






背景信息
通义千问-7B(Qwen-7B-Chat)
本工具基于通义千问-7B进行开发,通义千问-7B(Qwen-7B)是阿里云研发的通义千问大模型系列的70亿参数规模模型。Qwen-7B是基于Transformer的大语言模型,在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B 的基础上,使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。
阿里云第八代Intel CPU实例
阿里云八代实例(g8i)采用Intel® Xeon® Emerald Rapids或者Intel® Xeon® Sapphire Rapids,该实例支持使用新的AMX(Advanced Matrix Extensions)指令来加速AI任务。相比于上一代实例,八代实例在Intel® AMX的加持下,推理和训练性能大幅提升。
xFasterTransformer
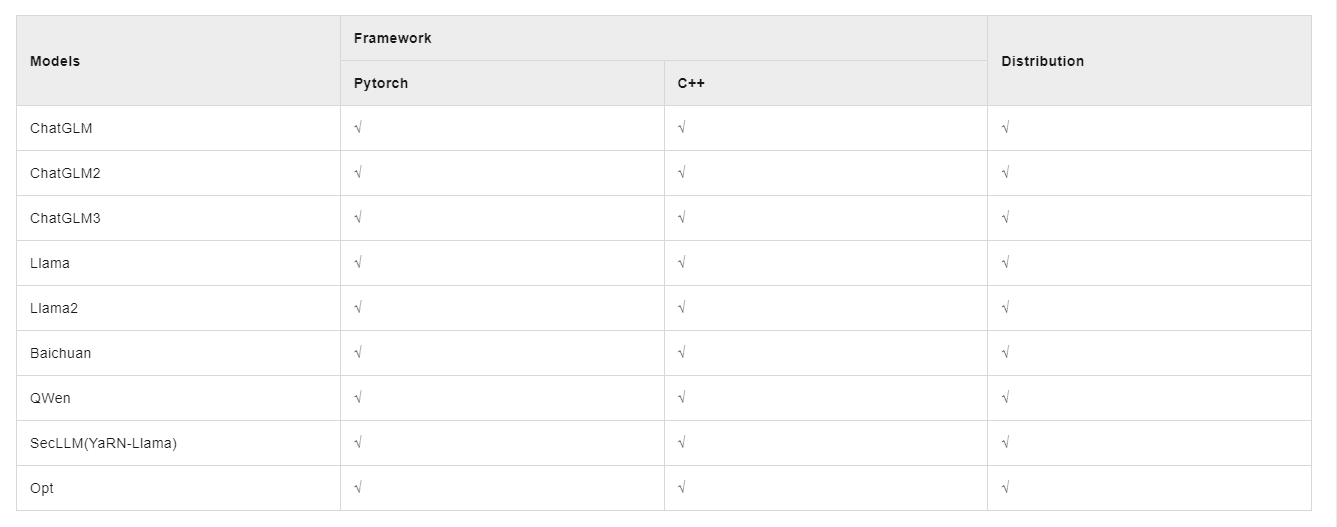
xFasterTransformer是由Intel官方开源的推理框架,为大语言模型(LLM)在CPU X86平台上的部署提供了一种深度优化的解决方案,支持多CPU节点之间的分布式部署方案,使得超大模型在CPU上的部署成为可能。此外,xFasterTransformer提供了C++和Python两种API接口,涵盖了从上层到底层的接口调用,易于用户使用并将xFasterTransformer集成到自有业务框架中。xFasterTransformer目前支持的模型如下:
xFasterTransformer支持多种低精度数据类型来加速模型部署。除单一精度以外,还支持混合精度来更充分的利用CPU的计算资源和带宽资源,来提高大语言模型的推理速度。以下是xFasterTransformer支持的单一精度和混合精度类型:
- FP16
- BF16
- INT8
- W8A8
- INT4
- NF4
