






作者: 小子
时间: July 10, 2017
背景
使用magenetico抓取磁力链接,由于它使用的是sqlite3, 文件会越来越大,而且不支持分布式;所以需要将其改造成MySQL,在迁移之前需要将已经抓取的15G数据导入到MySQL
从sqlite3文件dump出sqlsqlite3 database.sqlite3
sqlite3> .output /path/to/dump.sql
sqlite3> .dump
sqlite3> .exit
切分文件
文件比较大的时候,很有导入到一半的时候失败,这个时候需要从失败的行开始切分出一个新的sql文件来awk '{if (NR>=6240863) print $0>"dump_part.sql"}' dump.sql
mysql参数修改[mysqld]
max_allowed_packet = 100M
sql兼容, 符号替换# 1. 删除不包含 INSERT INTO 的行
# 2. 替换表名 wrap
# 3. 替换 hex
sed '/INSERT INTO/!d;s/"table1"/`table1`/;s/"table2"/`table2`/;s/,X/,/' dump.sql
导入到MySQL# 加上 force 参数, 防止部分有问题的sql阻止导入
mysql -uroot -p -f magnet < dump.sql
引用
作者: 小子
时间: June 4, 2017
这是在团队内部做的一个分享,PPT见附件键盘设置
开发工具集合
Bash/Zsh快捷键
iTerm自定义快捷键
iTerm快捷键
更好的展示git diff
更好的搜索代码the_silver_search
Sublime Text快捷键 & Sublime Text设置
IntelliJ IDEA插件 & 快捷键
Chrome插件
Sequel Pro插件 & console窗口的使用
alias
作者: 小子
时间: April 23, 2017
调用流程
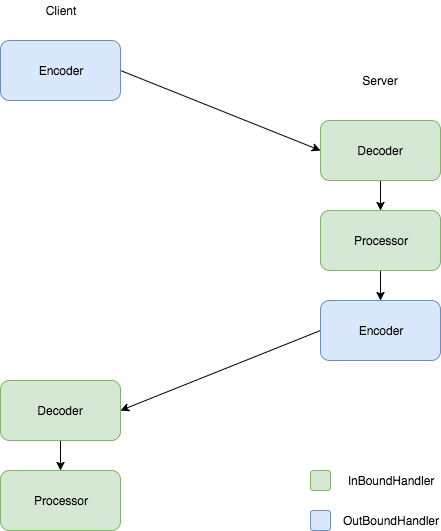
motan的协议设计
