






索引类似于书的
目录,他是帮助我们从大量数据中快速定位某一条或者某个范围数据的一种数据结构。有序数组,搜索树都可以被用作索引。MySQL中有三大索引,分别是B+树索引、Hash索引、全文索引。B+树索引是最最重要的索引,Hash索引和全文索引用的并不是太多,InnoDB不支持建Hash索引,不过存储引擎内部去定位数据页时会使用Hash索引, 这不是本文重点。本文将简单介绍B+树索引。
B+树的基本结构
这里不对B+树做精确定义,直接给出一个B+树的示意图并做一些解释说明。
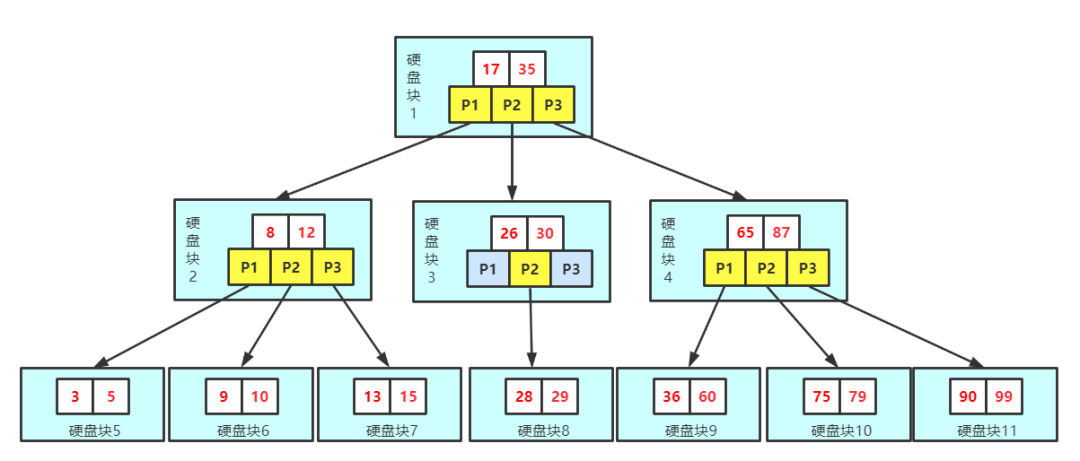 图1:B+树的基本结构(来自网络)
图1:B+树的基本结构(来自网络)
B+树是一颗多路平衡查找树,所有节点称为页,页就是一个数据块,里面可以放数据,页是固定大小的,在InnoDB中是16kb。页里边的数据是一些key值,n个key可以划分为n+1个区间,每个区间有一个指向下级节点的指针,每个页之间以双向链表的方式连接,一层中的key是有序的。以磁盘块1这个页为例,他有两个key,17,35,划分了三个区间(-无穷,17) p1,[17, 35) p2, [35, +无穷] p3三个区间,也称扇出为3. p1指向的下级节点里边的key都是比17小的;p2指向的下级节点里边的key大于等于17,小于35;p3指向的下级节点里边的key都大于等于35。
在B+树查找数据的流程:
例如要在上边这棵树查找28,首先定位到磁盘1,通过二分的方式找到他属于哪个区间,发现是p2,从而定位到磁盘块3,在磁盘块3的key里边做二分查找,找到p2, 定位到磁盘块8,然后二分找到28这个key。对于数据库来说,查找一个key最终一定会定位到叶子节点,因为只有叶子节点才包含行记录或者主键key。
插入节点与删除节点:
这里不对其详细流程做介绍,给大家安利一个工具:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html, 这个工具可以以动画方式演示B+树插入和删除的过程,非常直观,大家可以去动手试试看。如图所示:
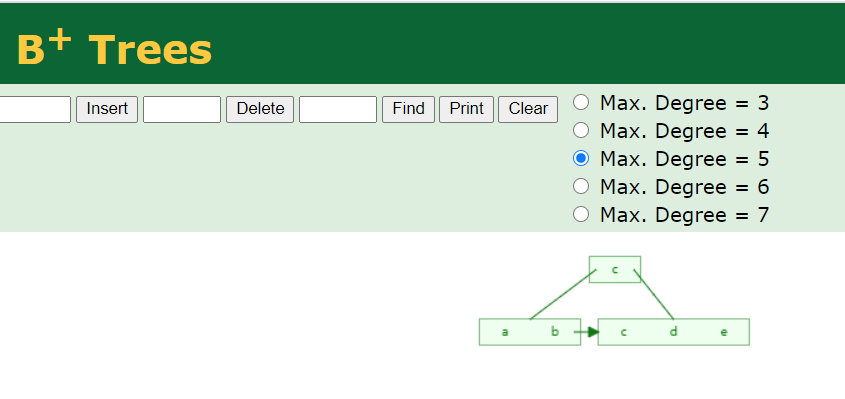
图2:B+树演示工具截图
值得注意的是,插入节点时,可能存在页分裂的情况,删除节点时可能存在页合并的情况。页的分裂就是指当一个页容纳不了新的key时,分为多个页的过程。页合并是指当删除一个节点使得页中的key的数量少到一定程度时与相邻的页合在一起成为新的页。并非一个页满插入就会发生页分裂,会优先通过类似旋转的方式进行调整,这样可以避免浪费空间。
下图演示一种最简单的页分裂情况,假设一页只能放3个key,插入efg时,叶子页放了了,所以分裂为了两个页,并且增加了一层。
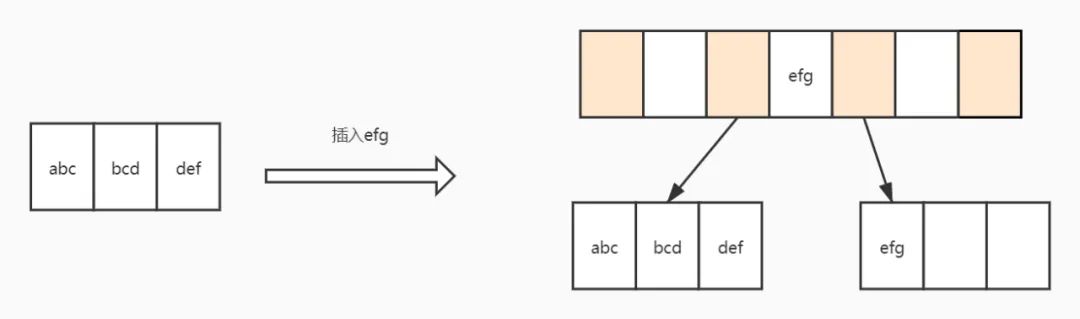
图3:页分裂演示
数据库索引的B+树的显著特点是高扇出,也就是说一个页存放的数据多,这样的好处是树的高度小,大概在2到4层,高度越小,查找的IO次数越少。
为什么要用B+树
为什么不用有序数组
有序数组可以通过二分的方法查找,查找时间复杂度为O(logn). 他的缺点是插入和删除操作代价太高,例如删除0位置,那么1到n-1位置的数据都要往前移动,代价O(n)
为什么不用Hash表
存储引擎内部是有用到Hash表的,这里说的不用Hash表是我们自己建索引时通常不会去建立Hash索引(InnoDB也是不支持的)
Hash表是一种查找效率很高的结构,例如我们Java中的HashMap,基本可以认为他的插入、查询、删除都是O(1)的。
Hash表的底层是一个数组,插入数据时对数据的hashCode对数组长度取模,确定他在数组中的位置,放到数组里边。当然这里可能存在你要放的位置被占用了,这个叫碰撞,或者Hash冲突,此时可以用拉链法解决,具体就是在冲突的位置建一个链表。如下图所示,BCD三个数据在1位置发生冲突,因此在这里形成了链表。Hash表中的查找也很容易,先按插入的方式找到待查找数据在的位置,然后看这个位置有没有,有就找到了。