- BF16_FP16
- BF16_INT8
- BF16_W8A8
- BF16_INT4
- BF16_NF4
- W8A8_INT8
- W8A8_int4
- W8A8_NF4
环境部署
服务器配置
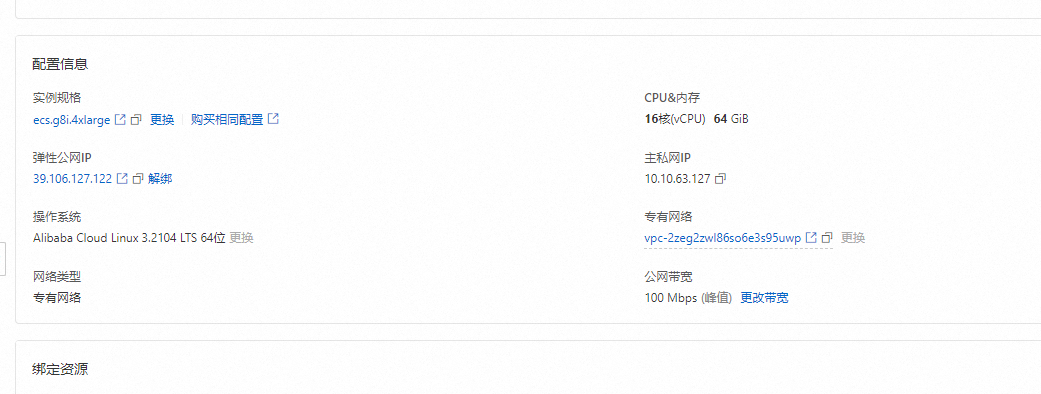
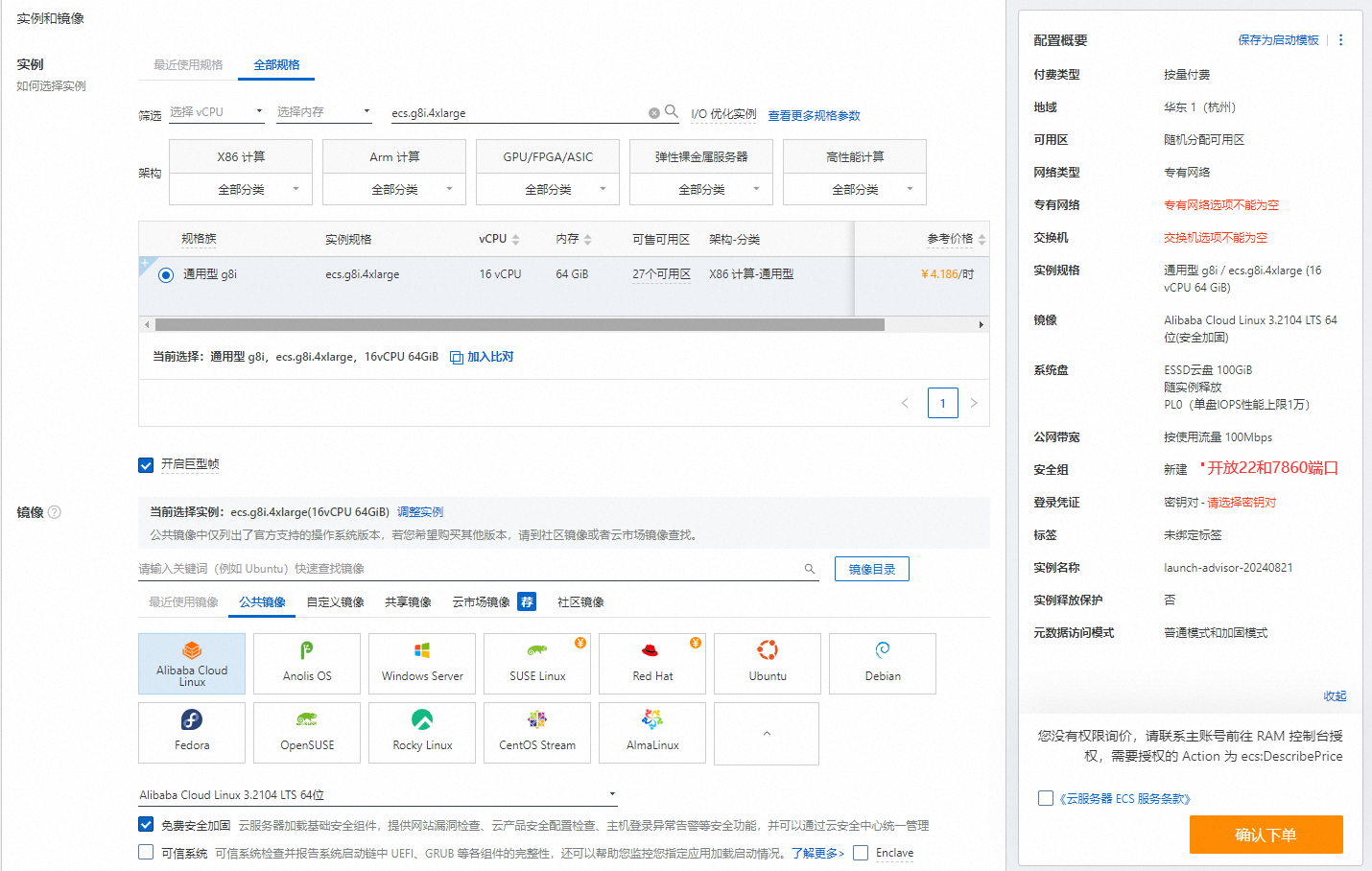
实例:Qwen-7B-Chat运行大概需要16 GiB内存以上,为了保证模型运行的稳定,实例规格至少需要选择ecs.c8i.4xlarge(32 GiB内存)。
镜像:Alibaba Cloud Linux 3.2104 LTS 64位。
公网IP:选中分配公网IPv4地址,带宽计费模式选择按使用流量,带宽峰值设置为100 Mbps。以加快模型下载速度。
系统盘:Qwen-7B-Chat模型数据下载、转换和运行过程中需要占用60 GiB的存储空间,为了保证模型顺利运行,建议系统盘设置为100 GiB。