包括 request 级别的 header 和 body,request 的 body 中又包含了 header 和 body; 其中 requestId, request/response 的标记是冗余的
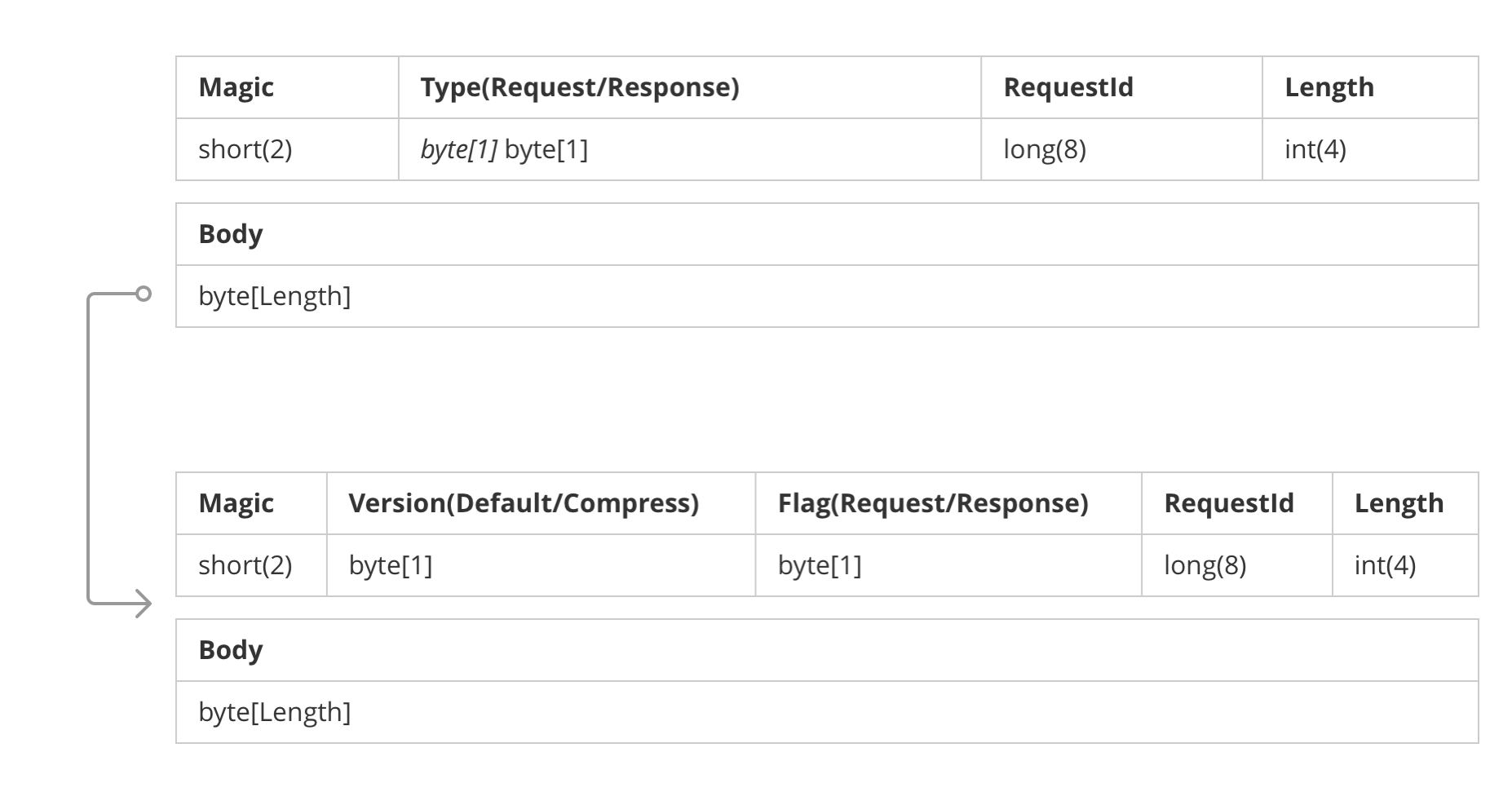
dubbo的协议设计

Server参数的优化bootstrap.option(ChannelOption.SO_BACKLOG, 128); // 3次握手连接队列
bootstrap.childOption(ChannelOption.SO_KEEPALIVE, true); // 默认false
bootstrap.childOption(ChannelOption.TCP_NODELAY, true);
Decoder
 public class MessageDecoder extends ByteToMessageDecoder {
public class MessageDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf, List list) throws Exception {
if (byteBuf.readableBytes() <= MessageConstant.HEADER_LEN) {
return;
}
byteBuf.markReaderIndex();
short type = byteBuf.readShort();
if (type != MessageConstant.MAGIC_TYPE) {
byteBuf.resetReaderIndex();
throw new Exception("error magic type");
}
byte messageType = (byte) byteBuf.readShort();
long requestId = byteBuf.readLong();
int dataLength = byteBuf.readInt();
if (byteBuf.readableBytes() < dataLength) {
byteBuf.resetReaderIndex();