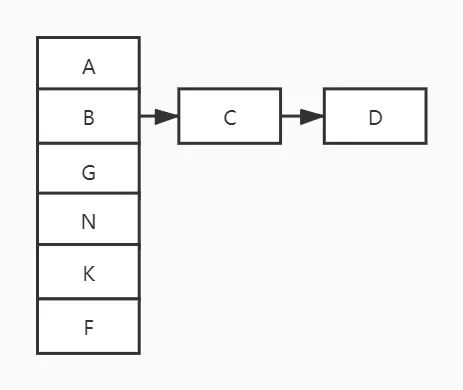
图4:Hash表示意图链表法
Hash表的一个缺点在于对范围查询的支持不友好,比如要查[F,K]之间数据,那么就需要将F到K之间的所有值枚举出来计算hashcode,一个一个去hash表查。而且他是无序的,对于order by不友好。因此除非你的查询就只有等值查询,否则不可能使用Hash表做索引。
为什么不用搜索二叉树
不管是不经调整的搜索二叉树,还是AVL树、红黑树都是搜索二叉树,他的特点是,对于任意一个节点,他的左孩子(如果有)小于自己,右孩子(如果有)大于自己。
搜索二叉树的缺点在于,他的高度会随着节点数增加而增加。我们知道,数据库索引是很大的,不可能直接装进内存,根节点可能是直接在内存的,其他节点存放在磁盘上,查找的时候每往下找一层就需要读一次磁盘。读磁盘的效率是比较低的,因此需要减少读磁盘的次数,那么也就需要减少树的高度。搜索二叉树当数据很多时,高度就会很高,那么磁盘IO次数就会很多,效率低下。
另外,数据库是以页的形式存储的,InnoDB存储引擎默认一页16K,一页可以看成一个节点 ,二叉树一个结点只能存储一个一个数据.假如索引字段为int 也就是一个4字节的数字要占16k的空间,极大的浪费了空间。
B+树有什么特点
高扇出,高扇出使得一个节点可以存放更多的数据,整棵树会更加矮胖。InnoDB中一棵树的高度在2-4层,这意味着一次查询只需要1-3次磁盘IO非叶子节点只存放key值(也就是列值),这使得一页可以存更多的数据,这是高扇出的保证
聚集索引
聚集索引(Clustered index) 也叫聚簇索引、主键索引。他的显著特点是其叶子节点包含行数据(表中的一行),没错,InnoDB存储引擎表数据存在索引中,表是索引组织表。显然表数据不可能有多份,但是必须有一份,所以聚集索引在一张表有且仅有一个。
什么样的列会建立聚集索引?
主键列,也就是你指定一个表的主键就会创建聚集索引。InnoDB中的表必有主键列,如果没有指定主键,那么会选择一个非空唯一列作为主键,否则隐式创建一个列作为主键。