安全组规则:在ECS实例安全组的入方向添加安全组规则并放行22端口和7860端口(22端口用于访问SSH服务,7860端口用于访问WebUI和API接口)
安装模型所需容器环境
1、远程连接ECS实例。(xshell或者阿里云在线远程连接)
2、安装并启动Docker。(使用的阿里云扩展自动安装docker,详情见:
https://help.aliyun.com/zh/ecs/use-cases/install-and-use-docker-on-a-linux-ecs-instance)

3、获取并运行Intel xFasterTransformer容器。
当出现类似如下信息时,表示已获取并成功运行xFasterTransformer容器。
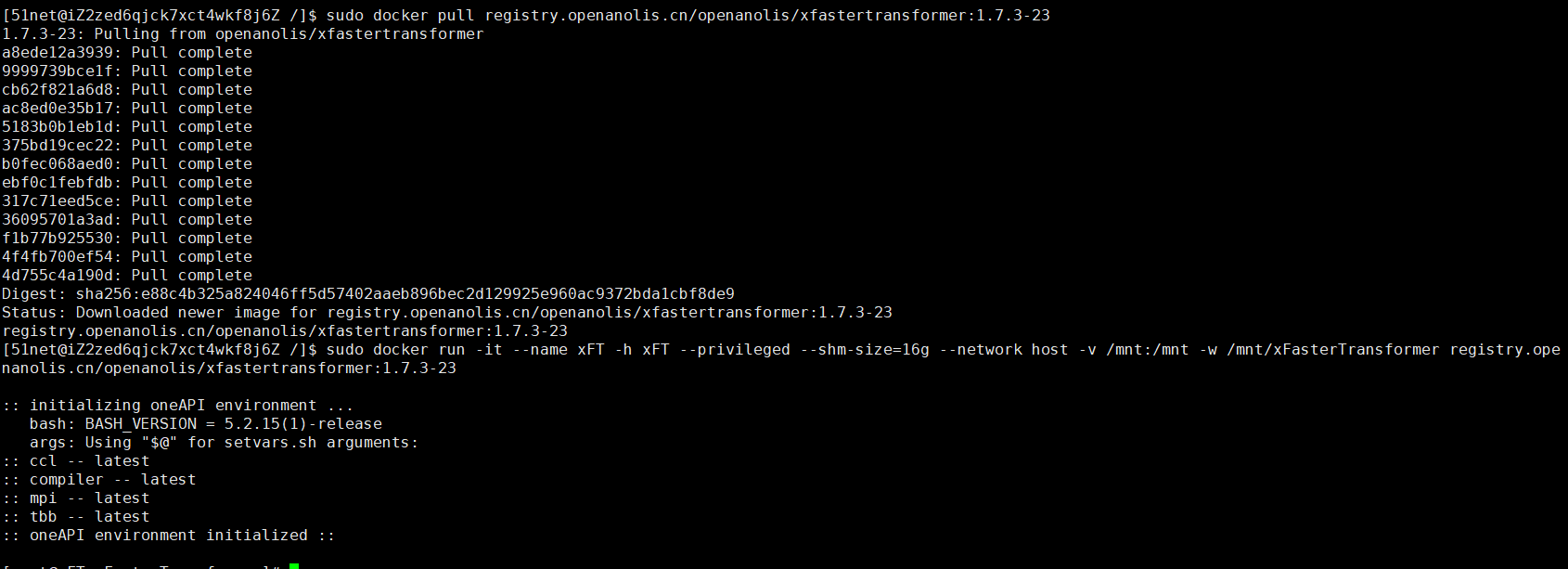
注意:后续操作都需要在容器中运行,如果退出了容器,可以通过以下命令启动并再次进入容器的Shell环境。
准备模型数据
1、在容器中安装依赖软件。