return;
}
byte[] data = new byte[dataLength];
byteBuf.readBytes(data, 0, dataLength);
// debug
String r = new String(data, StandardCharsets.UTF_8);
System.out.println(r);
list.add(new Message(r));
}
}
参考
作者: 小子
时间: April 15, 2017
背景
在做技术分享的时候,经常需要去展示自己的代码;下面是整理的需求:代码高亮显示
在能看清代码的情况下,容纳代码的上下文
做法
代码高亮IDE代码高亮截图
使用RTF格式插入文字格式的高亮代码
看清代码
放大局部代码
1. 使用截图的方式
优点:制作方便
缺点:在演讲屏幕比较大的时候,代码显示会比较模糊
因为代码已经变成了图片,所以不能copy和编辑
1、打开IDEA的演示模式 View - Enter Presentation Mode,截图放入Keynote
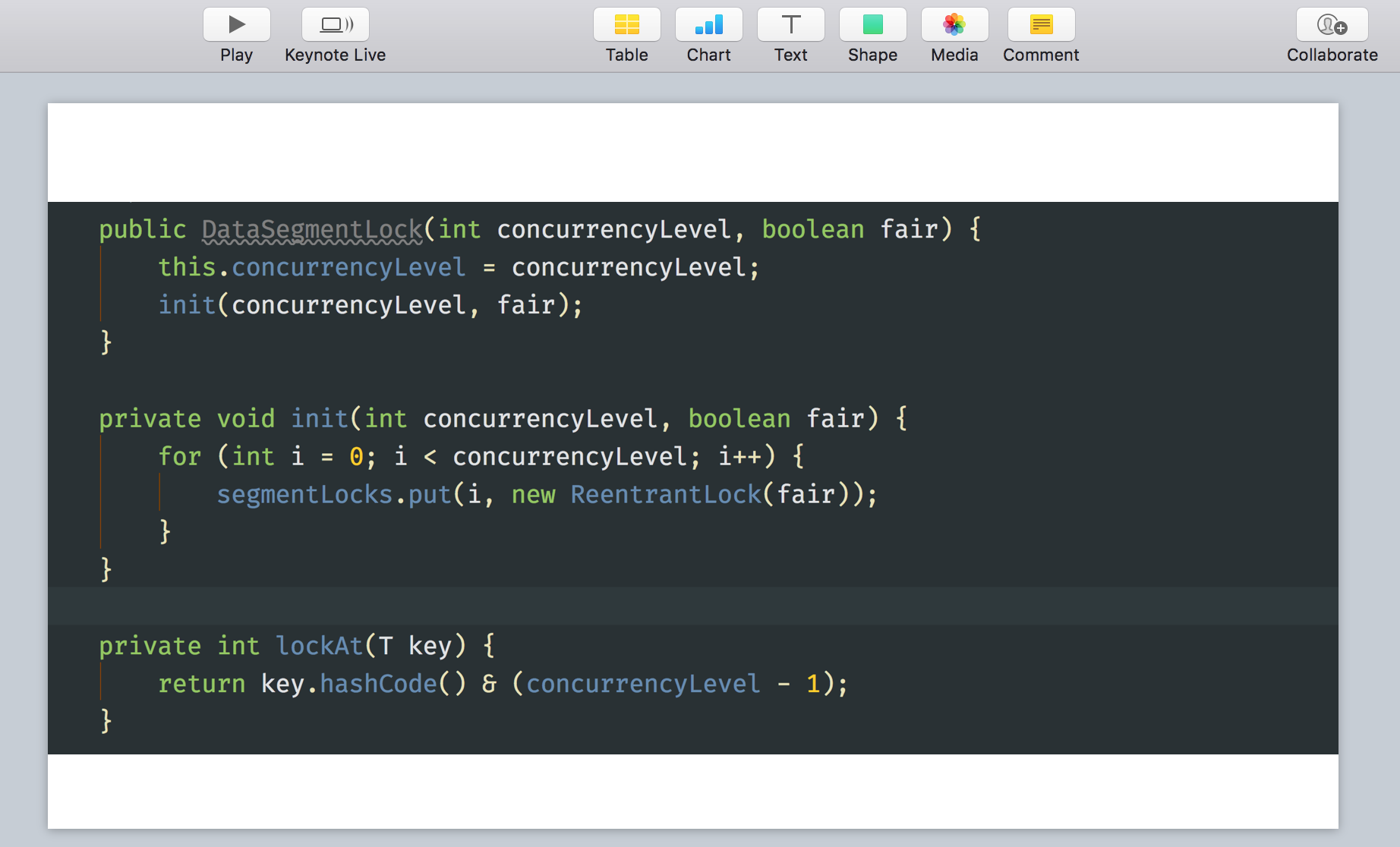
2、第二张幻灯片放大代码图片, 添加两个形状,遮挡不需要展示的代码
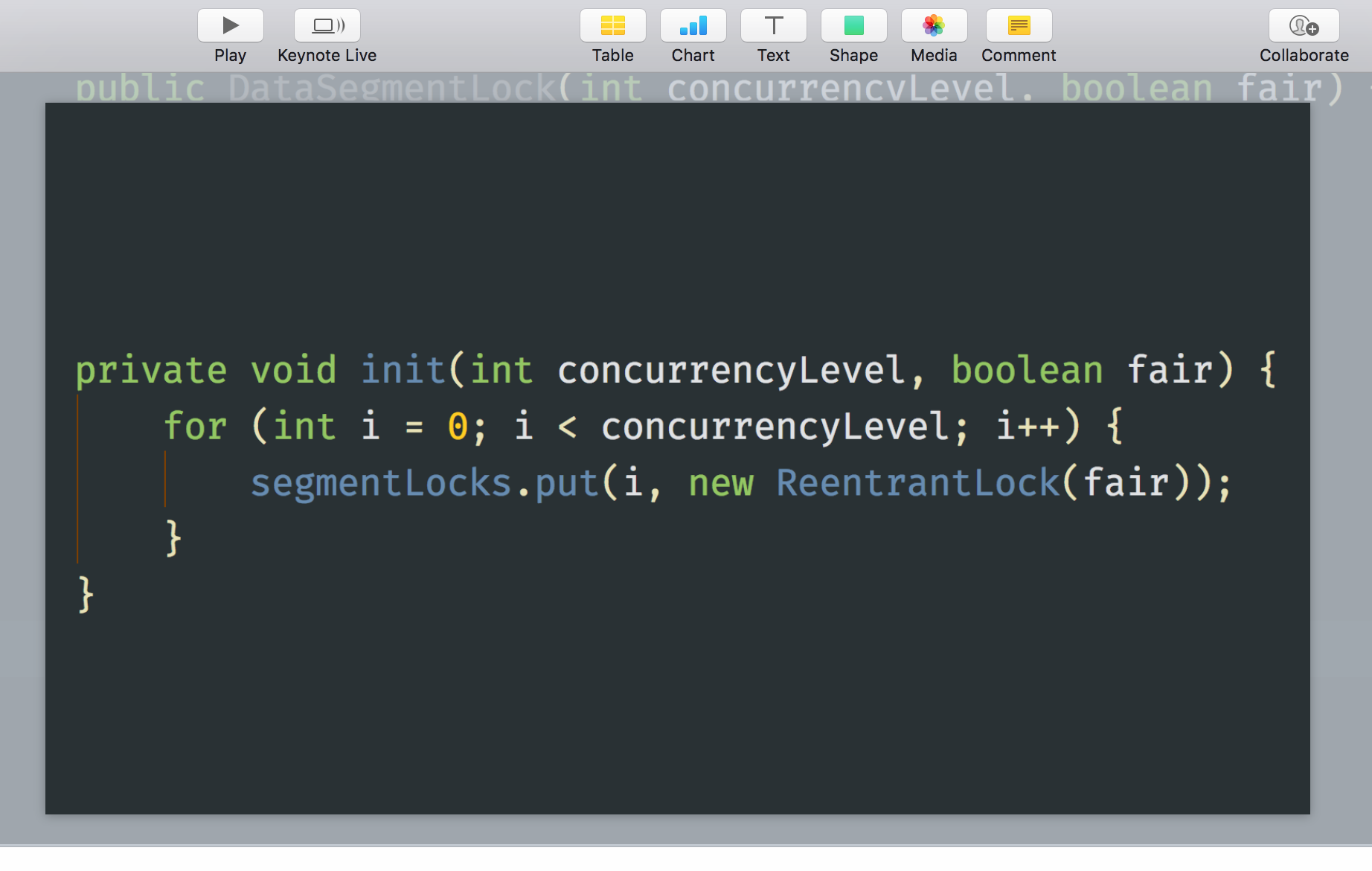
3、设置效果神奇移动
2. 使用RTF格式的方式
优点:清晰度不受屏幕大小的影响
代码可copy,可编辑
缺点:准备工作麻烦
1、安装代码高亮工具brew install highlight
2、copy代码或者创建需要展示的代码文件# 如果是copy的代码
# 注意需要指定 --syntax 扩展名
# -u 编码,否则中文会乱码
# -t 最好将代码中的tab转换成空格,keynote中\t的展示宽度可能会不一致
pbpaste | highlight --syntax=sh --style=github -k "Fira Code" -K 18 -u "utf-8" -t 4 -O rtf | pbcopy