假设有如下一张表,a为主键,假设一页只能放三个数据
| 编号 | a | b | c |
1 | 1 | a | 11 |
2 | 2 | b | 12 |
3 | 3 | c | 13 |
4 | 4 | d | 14 |
表1:示例数据表
我们看一看他的聚集索引大概是张什么样的
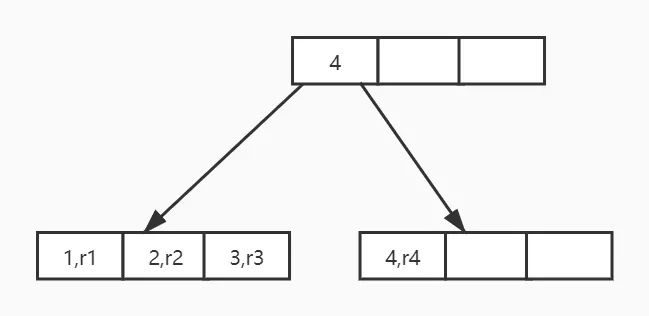
图5:聚集索引索引树示意图
其中r1到r4分别表示编号从1到4的行
使用聚集索引的好处:
查询快,等值和范围查询都快,使用索引必然查询效率会高,使用聚集索引比非聚集索引查询更快,因为他能直接在叶子节点找到数据,而不需要回表(后文说明)基于主键(聚集索引)的
排序快,数据本身就是根据主键排序的
下面我们创建一个表看一下
建表语句和初始化数据如下:
-- a为主键create table t (
a int not null,
b varchar(600),
c int not null,
primary key(a)
) engine=INNODB;insert into t values
(1,'a',11),
(2, 'b', 12),
(3, 'c', 13),
(4, 'd', 14);
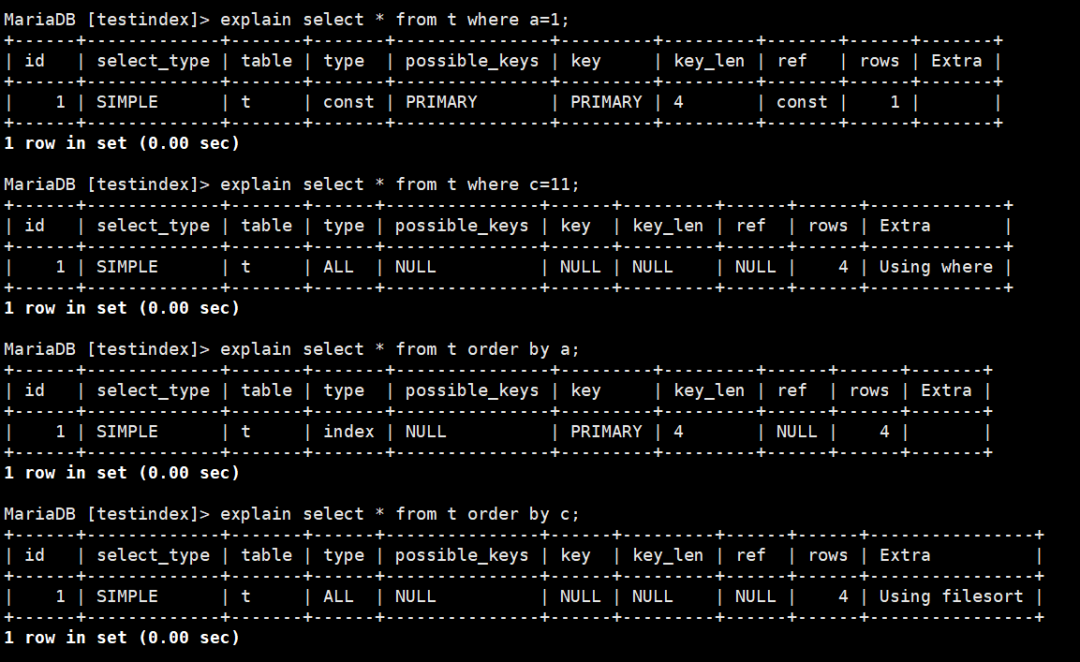
图6:聚集索引查询计划演示
关于explain不太了解的朋友可以参看文末最后一个参考资料
第一个查询我们在a列上做等值查询,第二个在c上做等值查询。从key列可以看到,第一个查询用到了聚集索引,第二个由于c没有索引,所以全表扫描
第三个查询对a做排序,第四个查询对c列做排序。发现对主键的排序不会用filesort.
非聚集索引
非聚集索引(Secondary Index)也叫辅助索引、二级索引、非主键索引。非主键列创建的索引就是这种索引。他的显著特点是叶子节点不包括完整的行数据(如果包括,这是一件多么恐怖的事啊!),而是包含行记录对应的主键key。
