






说明:
因为某个磁盘满了,需要将原始文件拷贝到新磁盘。数据非常重要,需要保证拷贝数据与原始数据一致。用cp拷贝完成后,发现文件大小不一致。原始文件夹5.8G(du –max-depth=1查看),拷贝文件夹5.9G,差别相当明显。
实现:
1.最初怀疑是因为不同磁盘的最小计量单位不同导致,以为最小计算单位是sector(其实是错的)。
因此fdisk -l /dev/sda查看了下
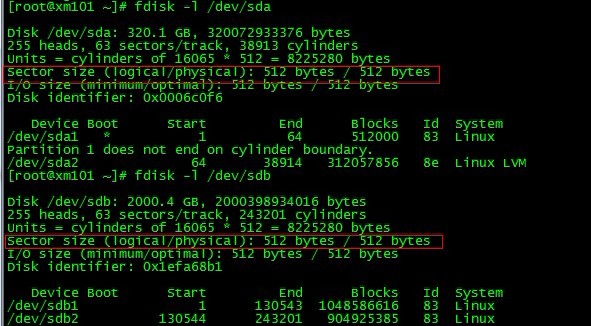
发现两者的扇区是一样的,郁闷。
2.接着怀疑拷贝的文件数,文件大小不一致。于是自己写了个简单的shell脚本,查看每个文件具体大小,不一致的会输出!=
[root@xm101 2012]# cat test.sh
#!/bin/bash
path1=/opt/a/2012/01/20
path2=/opt/b/2012/01/20
for i in `ls $path2`;
do
a=`/bin/ls -l $path1/$i|awk '{print $5}'`
b=`/bin/ls -l $path2/$i|awk '{print $5}'`
sum=`[ "$a" != "$b" ] && echo "!="`
echo $i path1:$a path2:$b $sum >> hello.txt
done
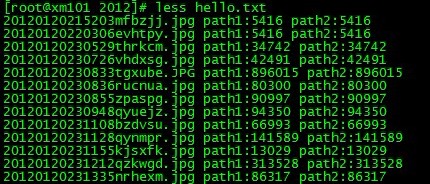
结果发现每个文件大小完全一致,用md5确认(cat * | md5sum),发现原始文件,拷贝文件也是一致的
3.这就纳闷了,突然想起磁盘的最小计量单位应该是block才对,因此。。。。
tune2fs -l /dev/sda1
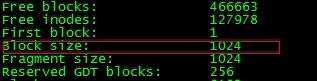
tune2fs -l /dev/sdb1

发现确实是因为这个,绕了一圈又回来了,看来专业水平还要提高
附注:
在查看答案过程中,听说du是按inode来计算文件大小的,因此显示文件大小时速度较快。inode记录了一个文件的起始block,结束block。因此即使文件没有完整占用1个block时,也算1个。也会导致文件大小不一致。
而ls是根据block来计算文件大小的
转载自:linux cp文件大小不一致:http://coolnull.com/443.html















 4588
4588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