# 如果是文件中的代码
highlight --style=github -k "Fira Code" -K 18 -u "utf-8" -t 4 -O rtf | pbcopy
3、直接在keynote中粘贴代码
4、设置效果神奇移动
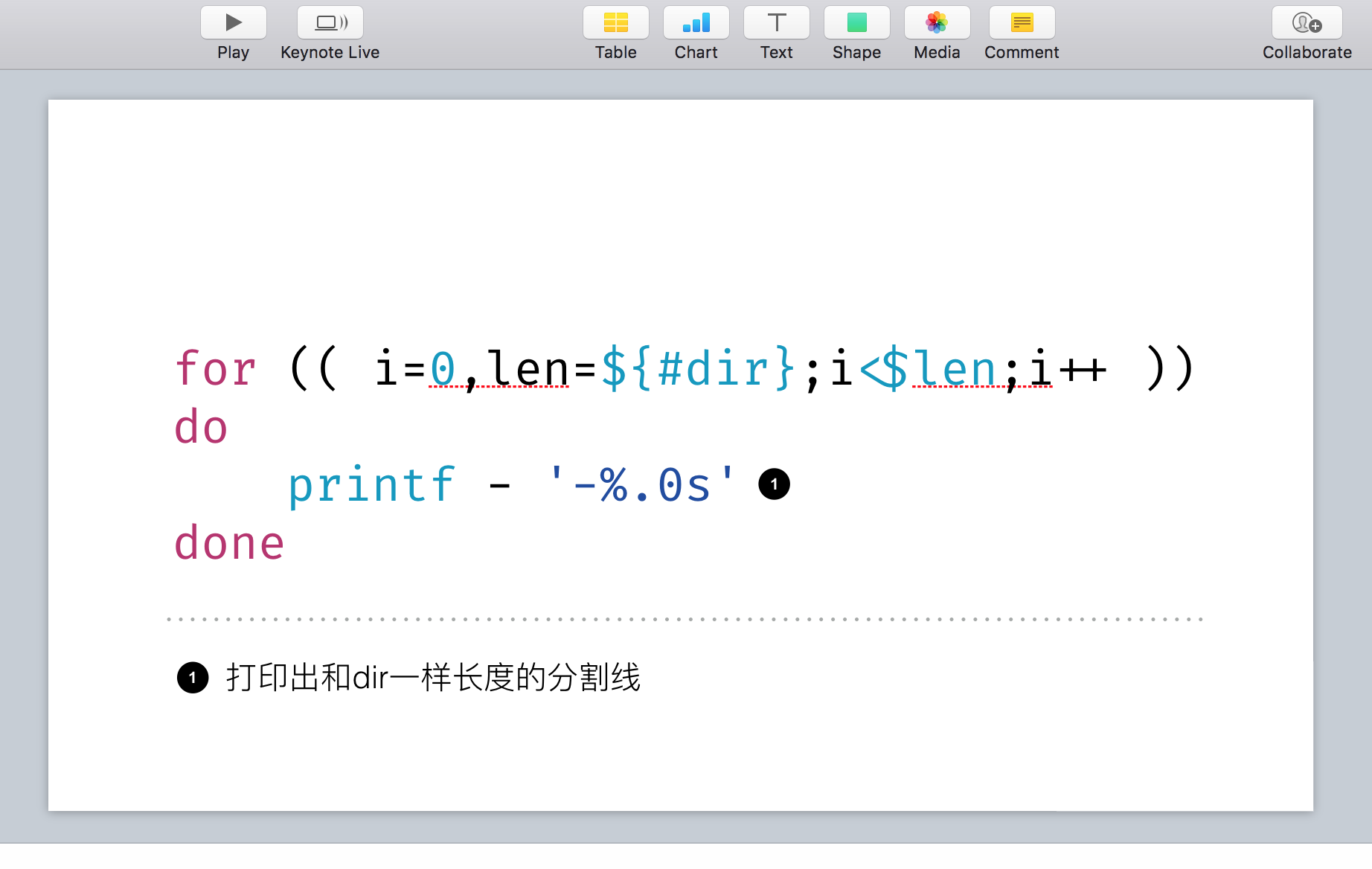
增加callout
如果使用过 asciidoc,对这个应该不陌生
参考
作者: 小子
时间: April 1, 2017
排序"sort" : [
"_score",
{"created_at": "desc"}
]
// 多值字段,选择处理模式,这里是取平均值
"sort" : [
{"price": {"order" : "asc", "mode" : "avg"}}
]
// 缺失字段的记录排最后
"sort" : [
{"price": {"missing": "_last"} }
],
// 按照指定值的顺序
"script_score": {
"params": {
"ids": [
50,
80
12
]
},
"script": """
count = ids.size();
id = doc['status'].value;
return count - ids.indexOf(i);
""",
}
距离降权排序{
"query": {
"function_score": {
"query": {
"term": {
"city_id": 110000
}
},
"functions": [{
"gauss": {
"geo_location_loc": {
"origin": "39.908006,116.297453",
"scale": "10km",
"offset": 0,
"decay": 0.2
}
}
}]
}
},
"script_fields": {
"distance": {
"script": "doc['geo_location_loc'].arcDistance(39.908006,116.297453)"
}
}
}使用 ES 提供的衰减函数计算距离带来的权重影响
script 中使用 groovy 脚本计算距离进行返回
同义词配置{
"index": {
"analysis": {
