






统计文件的字符数、单词数以及总行数,包括:
每行的字符数和单词数
文件的总字符数、总单词数以及总行数
注意:
空白字符(空格和tab缩进)不计入字符总数;
单词以空格为分隔;
不考虑一个单词在两行的情况;
限制每行的字符数不能超过1000。
请先看代码:
#include
#include
int *getCharNum(char *filename, int *totalNum);
int main(){
char filename[30];
// totalNum[0]: 总行数 totalNum[1]: 总字符数 totalNum[2]: 总单词数
int totalNum[3] = {0, 0, 0};
printf("Input file name: ");
scanf("%s", filename);
if(getCharNum(filename, totalNum)){
printf("Total: %d lines, %d words, %d chars\n", totalNum[0], totalNum[2], totalNum[1]);
}else{
printf("Error!\n");
}
return 0;
}
/**
* 统计文件的字符数、单词数、行数
*
* @param filename 文件名
* @param totalNum 文件统计数据
*
* @return 成功返回统计数据,否则返回NULL
**/
int *getCharNum(char *filename, int *totalNum){
FILE *fp; // 指向文件的指针
char buffer[1003]; //缓冲区,存储读取到的每行的内容
int bufferLen; // 缓冲区中实际存储的内容的长度
int i; // 当前读到缓冲区的第i个字符
char c; // 读取到的字符
int isLastBlank = 0; // 上个字符是否是空格
int charNum = 0; // 当前行的字符数
int wordNum = 0; // 当前行的单词数
if( (fp=fopen(filename, "rb")) == NULL ){
perror(filename);
return NULL;
}
printf("line words chars\n");
// 每次读取一行数据,保存到buffer,每行最多只能有1000个字符
while(fgets(buffer, 1003, fp) != NULL){
bufferLen = strlen(buffer);
// 遍历缓冲区的内容
for(i=0; i
c = buffer[i];
if( c==' ' || c=='\t'){ // 遇到空格
!isLastBlank && wordNum++; // 如果上个字符不是空格,那么单词数加1
isLastBlank = 1;
}else if(c!='\n'&&c!='\r'){ // 忽略换行符
charNum++; // 如果既不是换行符也不是空格,字符数加1
isLastBlank = 0;
}
}
!isLastBlank && wordNum++; // 如果最后一个字符不是空格,那么单词数加1
isLastBlank = 1; // 每次换行重置为1
// 一行结束,计算总字符数、总单词数、总行数
totalNum[0]++; // 总行数
totalNum[1] += charNum; // 总字符数
totalNum[2] += wordNum; // 总单词数
printf("%-7d%-7d%d\n", totalNum[0], wordNum, charNum);
// 置零,重新统计下一行
charNum = 0;
wordNum = 0;
}
return totalNum;
}
运行程序,输出结果为:
linuxidc@linuxidc:~/www.linuxidc.com$ ./linuxidc.com
Input file name: linuxidc.txt
line words chars
1 84 816
2 82 708
3 36 359
Total: 3 lines, 202 words, 1883 chars
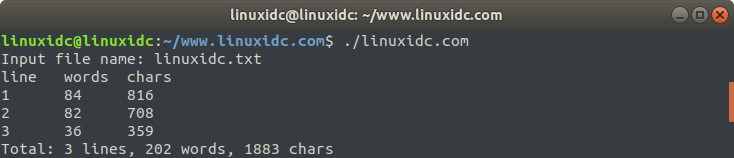
上面的程序,每次从文件中读取一行,放到缓冲区buffer,然后遍历缓冲区,统计当前行的字符和单词数。
fgets()函数用于从文件中读取一行或指定个数的字符,其原型为:
char * fgets(char *buffer, int size, FILE * stream);
参数说明:
buffer为缓冲区,用来保存读取到的数据。
size为要读取的字符的个数。如果该行字符数大于size-1,则读到 size-1 个字符时结束,并在最后补充' \0';如果该行字符数小于等于 size-1,则读取所有字符,并在最后补充 '\0'。即,每次最多读取 size-1 个字符。读取的字符包括换行符。
stream为文件指针。
有的读者问,为什么不使用getc(),每次从文件中读取一个字符,也无需开辟缓冲区。
这样没有问题,但是在处理换行时要注意跨平台问题,因为不同的平台对文本文件换行的处理不一样,Linux以'\n'为换行符,Windows以'\n\r'为换行符,Mac又以'\r\n'为换行符。所以,使用getc()函数处理换行时比较麻烦。
这里去繁就简,通过fgets()读取整行数据,然后再处理每个字符,直接忽略'\n'和'\r'。
注意:由于每行的结尾会有最多2个字节长度的换行符,fgets()还会添加NUL,所以缓冲区的长度至少为1003,才能容纳每行1000个字符,否则strlen()可能返回垃圾值。
请看代码第43行,打开文件出错时,返回NULL,而不是生硬的exit()。这样可以通知主调函数发生了错误,让主调函数做出适当的处理,或者通知用户,提高软件的用户体验。















 9809
9809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









