







此文适合于和我一样第一次接触Hadoop的童鞋。
什么是Hadoop?
Hadoop是一种分析和处理大数据的软件平台,是Appach的一个用Java语言所实现的开源软件的框架,在大量计算机组成的集群当中实现了对于海量的数据进行的分布式计算。
它解決了两大问题:大数据存储、大数据分析。也就是 Hadoop 的两大核心:HDFS 和 MapReduce。
HDFS(Hadoop Distributed File System)是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。
MapReduce 为分布式计算框架,包含map(映射)和 reduce(归约)过程,负责在 HDFS 上进行计算。
Hadoop有哪些优点?
(1) 高可靠性 : Hadoop 按位存储和处理数据的能力值得人们信赖。
(2) 高扩展性 : Hadoop 是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以干计的节点中。
(3) 高效性 : Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
(4) 高容错性 : Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分。
(5) 低成本 : 与一体机、商用数据仓库以及 QlikView、 Yonghong Z- Suites 等数据集市相比,Hadoop 是开源的,项目的软件成本因此会大大降低。
Hadoop 存储 - HDFS
Hadoop 的存储系统是 HDFS(Hadoop Distributed File System)分布式文件系统,对外部客户端而言,HDFS 就像一个传统的分级文件系统,可以进行创建、删除、移动或重命名文件或文件夹等操作,与 Linux 文件系统类似。
HDFS各个组件的概念:
(1)名称节点(NameNode)
它是一个通常在HDFS架构中单独机器上运行的组件,负责管理文件系统名称空间和控制外部客户机的访问。NameNode决定是否将文件映射到DataNode上的复制块上。
(2)数据节点(DataNode)
数据节点也是一个通常在HDFS架构中的单独机器上运行的组件。Hadoop集群包含一个NameNode和大量DataNode。数据节点通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。
(3)第二名称节点(Secondary NameNode)
第二名称节点的作用在于为HDFS中的名称节点提供一个Checkpoint,它只是名称节点的一个助手节点。
HDFS原理图如下:
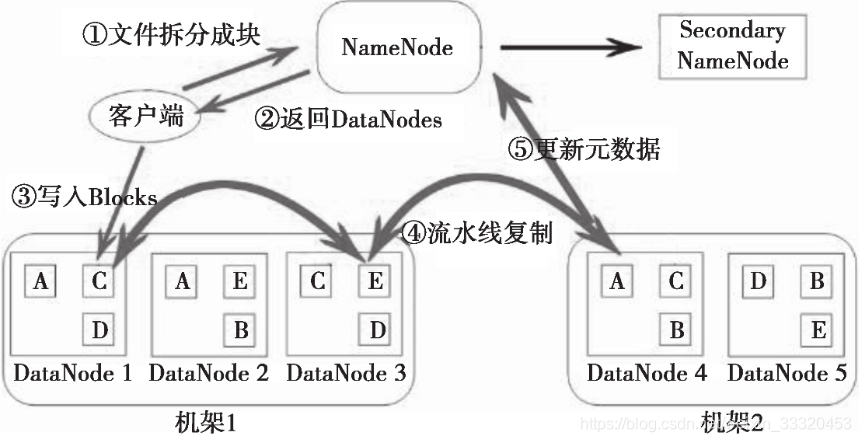
文件在客户端时会被分块,这里可以看到文件被分为 5 个块,分别是:A、B、C、D、E。同时为了负载均衡,所以每个节点有 3 个块。下面来看看具体步骤:
1.客户端将要上传的文件按 128M 的大小分块。
2.客户端向名称节点发送写数据请求。
3.名称节点记录各个 DataNode 信息,并返回可用的 DataNode 列表。
4.客户端直接向 DataNode 发送分割后的文件块,发送过程以流式写入。
5.写入完成后,DataNode 向 NameNode 发送消息,更新元数据。
Hadoop 计算 — MapReduce
MapReduce 是 Google 提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。
一般的 MapReduce 程序会经过以下几个过程:输入(Input)、输入分片(Splitting)、Map阶段、Shuffle阶段、Reduce阶段、输出(Final result)。
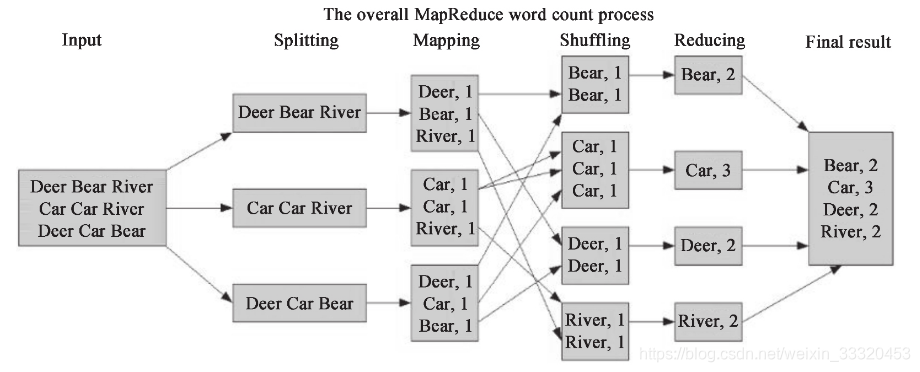
1.输入就不用说了,数据一般放在 HDFS 上面就可以了,而且文件是被分块的。关于文件块和文件分片的关系,在输入分片中说明。
2.输入分片:在进行 Map 阶段之前,MapReduce 框架会根据输入文件计算输入分片(split),每个输入分片会对应一个 Map 任务,输入分片往往和 HDFS 的块关系很密切。例如,HDFS 的块的大小是 128M,如果我们输入两个文件,大小分别是 27M、129M,那么 27M 的文件会作为一个输入分片(不足 128M 会被当作一个分片),而 129MB 则是两个输入分片(129-128=1,不足 128M,所以 1M 也会被当作一个输入分片),所以,一般来说,一个文件块会对应一个分片。如图 1-7 所示,Splitting 对应下面的三个数据应该理解为三个分片。
3.Map 阶段:这个阶段的处理逻辑其实就是程序员编写好的 Map 函数,因为一个分片对应一个 Map 任务,并且是对应一个文件块,所以这里其实是数据本地化的操作,也就是所谓的移动计算而不是移动数据。如图 1-7 所示,这里的操作其实就是把每句话进行分割,然后得到每个单词,再对每个单词进行映射,得到单词和1的键值对。
4.Shuffle 阶段:这是“奇迹”发生的地方,MapReduce 的核心其实就是 Shuffle。那么 Shuffle 的原理呢?Shuffle 就是将 Map 的输出进行整合,然后作为 Reduce 的输入发送给 Reduce。简单理解就是把所有 Map 的输出按照键进行排序,并且把相对键的键值对整合到同一个组中。如图 1-7 所示,Bear、Car、Deer、River 是排序的,并且 Bear 这个键有两个键值对。
5.Reduce 阶段:与 Map 类似,这里也是用户编写程序的地方,可以针对分组后的键值对进行处理。如图 1-7 所示,针对同一个键 Bear 的所有值进行了一个加法操作,得到 <Bear,2> 这样的键值对。
6.输出:Reduce 的输出直接写入 HDFS 上,同样这个输出文件也是分块的。














 1526
1526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