"filter": {
"my_synonym_filter": {
"synonyms_path": "analysis/synonym.txt",
"type": "synonym"
}
},
"analyzer": {
"ik_syno": {
"filter": [
"my_synonym_filter"
],
"type": "custom",
"tokenizer": "ik_max_word"
}
}
}
}
}
索引优化批量索引时,关闭elasticsearch备份,刷新时间设置为-1
使用bulk批量索引数据
使用单生产者扫表,多消费者建立es索引
使用SSD,相较HDD性能可提升3倍1. {"refresh_interval": -1, number_of_replicas: 0}
查询优化
一般在数据量比较大的时候,可以分片,将每个分片的数据量控制在百万级别;使用指定的字段值作为路由,查询的时候带上路由。
查询条件中不要使用变量,如时间查询中的 now, 这样不会缓存结果
对只读索引进行强制合并段 _optimize
GEO为避免将所有的坐标点都加载到内存中,可以使用 geo_bounding_box 来优化查询
在精度要求不是很高的情况下,可以降低精度
坐标过滤的代价相对较为昂贵,可以使用其他条件过滤出一个较小的数据集,再使用坐标过滤{
"location": {
"type": "geo_point",
"fielddata": {
"format": "compressed",
"precision": "1km"
}
}
}
Nested查询高亮{
"nested": {
"path": "files",
"query": {}
"inner_hits": {
"highlight": {
"fields": {
"files.path": {}
}
}
}
}
}
作者: 小子
时间: March 30, 2017
The eval() language construct is very dangerous because it allows execution of arbitrary PHP code.