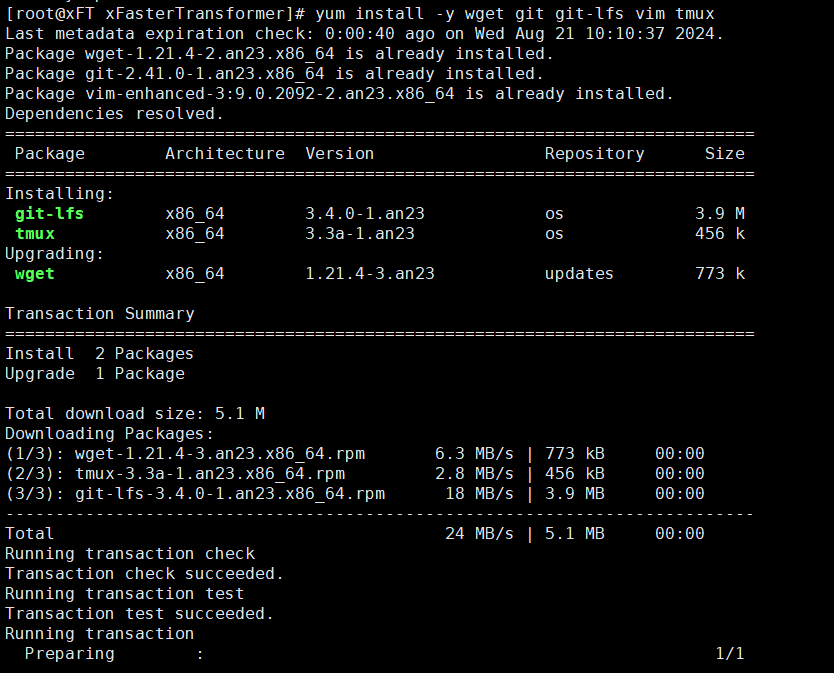
2、启用Git LFS。(下载预训练模型需要Git LFS的支持。)

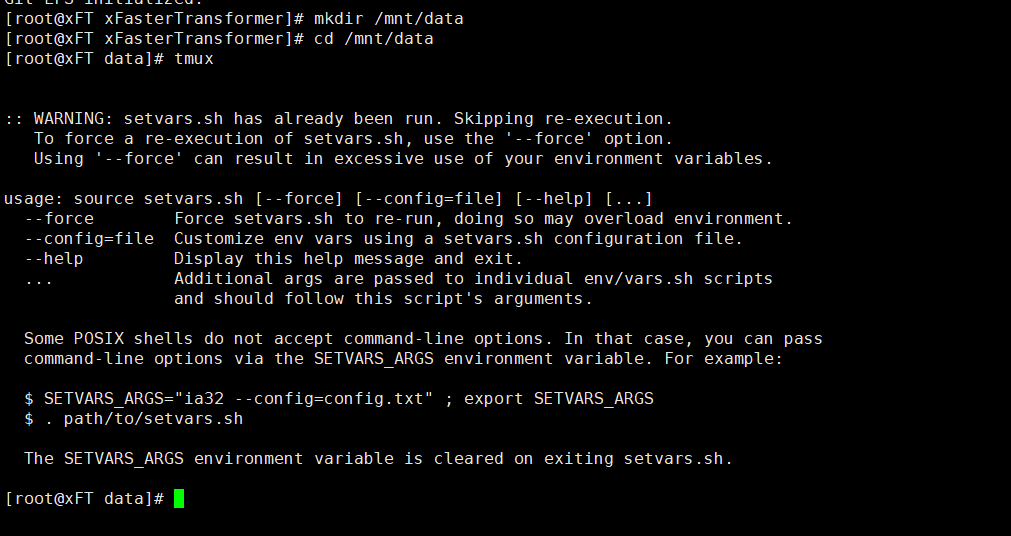
3、创建并进入模型数据目录。
4、创建一个tmux session。
注意:下载预训练模型耗时较长,且成功率受网络情况影响较大,建议在tmux session中下载,以避免ECS断开连接导致下载模型中断。
5、下载Qwen-7B-Chat预训练模型。
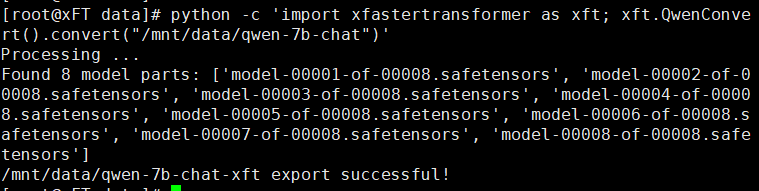
6、转换模型数据。
由于下载的模型数据是HuggingFace格式,需要转换成xFasterTransformer格式。生成的模型文件夹为/mnt/data/qwen-7b-chat-xft。
说明
不同的模型数据使用的Convert类不同,xFasterTransformer支持以下模型转换类:
LlamaConvert