还是以上边的表为例,我们在b列创建一个索引。
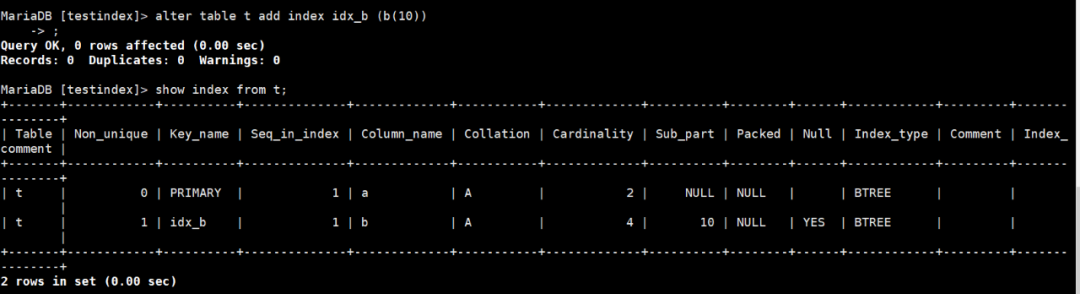
图7:在B列创建索引并查看
注意我们只用了b的前10个字符创建索引,所以你能看到Sub_part这列显示的为10。
此时,idx_b这个索引对应B+树类似下边这种形式
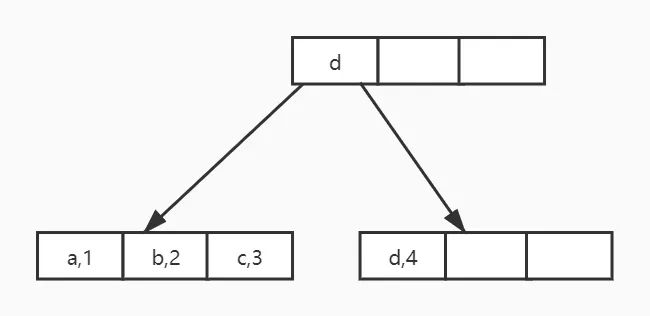
图7:非聚集索引索引树示意图
可以看到叶子节点中的1,2,3,4其实是主键里边的值
在非聚集索引的查找过程是:
先在非聚集索引树找到指定key,同时能得到主键key,拿着主键key到聚集索引里找到对应的行。
拿着主键key到聚集索引找行的过程称为回表,回表有可能避免,详见后文的覆盖索引。
使用非聚集索引的好处:
占用的空间相比聚集索引小,因为他的叶子节点并不包含完整的行数据,只包含主键key
2.查询快,这和聚集索引是类似的,但是效率可能比聚集索引低,因为存在回表过程
缺点:
回表问题,就是要查两棵索引树才能找到数据,当然后面会提到并不是所有用非聚集索引查询都有回表过程。
下边来看几个查询计划
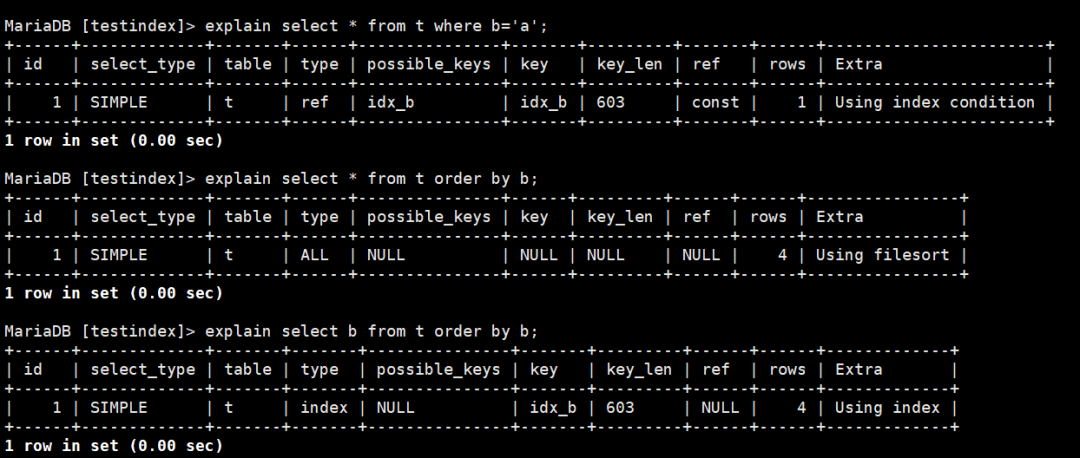
图8:二级索引查询计划
第一个 key为idx_b, 表明用到了非聚集索引,extra是mysql5.6后做的一个优化,Index Push Down优化,简言之就是在使用索引查询时直接通过where条件过滤掉了不符合条件的数据。
第二个演示了按非聚集索引的列做排序的情况,发现会用到filesort,因为没法直接根据索引排序了,需要回表。
第三个和第二个类似,但是他只选择了b这个列,发现没有用filesort.因为不用回表,这个其实就是用到了覆盖索引。
联合索引
联合索引就是索引包含多个列的情况,此时的B+树每个key包含了几个部分,而不是单一值。
继续上边的例子,我们建立b,c列上的联合索引。
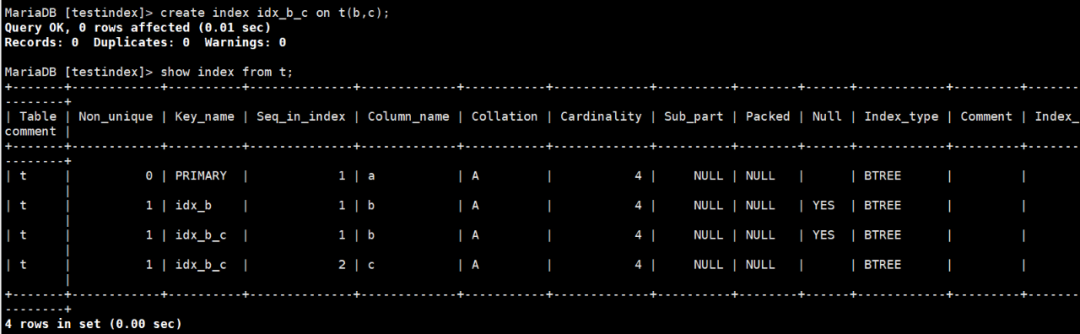