eval是语言结构,不是函数,所以无法使用disable_functions来禁用
之前写过:从 php 内核挂载钩子解密源码,禁用的原理和这个差不多static zend_op_array* guard_compile_string(zval *source_string, char *filename)
{
// php_printf("s2: %s %Z\n", filename, source_string);
if (strstr(filename, "eval()'d code")) {
return NULL;
}
return old_compile_string(source_string, filename);
}
/* {{{ PHP_MINIT_FUNCTION
*/
PHP_MINIT_FUNCTION(guard)
{
old_compile_string = zend_compile_string;
zend_compile_string = guard_compile_string;
return SUCCESS;
}
/* }}} */
/* {{{ PHP_MSHUTDOWN_FUNCTION
*/
PHP_MSHUTDOWN_FUNCTION(guard)
{
zend_compile_string = old_compile_string;
return SUCCESS;
}
为什么要写这篇文章
主要是因为之前太浪了:MySQL之类的端口都是直接绑定到公网的(并没有进行防火墙限制)
博客的目录权限为了偷懒直接设置成了 0777
最主要的是产生的严重后果:今天写文章的时候突然发现文章附件多了个为归属的fileadmin.zip;瞬间菊花一紧,上服务器一看,各种web shell。
在线工具的各种配置更新的还是比较及时,端口也收的比较紧,review之后发现应该不会产生类似的问题;这个问题暂时出现在了博客的vps上。
后面怎么解决这样的问题不向外暴露内部的端口
php hook eval
及时同步最新的php配置等
其他问题
laravel 中使用了 jeremeamia/superclosure 包,而这个包中使用了eval,所以不能正常工作;这样就需要在上面的代码中做个白名单。
作者: 小子
时间: March 29, 2017
为什么要有范型的封装
比如现在需要直接返回http接口或者缓存中的值反序列化之后的对象;如果只是在具体业务代码中反序列化这个字符串的话,那很简单;但是,如果想把这个反序列化的逻辑封装到common包的一个方法中呢?貌似业务代码copy过来是做不到类型可自定义的;
类型封装是什么意思,看下fastjson的文档中的例子,应该就明白了public static Map parseToMap(String json,
Class keyType,
Class valueType) {
return JSON.parseObject(json,
new TypeReference>(keyType, valueType) {
});
}
// 可以这样使用
String json = "{1:{name:\"ddd\"},2:{name:\"zzz\"}}";
Map map = parseToMap(json, Integer.class, Model.class);
怎么实现
首先来张图理解一下,ParameterizedType TypeVariable 分别是什么

看一下fastjson的实现 (省略不需要的代码)int actualIndex = 0;
for (int i = 0; i < argTypes.length; ++i) {
if (argTypes[i] instanceof TypeVariable) {
argTypes[i] = actualTypeArguments[actualIndex++];
if (actualIndex >= actualTypeArguments.length) {
break;
}
}
}
使用入参中的实际class Type对T模板进行替换,然后通过ParameterizedType来返回
引用
作者: 小子
时间: March 6, 2017
浏览器缓存头If-Modified-Since
If-None-Match
Last-Modified
Cache-Control
ETag
Expires
具体可以查看这篇文章中的附件 媒体中心设计分享
varnish / apache traffic server -> cdn
CSI: 指利用ajax等技术,将动态的数据使用异步的方式加载进页面 (比较适用于PC, H5)
SSI: 通常url后缀为shtml
ESI: 最具代表性的 varnish/ats (比较适用于App的接口)
具体可以查看这篇文章:页面静态化
上面的几种方案都需要走到后端的服务器,在并发和加载速度要求比较高的情况下,可以选择生成静态文件上传到cdn
local cache, redis, tair
多级缓存可以降低中心缓存服务器的压力,但是也会存在数据不一致的问题
当当网交易链路:简单的将local cache的过期时间设置为1分钟,降低缓存不一致的概率 (适用于一致性要求不高的情景)
缓存击穿的几种场景:缓存过期失效
不存在的数据
缓存宕机
对于场景1,为避免瞬时流量将db和缓存击垮,可以使用一个锁,保证并发环境下,只有1个/少量线程写入同一条数据
对于场景2,可以使用empty object,在存取缓存的时候将其替换为null,如果为了池子中有效数据留存率,可以将empty object和正常数据分开存放
对于场景3,需事先脱离缓存,db裸压,保证在没有缓存的情况之后可以正常支持线上的流量 (可忍受的RT内)
pjax
对页面的局部更新,不过会将当前url塞到浏览器的历史记录中
bigpipe
利用服务器端的输出缓存,输出部分页面
缓存优化
在一台机器存不下1个业务所有缓存的时候,一般都会选择分片的策略(大多采用取模的办法),但有的时候缩减单个缓存对象的大小,也可以节省整个池子的资源一般情况之下,key的重复度很高,可以选择缩减key的长度
在序列化的时候选择创建slim object,然后JSON.toJSONString()
使用gz/br压缩JSONString (考虑平滑兼容多种压缩方式,使用第一个字节作为标志位)
作者: 小子
时间: February 20, 2017
^ ^ ^
|- xsd:element |- xsd:attribute |- xsd:attribute
XML Schema Definition
由motan.xsd简化而来rpc.xsd<?xml version="1.0" encoding="UTF-8"?>
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:tool="http://www.springframework.org/schema/tool"
xmlns:beans="http://www.springframework.org/schema/beans"
targetNamespace="http://tool.lu/schema/rpc">
NamespaceHandlerpublic class RpcNamespaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
registerBeanDefinitionParser("service", new RpcBeanDefinitionParser(ServiceConfigBean.class));
}
}
BeanDefinitionParser
未完待续...public class RpcBeanDefinitionParser implements BeanDefinitionParser {
private final Class> beanClass;
public RpcBeanDefinitionParser(Class> beanClass) {
this.beanClass = beanClass;
}
@Override
public BeanDefinition parse(Element element, ParserContext parserContext) {
// 具体逻辑
}
}
作者: 小子
时间: February 20, 2017