ChatGLMConvert
ChatGLM2Convert
ChatGLM3Convert
OPTConvert
BaichuanConvert
QwenConvert
运行模型
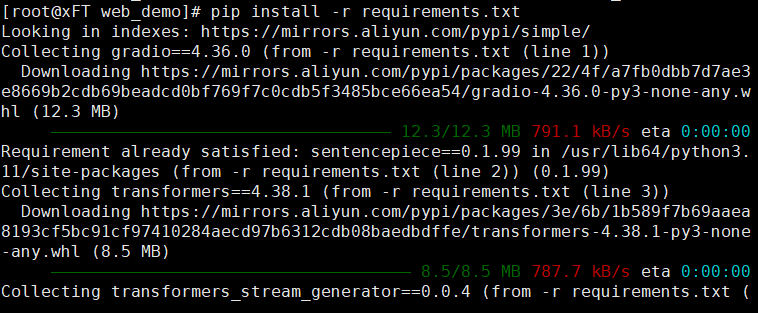
1、在容器中,依次执行以下命令,安装WebUI相关依赖软件。
2、执行以下命令,启动WebUI。
当出现如下信息时,表示WebUI服务启动成功。
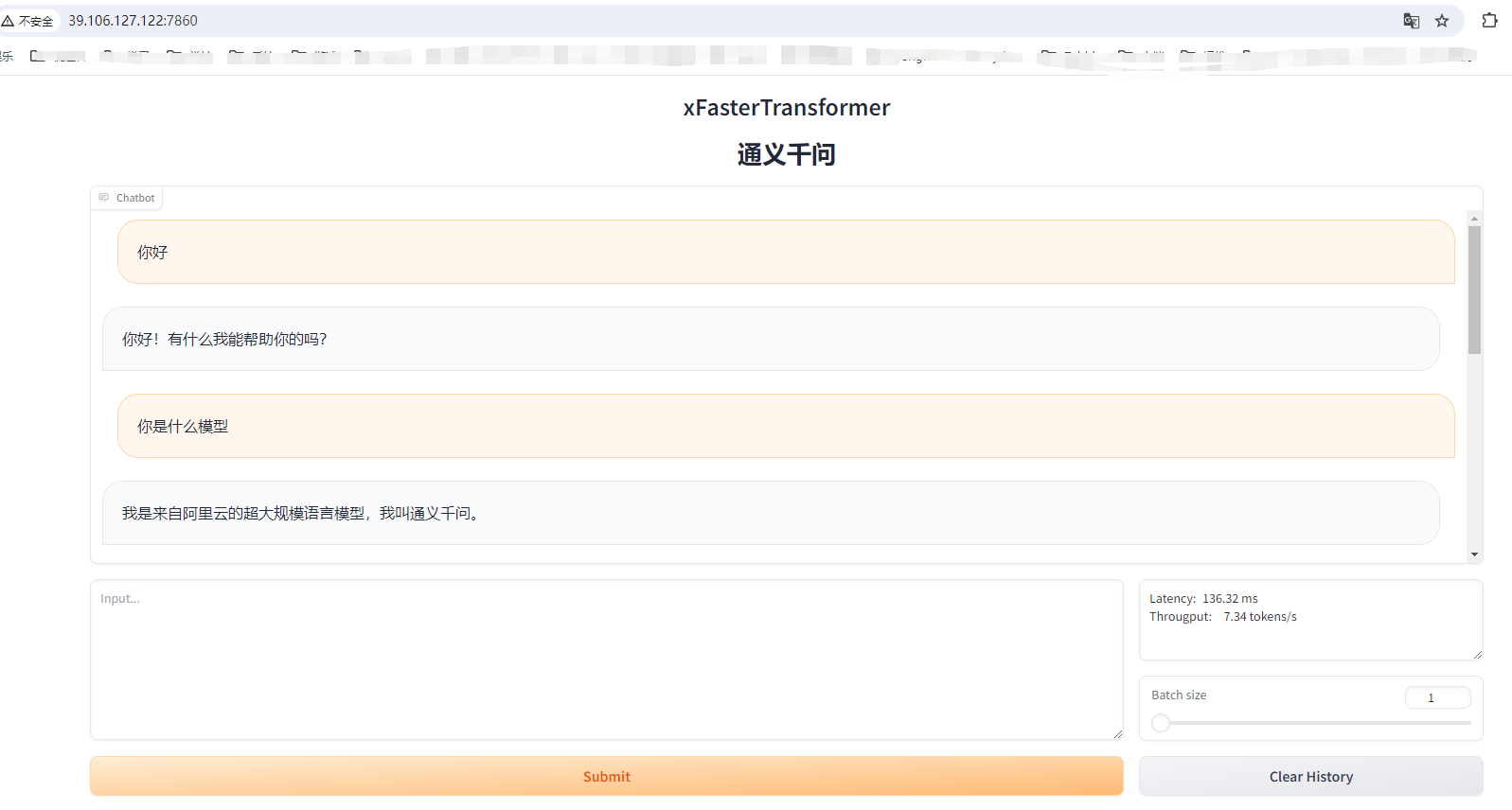
在浏览器地址栏输入http://<ECS公网IP地址>:7860,进入Web页面。
在页面对话框中,输入对话内容,然后单击Submit,即可进行AI对话。
Benchmark模型性能(可选)
运行benchmark脚本时默认使用的是假模型数据,因此不需要准备模型数据。您执行以下指令来测试模型性能。
通过调整运行参数,来测试指定场景下的性能数据:
-d 或 --dtype选择模型量化类型:
