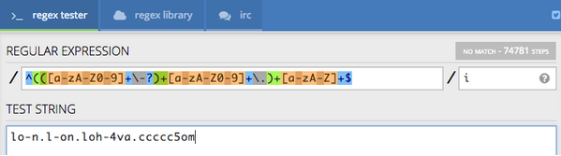
共花费74781步, 7万多步!
改成我上面修改后的
preg_match('/^(?:(?:\w+\.?\w+)-?){4}$/', 'lo-n.l-on.loh-4va.ccccc5om');
后:
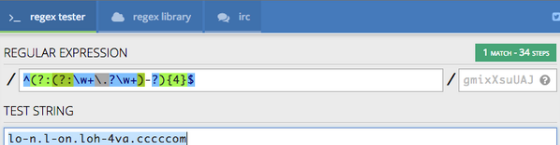
只需要34步。
分析一下匹配过程.
题主的:

修改后的匹配步骤:

74781步 : 34 步 约等于2200%, 效率真的是天壤之别.
----补充于dec 29 ---
关于正则的学习:
我是在learning perl里详细研究过。个人觉得用好正则主要需要遵循下面几点:
1 分清什么时候用贪婪匹配、非贪婪匹配
2 尽量用锚位符
3 能分组的尽量分组
4 元字符与其枚举不如反向过滤和概括,如,[a-zA-Z0-9]+不如w+,某些特定场景里,w+不如
以上。
-s ↩















 1316
1316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