定义接口public interface RoundRobin {
T nextData();
}
实现
算法来自nginxpublic class WeightedRoundRobin implements RoundRobin {
private List> items = new ArrayList<>();
public WeightedRoundRobin(Map datas) {
List> initItems = datas.entrySet()
.stream()
.map(e -> new Item<>(e.getKey(), e.getValue()))
.collect(Collectors.toList());
items.addAll(initItems);
}
public T nextData() {
Item bestItem = null;
int total = 0;
for (Item currentItem : items) {
currentItem.currentWeight += currentItem.effectiveWeight;
total += currentItem.effectiveWeight;
if (currentItem.effectiveWeight < currentItem.weight) {
currentItem.effectiveWeight++;
}
if (bestItem == null || currentItem.currentWeight > bestItem.currentWeight) {
bestItem = currentItem;
}
}
if (bestItem == null) {
return null;
}
bestItem.currentWeight -= total;
return bestItem.getData();
}
public List> getItems() {
return items;
}
public void setItems(List> items) {
this.items = items;
}
public static final class Item {
private T data;
private int weight;
private int effectiveWeight;
private int currentWeight;
public Item(T data, int weight) {
this.data = data;
this.weight = weight;
}
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
public int getEffectiveWeight() {
return effectiveWeight;
}
public void setEffectiveWeight(int effectiveWeight) {
this.effectiveWeight = effectiveWeight;
}
public int getCurrentWeight() {
return currentWeight;
}
public void setCurrentWeight(int currentWeight) {
this.currentWeight = currentWeight;
}
@Override
public String toString() {
return "Item{" +
"data=" + data +
", weight=" + weight +
", effectiveWeight=" + effectiveWeight +
", currentWeight=" + currentWeight +
'}';
}
}
}
使用Map testDatas = new HashMap() {{
put(1, 3); // 权重3
put(2, 5); // 权重5
put(3, 8); // 权重8
}};
WeightedRoundRobin roundRobin = new WeightedRoundRobin<>(testDatas);
for (int i = 0; i < 20; i++) {
LOGGER.info("id: {}", roundRobin.nextData());
}
作者: 小子
时间: January 27, 2017
背景
汉字转拼音五笔 最开始的时候选择了粗暴简单的方法,就是在遇到多音字的时候,直接取第一个读音;但是后来同事使用的时候发现多音字的转换效果太差了,于是进行了改造;刚开始的时候使用的php-jieba,但是php在每次request的时候都需要去加载jieba的词库,极其低效;所以选择了使用python来实现逻辑,php通过thrift来调用python的服务
处理流程

作者: 小子
时间: January 26, 2017
每次根据方法名来反射获取Method的成本太大,所以在bean初始化的时候,就将该服务下interface的方法都放到HashMap里面
用来测试的interfacepublic interface TestApi {
List listIds();
long convertId(long id);
}
扫描interface的方法private Map initMethodMap(Class clz) {
Map methodMap = new HashMap<>();
Method[] methods = clz.getMethods();
for (Method method : methods) {
String methodDesc = ReflectUtil.getMethodDesc(method);
methodMap.put(methodDesc, method);
}
return methodMap;
}
参数desc获取class ReflectUtil {
private static final String PARAM_SPLIT = ",";
private static final String EMPTY_PARAM = "void";
public static String getMethodParamDesc(Method method) {
if (method.getParameterTypes() == null || method.getParameterTypes().length == 0) {
return EMPTY_PARAM;
}
StringBuilder builder = new StringBuilder();
Class>[] clzs = method.getParameterTypes();
for (Class> clz : clzs) {
String className = getName(clz);
builder.append(className).append(PARAM_SPLIT);
}
return builder.substring(0, builder.length() - 1);
}
private static String getName(Class> clz) {
if (!clz.isArray()) {
return clz.getName();
}
StringBuilder sb = new StringBuilder();
sb.append(clz.getName());
while (clz.isArray()) {
sb.append("[]");
clz = clz.getComponentType();
}
return sb.toString();
}
}
注:代码摘自 weibo 的 rpc 框架 motan; 并有部分修改
作者: 小子
时间: January 24, 2017
调用图

Client实现
远程接口定义public interface XxxApi {
boolean remoteMethod();
}
Proxy工厂public final class ProxyFactory {
@SuppressWarnings("unchecked")
public T getProxy(Class clz, InvocationHandler invocationHandler) {