图9:创建联合索引演示
这个索引树可能的形式如下:
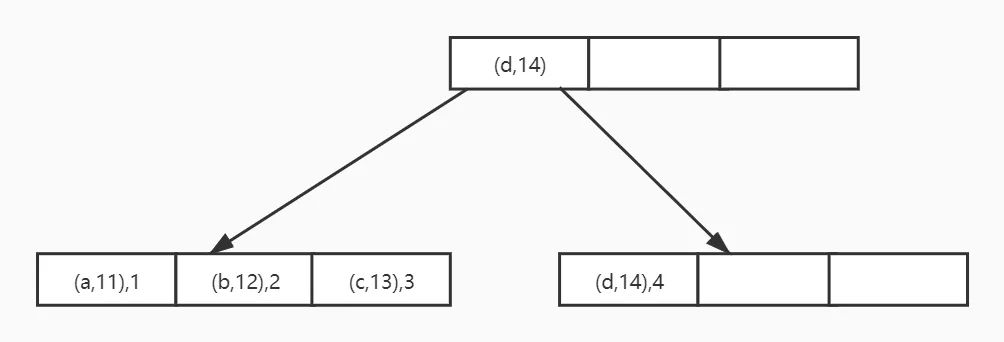
图10:联合索引索引树示意图
这个图画的不太好,其实第二个列在一页里边也可以是无序的
每个key有两个列值组成,叶子节点也是包含了主键key,可见这个联合索引是非聚集索引。当然主键索引也可以包含多个列,自然也可以是联合索引。
联合索引的作用:
对左边的列做查询排序都可以用到这个索引(最左原则)
-- 这里可以假设没有idx_b这个索引select * from t where b='a';select * from t where b='a' and c=11;
左边的列做等值查询,对后边的列做排序友好,因为后边的已经是排序的
-- 这里可以假设没有idx_b这个索引select * from t where b='a' order by c;
让索引包含更多数据,走覆盖索引,一旦放到一个列被索引,那么索引树必包含这个列的数据
对于字符串类型的列,也是满足最左前缀原则,like '%a' 不能命中索引,like 'a%'就可以。
注意下边这个语句用不到索引
select * from t where c=11;
下面看几个查询计划:
先来看一看索引情况
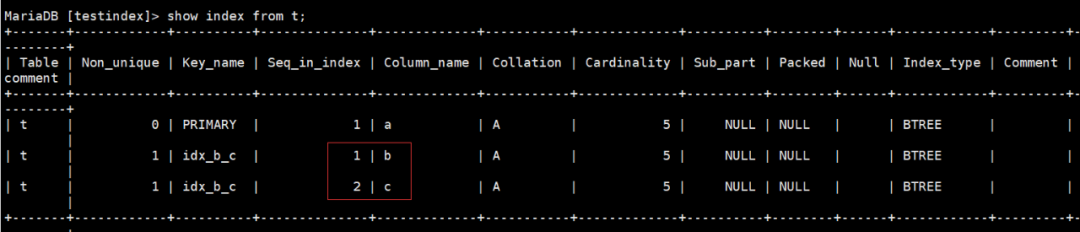
可以看到我们在b,c两列建立了idx_b_c的联合索引
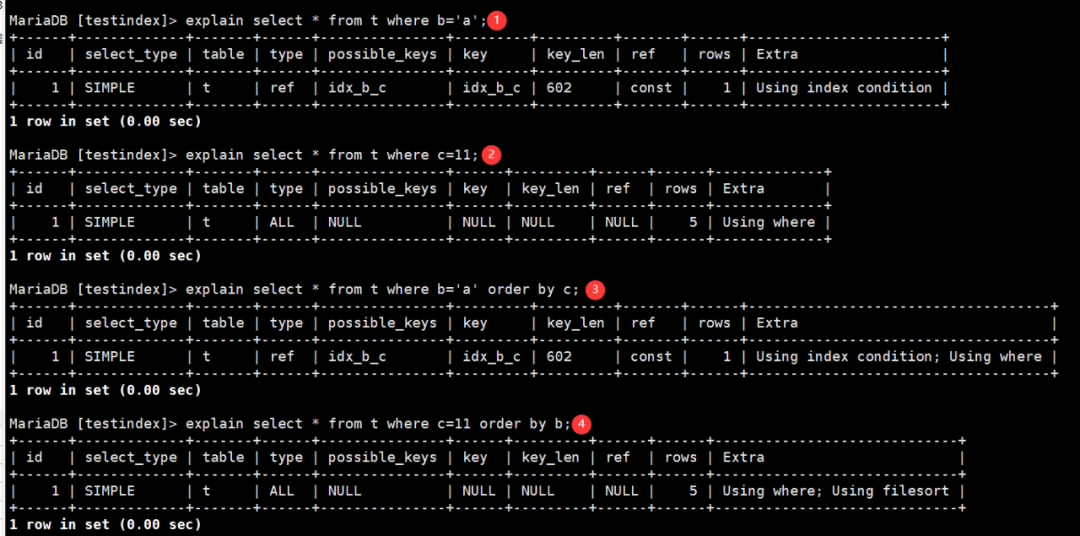
图11:联合索引查询计划
1号查询,条件包含最左列,b列,命中索引
2号查询,条件不包含最左列,key列显示为NULL,未命中索引,type为ALL,是全表扫描
3号查询,对最左列做等值,然后右列做排序,命中了索引
4号查询,没有命中索引,用到了filesort
通过这四个查询我们能够了解到联合索引的最左原则是怎么回事了,结合前面提到的联合索引的树结构,这个原则是理所当然的。
覆盖索引