- bf16 (default)
- bf16_fp16
- int8
- bf16_int8
- fp16
- bf16_int4
- int4
- bf16_nf4
- nf4
- bf16_w8a8
- w8a8
- w8a8_int8
- w8a8_int4
- w8a8_nf4
-bs或--batch_size选择batch size大小,默认为1。
-in或--input_tokens选择输入长度,自定义长度请在prompt.json中配置对应的prompt,默认为32。
-out或--output_tokens选择生成长度,默认为32。
-i或--iter选择迭代次数,迭代次数越大,等待测试结果的时间越长,默认为10次。
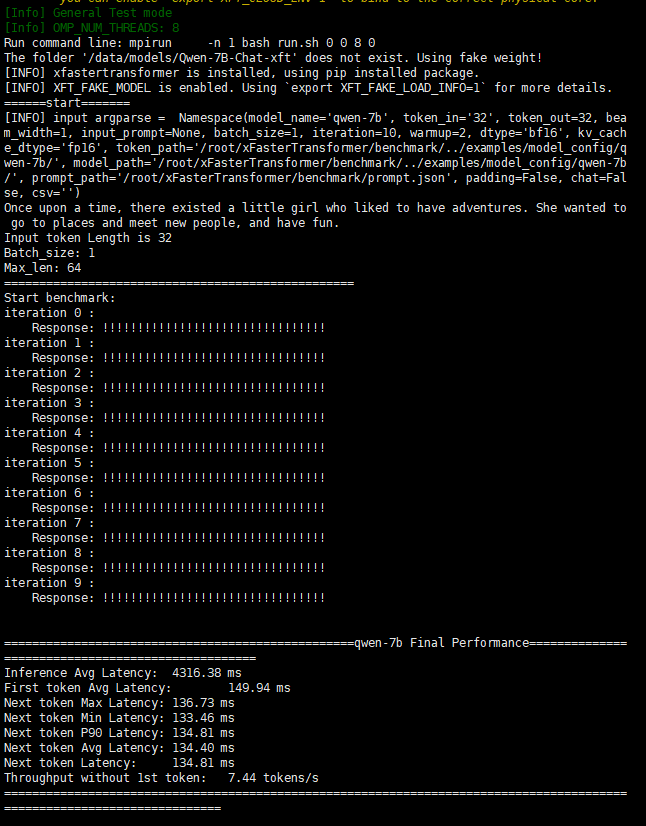
运行结果展示如下:
工具使用
启动工具
在源代码中配置好你的模型API服务,然后编辑器右键运行即可
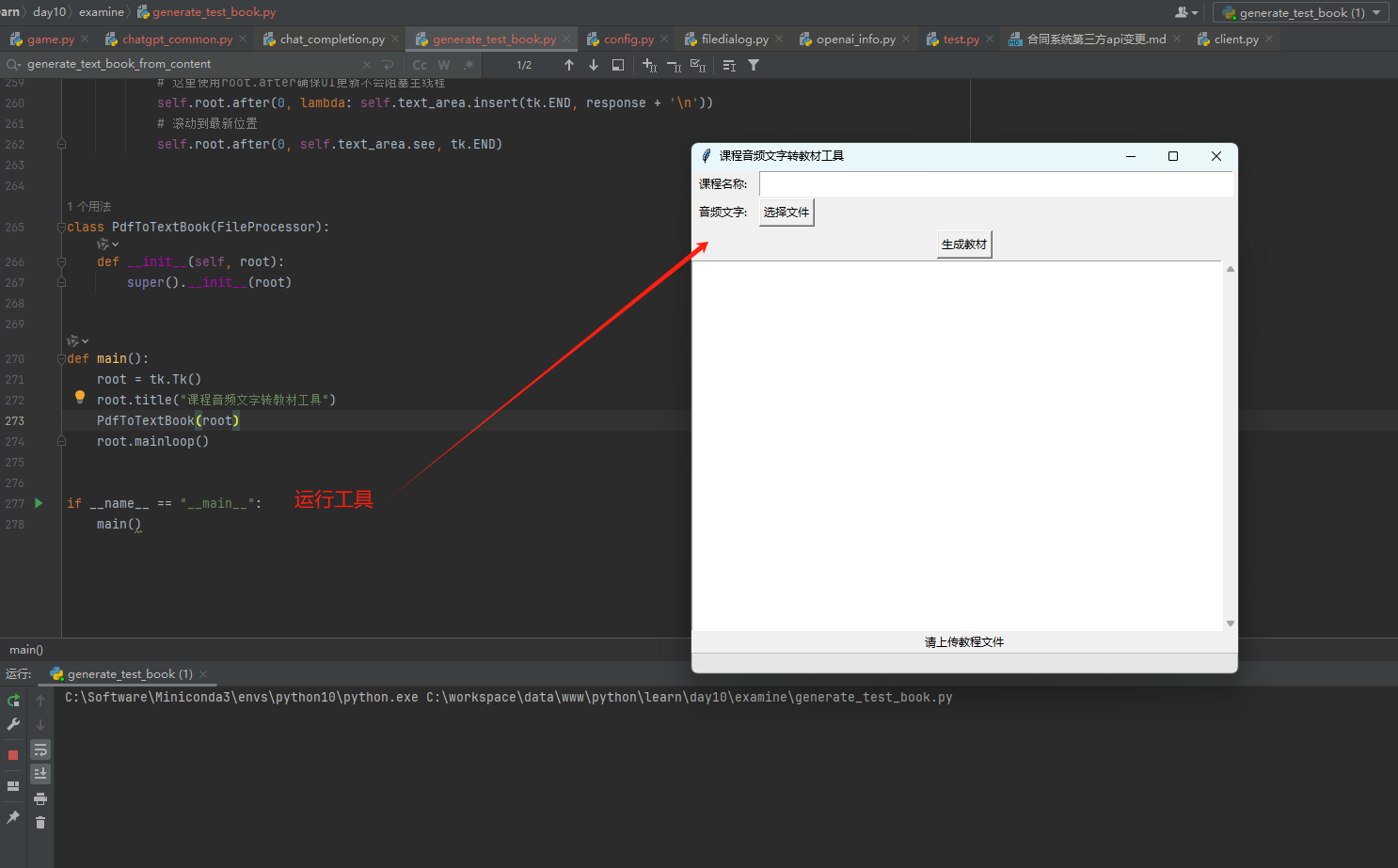