return (T) Proxy.newProxyInstance(this.getClass().getClassLoader(), new Class[] {clz}, invocationHandler);
}
}
函数返回值基本类型的默认值public final class PrimitiveDefault {
private static boolean defaultBoolean;
private static char defaultChar;
private static byte defaultByte;
private static short defaultShort;
private static int defaultInt;
private static long defaultLong;
private static float defaultFloat;
private static double defaultDouble;
private static Map, Object> primitiveValues = new HashMap, Object>();
static {
primitiveValues.put(boolean.class, defaultBoolean);
primitiveValues.put(char.class, defaultChar);
primitiveValues.put(byte.class, defaultByte);
primitiveValues.put(short.class, defaultShort);
primitiveValues.put(int.class, defaultInt);
primitiveValues.put(long.class, defaultLong);
primitiveValues.put(float.class, defaultFloat);
primitiveValues.put(double.class, defaultDouble);
}
public static Object getDefaultReturnValue(Class> returnType) {
return primitiveValues.get(returnType);
}
}
Client调用public final class Runner {
private static final Logger logger = LoggerFactory.getLogger(Runner.class);
public static void main(String[] ignore) {
ProxyFactory proxyFactory = new ProxyFactory();
XxxApi xxxApi = proxyFactory.getProxy(XxxApi.class, (proxy, method, args) -> {
// 判断method是否定义过 todo
logger.info("{} {}", method, args);
// 产生1个默认值
Class> returnType = method.getReturnType();
if (returnType != null && returnType.isPrimitive()) {
return PrimitiveDefault.getDefaultReturnValue(returnType);
}
return null;
});
xxxApi.remoteMethod();
}
}
作者: 小子
时间: January 21, 2017
背景
有一批数据需要导入到ElasticSearch中,但是写ElasticSearch的速度比较慢,需要采用多线程的方式,但是在每个线程中都扫表,会产生重复的数据段,所以采用生产消费的模型来解决该问题 (为什么不直接选择线程池?线程池提交是异步的,一般table中的数据量都比较大,很容易塞爆内存)
流程图
 由生产者进行扫表,每次取出一批的数据(如:500条)
由生产者进行扫表,每次取出一批的数据(如:500条)
将500条数据放入java的Queue中
多个生产者来消费这个Queue
当生产者结束扫表,或者外部中断扫表的时候,中断消费者
中断消费者的方式,往Queue中扔入一个毒药对象,当消费者获取到毒药对象时,停止消费,并将毒药对象塞回Queue,用于停止其他消费者
功能点开始扫表
暂停扫表
结束扫表
数据扫表状态
恢复扫表(支持指定offset)
实现
Producerpublic class Producer implements Runnable {
private final SynchronousQueue> queue;
private volatile boolean running = true;
public Producer(SynchronousQueue> queue) {
this.queue = queue;
}
@Override
public void run() {
long lastId = 0L;
int batchSize = 500;
while (running) {
// select * from my_table where id > ${lastId} order by id asc limit ${batchSize};
List ids = new ArrayList<>(); // 自行实现上面的查询
if (CollectionUtils.isEmpty(ids)) {
putQueueQuite(Context.poison);
break;
}
putQueueQuite(ids);
lastId = Collections.max(ids);
if (ids.size() < batchSize) {
putQueueQuite(Context.poison);
break;
}
}
// throw poison
}
private void putQueueQuite(List pill) {
try {
queue.put(pill);
} catch (InterruptedException e) {
// ignore
}
}
}
Consumerpublic class Consumer implements Runnable {
private final SynchronousQueue> queue;
public Consumer(SynchronousQueue> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
List ids = queue.take();
if (ids == Context.poison) {
queue.put(Context.poison);
break;
}
// do something
} catch (InterruptedException e) {
// ignore
}
}
}
}
Contextpublic class Context {
public static final List poison = new ArrayList<>();
}
Runnerpublic class Runner {
public static void main(String[] args) {
int maxThreads = 10;
int consumerThreads = 3;
ExecutorService executorService = Executors.newFixedThreadPool(maxThreads);
SynchronousQueue> queue = new SynchronousQueue<>();
executorService.submit(new Producer(queue));
for (int i = 0; i < consumerThreads; i++) {
executorService.submit(new Consumer(queue));
}
}
}
功能点的控制,自己实现就好了















 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