覆盖的意思就是包含的意思,覆盖索引就是说索引里包含了你需要的数据。
聚集索引直接包含了行数据,因此是覆盖索引,但是一般不这么说。非聚集索引索引数据里边有索引列的列值(这不完全对,后面有说明)。覆盖索引不是一种新的索引结构,只是恰好你要查的数据就在索引树里有,这样就不用回表查询了(非聚集索引叶子节点只有主键key,和索引列值,如果需要其他列值,就需要在通过聚集索引查一次,也就是要走回表)。如果使用了覆盖索引,那么查询计划的Extra列为Using index.
看几个具体的例子:
目前的索引情况如下
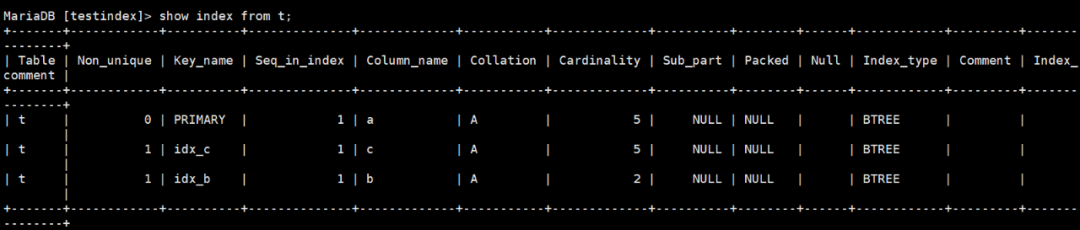
一些执行计划
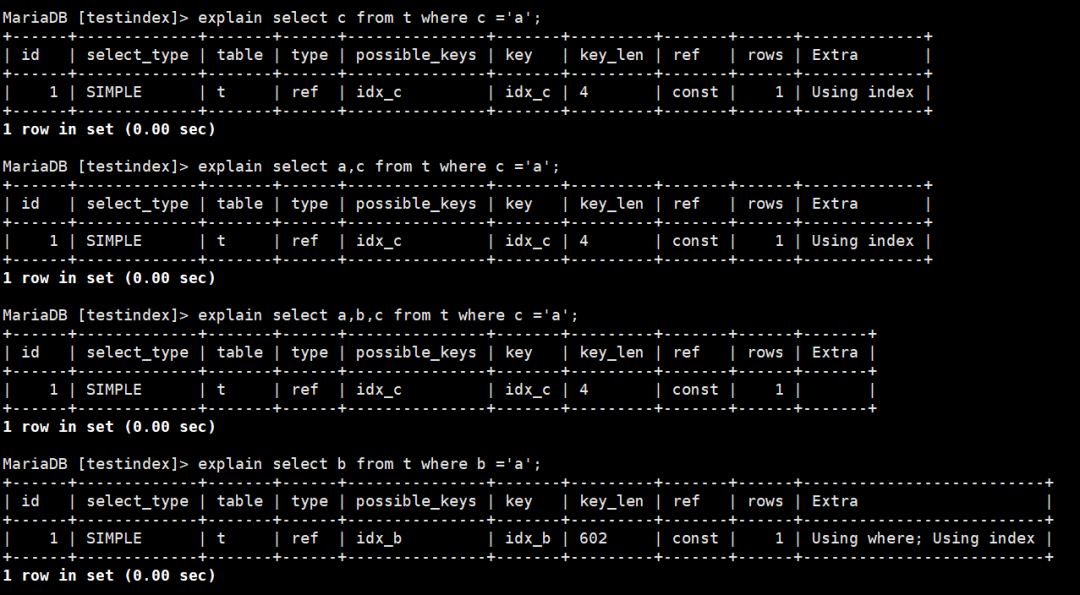
图12:覆盖索引执行计划演示
c的索引包含c列和主键列的值,所以第一第二个查询不需要回表,使用了覆盖索引。
c的索引不包含b列,所以当c列索引查b列时就需要回表了
第四个查询,b列上有索引,索引里边有b列的值,要查的也是b列,索引覆盖了要查询的列,所以也使用了覆盖索引。
需要注意的是,不要忘记了主键列在所有索引都可以被覆盖到。
测试发现一个奇怪的现象,这里分享给大伙儿,一个列的varchar给超过767的长度,然后在上边建索引,会有一个自动的截取。如图所示:
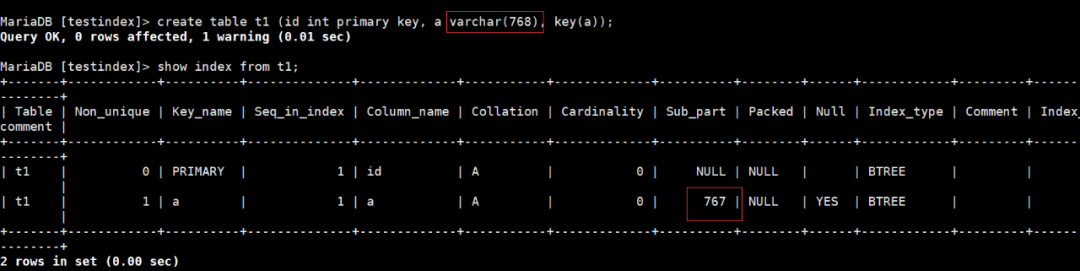
图12:varchar过长索引截取演示
大家可以思考一下,如果你的索引key只是列的一部分,比如,有一个字段为varchar(100), 你的索引只包含前50个字符,这个时候能不能走覆盖索引?
Cardinality
使用show index from 表名时, 可以看到有一个Cardinality列,这个列是衡量我们索引有效性的方式。他的含义是索引列中不重复的行数,Cardinality除以表行数称为索引的选择性,选择性越高越好,选择性小于30%通常认为这个索引建的不好。