填写信息
填写课程名称,上传对应课程的音频文字文件(目前仅支持txt/pdf/docx格式。),点击“生成教材”开始转换。
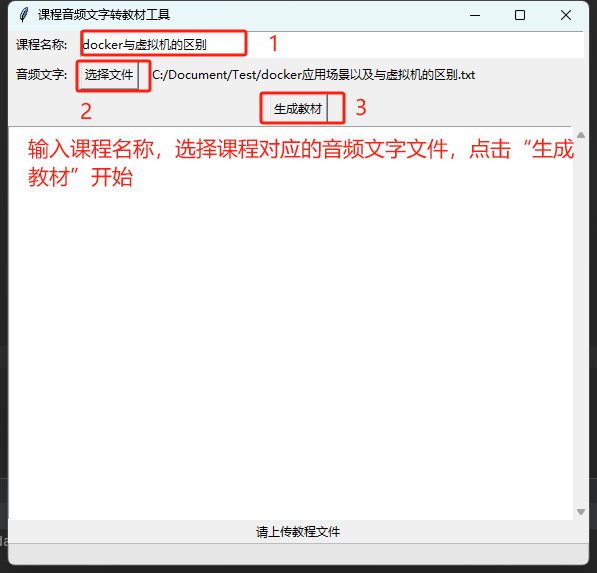
开始转换
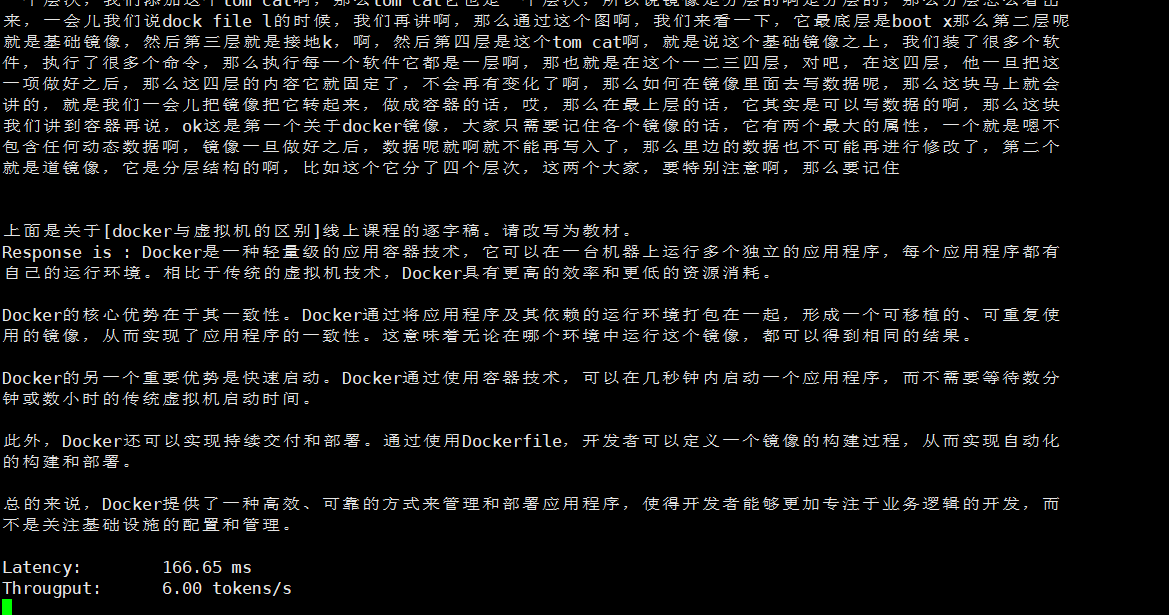
填写完必要信息后,转换后的教材内容会逐步显示在文本区域中,根据进度条查看是否运行完成。
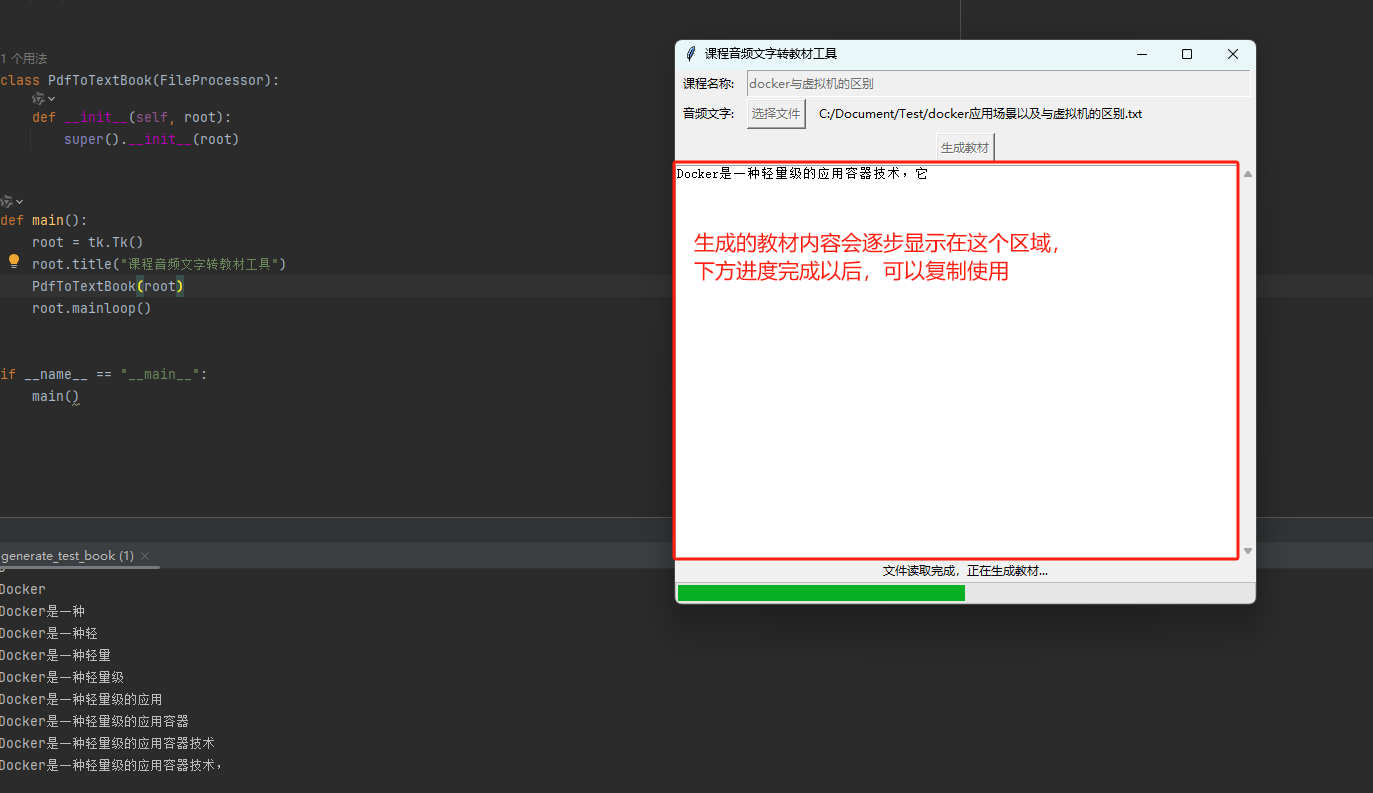
转换完成
转换完成以后可以复制使用,可以看到相比于以前的音频文字更为规范简介。
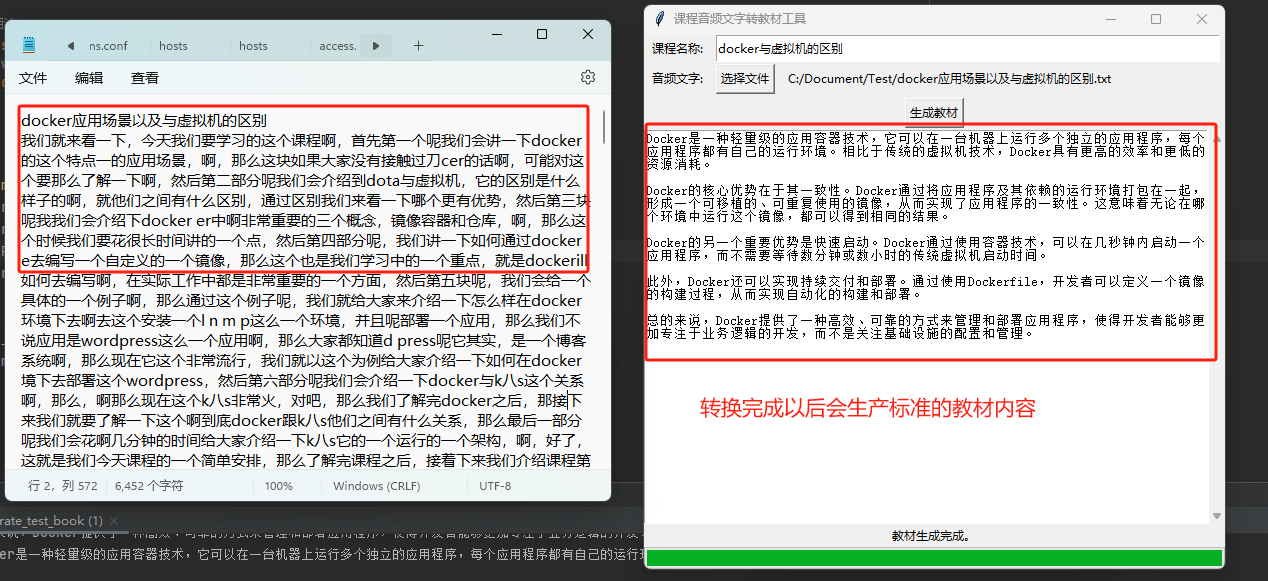
服务日志
模型服务会记录下每一次请求的日志输出,可用于后续的分析或者其他异常情况的排查。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