Cardinality是一个采样估计值,会随机选择若干页计算每个页平均不同记录的个数,然后乘上页数量。所以可能你每次查到的值不一样,即使你的表没有更新。
这个值并不是每一次表更新都会计算的,他会有自己的一个计算策略。
执行如下语句会导致这个值的重新计算, 当然也可以配置为不进行计算:
analyze table
show table status
show index
B+树索引管理
索引的创建:
建表的时候创建
create table t4
(id int primary key,
a int not null, key(a)
);
通过修改表创建
alter table t4 add index idx_a (a);
通过create index创建
create index idx_a on t4(a);
索引的删除:
修改表删除
alter table t4 drop index idx_a;
drop index语法
drop index idx_a on t4;
索引的查看
show index from t4;
关于索引的思考
学习B+树索引,最最根本是需要弄清楚各种索引树的结构是怎样的,做到“心中有树”。当看到一条优化策略时,我们就能知道这个优化策略为什么能够优化。基于我们对索引结构的理解,甚至还可以提出一些新(对你来讲是新的,但是可能人家已经写了或者在用了)的优化策略。例如,我们知道每一个非聚集索引叶子节点都会包含主键,因此我们的主键应该在满足业务的情况下尽量小,这样可以减少所有索引的空间,当然,事实上,每一个列数据类型都应当尽量小。
索引之路,道阻且长,奥利给!
参考资料
《MySQL技术内幕-InnoDB存储引擎》
https://www.bikan8.cn/186.html
https://blog.csdn.net/why15732625998/article/details/80388236















 2584
2584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









